【python】gensimモジュールで分散表現を獲得・保存・読み込む方法を丁寧に
はじめに
本記事では,gensimモジュールを用いてWord2Vecで分散表現を獲得・保存・読み込む方法を紹介します.
公式リファレンス:
目次
分散表現の学習
ここでは生データから分散表現を学習する方法を説明します.具体的には,gensim.models.word2vec.Word2Vec()の関数を用います.入力のデータ構造は単語リストのリストです.
from gensim.models import word2vec sample_sents = [['this', 'is', 'a', 'first', 'sentence', '.'], ['this', 'is', 'a', 'second', 'sentence', '.']] model = word2vec.Word2Vec(sentences=sample_sents, size=100, window=5, min_count=1)
実行すると,modelに学習結果が格納されます.これは<class 'gensim.models.word2vec.Word2Vec'>というオブジェクトです.
各種オプション
word2vec.Word2Vec()でよく使われるオプションを紹介します.
公式リファレンス:https://radimrehurek.com/gensim/models/word2vec.html#gensim.models.word2vec.Word2Vec
| オプション | 説明 | デフォルト |
|---|---|---|
| sentences= | 元となるコーパス.単語リストのリスト. | |
| courpus_file= | コーパスをファイル読み込みする場合に指定.1行1文の形式で,単語は空白区切りで認識される. | |
| size= | 分散表現の次元.リファレンスではvector_sizeと書いてあるように見えるが,sizeでないと動かない. | 100 |
| windows= | 学習時に利用される文脈の広さ. | 5 |
| min_count= | 分散表現を獲得する単語の最小頻度.1なら全ての単語について獲得される. | 5 |
| workers= | 学習時の使用スレッド数. | 3 |
| sg= | 学習アルゴリズムの選択.1ならskip-gram,0ならCBOW. | 0 |
学習済み分散表現の機能
<class 'gensim.models.word2vec.Word2Vec'>の機能を簡単に説明します.ここでは,以下のコードで獲得した分散表現を用いた例を示します.(本来はsizeを100~300程度にすべきですし,文をもっと増やすべきです.)
from gensim.models import word2vec sample_sents = [['this', 'is', 'a', 'first', 'sentence', '.'], ['this', 'is', 'a', 'second', 'sentence', '.']] model = word2vec.Word2Vec(sentences=sample_sents, size=3, window=5, min_count=1)
- ある単語の分散表現を得る.
.wvはWord2VecKeyedVectorsというオブジェクトで,単語をキー,分散表現を値に持つ辞書のように扱えます.
print(model.wv['this']) # [ 0.12677142 -0.07538117 -0.13080813]
- 2つの単語の類似度を得る.
print(model.similarity('first', 'second')) # -0.7543343
- ある単語と類似している単語を上位
件得る.返り値は
(単語, 類似度)のリスト.
n = 5 print(model.most_similar('this', topn=n)) [('is', 0.8868916034698486), ('second', 0.8849490880966187), ('sentence', 0.6720788478851318), ('first', 0.5845127105712891), ('.', 0.3697856068611145)]
- 単語ベクトルの足し引き.
王 - 男 + 女 = 女王 みたいなやつ.positive=に正の項の単語を,negative=に負の項の単語を指定する.topn=で上位
print(model.most_similar(positive=['this', 'first'], negative=['second'], topn=1)) # [('is', 0.15704883635044098)] # this - second + firstということ # 王の例だと # most_similar(positive=['king', 'woman'], negative=['man']) のように書ける.
分散表現の保存
学習した分散表現は,.wv.save_word2vec_format(保存ファイルパス)で保存できます.
from gensim.models import word2vec from gensim.models import KeyedVectors sample_sents = [['this', 'is', 'a', 'first', 'sentence', '.'], ['this', 'is', 'a', 'second', 'sentence', '.']] model = word2vec.Word2Vec(sample_sents, size=3, window=5, min_count=1) model.wv.save_word2vec_format('sample_word2vec.txt')
保存結果は以下のようになります.1行目には単語数と分散表現の次元が,2行目以降は分散表現が並んでおり,1行1単語に相当します.
7 3 this 0.12709168 -0.11746123 -0.1590661 is -0.10325706 0.14546975 -0.10878078 a 0.0123018725 0.104428194 -0.069693 sentence 0.16237356 -0.07644377 0.16515312 . 0.09359499 0.12543988 -0.01799449 first -0.019889886 -0.077862106 0.13868278 second 0.060134348 0.029044067 0.03352099
一般には,容量が削減できることから,binary=Trueとしてバイナリファイルで保存・公開されることが多いと思います.
model.wv.save_word2vec_format('sample_word2vec.bin', binary=True)
分散表現の読み込み
.wv.save_word2vec_format()で保存された分散表現は,KeyedVectors.load_word2vec_format(ファイルパス)で読み込めます.
from gensim.models import KeyedVectors model = KeyedVectors.load_word2vec_format('sample_word2vec.txt') print(model.wv['this']) # [ 0.12677142 -0.07538117 -0.13080813]
バイナリファイルを読み込む場合は,保存のときと同様binary=Trueを指定します.
from gensim.models import KeyedVectors model = KeyedVectors.load_word2vec_format('sample_word2vec.bin', binary=True)
例えば,学習済みの分散表現として代表的なGoogleNews-vectors-negative300はバイナリファイルで保存されているので,binary=Trueとして読み込みます.
おわりに
今回はgensimモジュールを用いてWord2Vecで分散表現を獲得・保存・読み込む方法を紹介しました.
【Processing】シグモイド関数でイージングを実装する
はじめに
本記事では,Processingによるアート制作において,シグモイド関数を使ってイージングを実装する方法を紹介します.非常にお手軽にイージングを実装できるので,ぜひ使ってみてください.
シグモイド関数とは
で表される関数で,グラフに書くと以下のようになります.はネイピア数で,2.718...です.

desmosでの描画結果:https://www.desmos.com/calculator/64rtnb5z5i
定義域は無限で,値域がであるような関数です.ニューラルネットの活性化関数としてよく登場しますが,グラフの形からイージングに使えそうなことが分かります.
イージングのために使うことを考えると,-5でほぼ0(厳密には,とすると
),5でほぼ1(厳密には,
とすると
)となることは知っておくと良いと思います.
最も簡単な適用例
ここでは,円を左から右に移動するような動きに,シグモイド関数を使ってイージングをかけます.ひとまず,テンプレ+シグモイド関数がこちら.ネイピア数は2.718としています.
void setup(){ size(500,500); } void draw(){ background(0); } float sigmoid(float x){ return 1/(1+pow(2.718, -x)); }
ここから,円を移動させることを考えます.今回は,60フレームかけて左端から右端へと移動させることにしましょう.ひとまず,コードは以下のとおりです.
void setup(){ size(500,500); } void draw(){ background(0); float sig_x = map(frameCount%60, 0, 59, -5, 5); float cir_x = map(sigmoid(sig_x), 0, 1, 0, width); circle(cir_x, height/2, 20); } float sigmoid(float x){ return 1/(1+pow(2.718, -x)); }
sig_xは,シグモイド関数への入力です.フレーム数を60で割った余りは0から59なので,それをmap()を使って-5から5への範囲に変換します.なぜ-5から5にしたかというと,前述したとおり,シグモイド関数は-5でほぼ0,5でほぼ1をとる関数だからです.cir_xは,円のx座標です.シグモイド関数は0から1の値を返すので,それをmap()を使って0からwidthに変換します.
実行例は以下のようになります.

始点と終点の近傍では遅く,その中間では速くなるような動きが実現できています.
イージングの調整
上記の例では,シグモイド関数に-5から5への範囲を入力しましたが,この範囲を調整することで,機敏のあるイージングができるようになります.
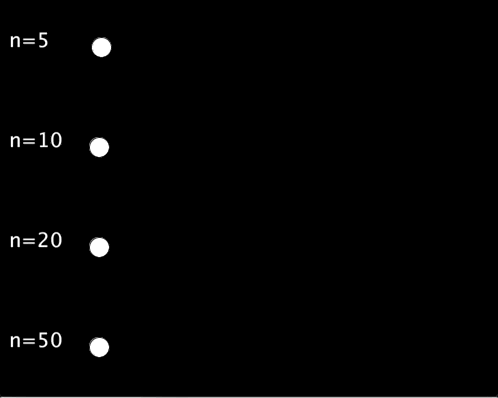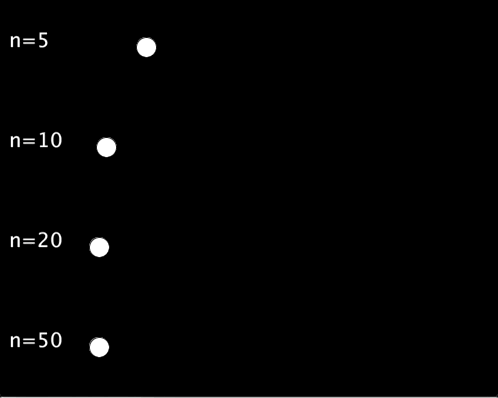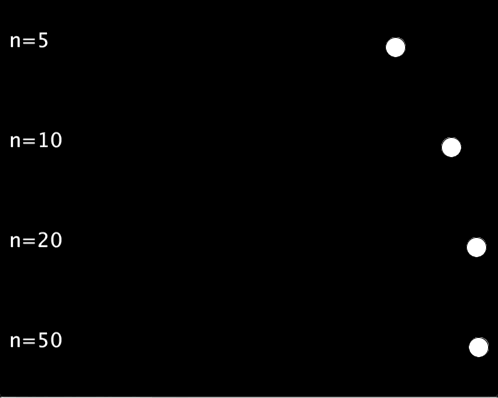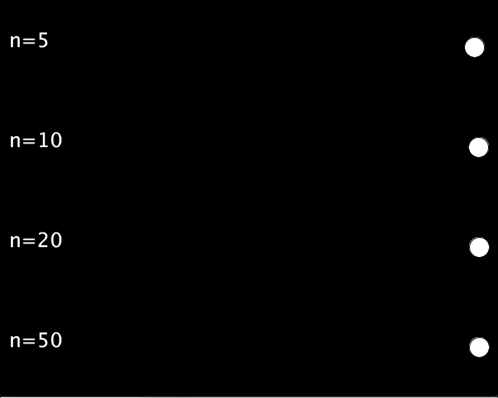
以下の例では,,シグモイド関数の入力として-5 ~ 5, -10 ~ 10, -20 ~ 20, -50 ~ 50の4種類を試しています.
void setup(){ size(500,400); textSize(20); } void draw(){ background(0); int n[] = {5, 10, 20, 50}; // 範囲の候補 for(int i=0;i<4;i++){ text("n="+n[i], 10, 50+100*i); float sig_x = map(frameCount%60, 0, 59, -n[i], n[i]); float cir_x = map(sigmoid(sig_x), 0, 1, 100, width-20); circle(cir_x, 50+100*i, 20); } } float sigmoid(float x){ return 1/(1+pow(2.718, -x)); }
実行結果は以下のようになります.入力の範囲を広くすればするほど,待ち時間が長く,動き始めれば一瞬で移動するような動きになります.
その他の適用例
イージングは様々な場面に適用できます.これまでに紹介した円の例では座標の動きにイージングをかけていますが,他の動きに適用する例を示します.
回転にイージング
シグモイド関数の返り値を
に変換して角度に使用してみます.
void setup(){ size(500,200); rectMode(CENTER); textSize(20); } void draw(){ background(0); int n[] = {5, 10, 20, 50}; for(int i=0;i<4;i++){ text("n="+n[i], 45+110*i, 130); float sig_x = map(frameCount%60, 0, 59, -n[i], n[i]); float rad = map(sigmoid(sig_x), 0, 1, 0, PI/2); translate(50+120*i, 50); rotate(rad); rect(0, 0, 50, 50); resetMatrix(); } } float sigmoid(float x){ return 1/(1+pow(2.718, -x)); }
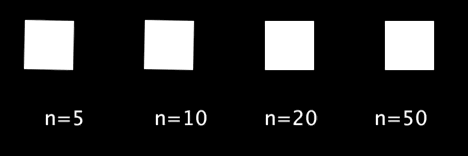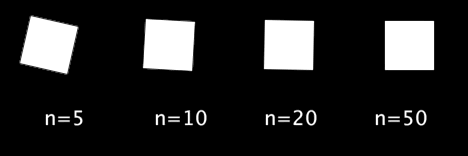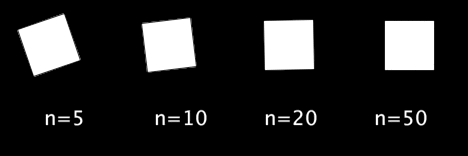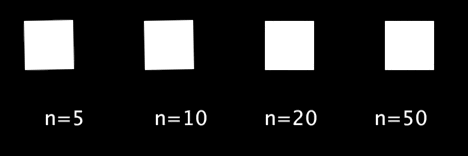
図形の大きさにイージング
シグモイド関数の返り値を
に変換し,正方形の一辺の長さに使用します.
void setup(){ size(500,200); rectMode(CENTER); noFill(); stroke(255); strokeWeight(5); textSize(20); } void draw(){ background(0); int n[] = {5, 10, 20, 50}; for(int i=0;i<4;i++){ text("n="+n[i], 30+110*i, 130); float sig_x = map(frameCount%60, 0, 59, -n[i], n[i]); float leng = map(sigmoid(sig_x), 0, 1, 0, 50); rect(50+110*i, 50, leng, leng); } } float sigmoid(float x){ return 1/(1+pow(2.718, -x)); }
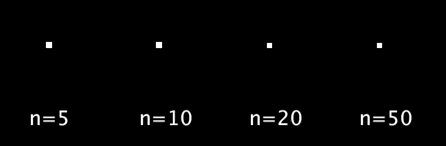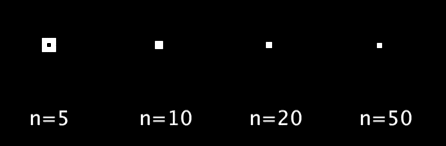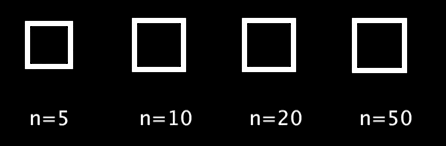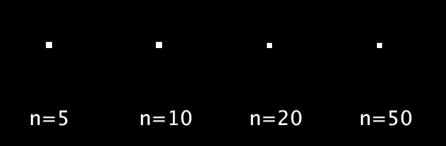
おわりに
本記事では,イージングをシグモイド関数で実装する方法を紹介しました.
2020年振り返り
昨年の自分も書いてましたんで(以下リンク),今年の自分も今年やったこと,成し遂げたことを書こうと思います(僕の好きな食べ物の一つはイカリング).
- 言語処理学会2020に参加した
- COLING2020に参加した
- IVRC2020で企画がSEED STAGEまで進んだ
- Processing関係の活動をした
- NAISTに合格した
- ブログ執筆した
- おわりに
言語処理学会2020に参加した
言語処理学会2020に参加し,一件のポスター発表を行いました.
訂正難易度を考慮した文法誤り訂正のための性能評価尺度
○五藤巧 (甲南大), 永田亮 (甲南大/理研), 三田雅人, 塙一晃 (理研)
文法誤り訂正というタスクにおける評価尺度を提案した論文です.このタスクで扱われる誤りには様々な難易度のものが混在しているにもかかわらず,従来の評価尺度ではそれらを一律に扱っていることを問題として提起し,難易度を考慮して性能評価を行う方法を提案しています.
あいにくオンラインでの開催となりましたが,オンラインでもたくさんの方に訪問いただいて,質問をしていただきました.学会の場で発表するのはこれが初めての経験となりました.
COLING2020に参加した
言語処理関係のメジャーな国際会議の一つであるCOLING2020に参加し,一件のポスター発表を行いました.初めての国際会議への参加&発表となりました.
Takumi Gotou, Ryo Nagata, Masato Mita and Kazuaki Hanawa Taking the Correction Difficulty into Account in Grammatical Error Correction Evaluation
内容は言語処理学会2020と同じようなものですが,評価の際に起こる ある問題を解決するための方法を追記し,考察を深めたような形になります.発表は当然英語で,スピーキングとリスニングが問われるのでやはり大変でした.一方で,特に日本人が興味を持つテーマだったこともあり,日本語でやり取りすることも多かったので助かりました.(助かりました,じゃないんだぞ,英語力を鍛えろ)
どのような準備をしたかについて少し書きます.基本的に,あらゆる発表機会について原稿は作らない主義ですが,今回ばかりは一応原稿は作りました.試しにグーグル翻訳の音声入力に向かって原稿を読み上げると半分くらい全然違う単語に認識されたので,正しく認識されるように発音の練習をしていました(この練習に意味があるかはよく分からない).ポスターについては,言語処理学会のポスターを英語に翻訳し,少し構造や文言を変えるようなことをしました.
また,今回の研究で非常にお世話になっているERRANTというツールがあるのですが,そのツールの作者(でありERRANTの論文の著者)の方とも顔を合わせることができました.これは非常に嬉しかったです.
本研究ではツールの公開もしています.
IVRC2020で企画がSEED STAGEまで進んだ
IVRCはVR技術を活用した様々な試みが集うコンテストです(今年度はコンテストではなくチャレンジだ,という声明が出ていますので,この説明は誤りかもしれません).IVRC2020では,投稿された企画が書類審査→SEED STAGE→LEAP STAGE(決勝)と進んでいきます.
弊学でも企画を投稿しており,見事に書類審査を突破,SEED STAGEへ進みました.僕は実装には一切関わっておらず,原案部分で若干のサーベイをした程度なので本当に関わっていないのですが(その証拠に,原稿ではLast Authorですし(Last Authorなんて言い回しあるのか?)),こうして成果が認められたことは嬉しいです.
Processing関係の活動をした
Processingという言語を使うと,四角や円などの図形をプログラムで描くことができます.これを利用して,アート作品を制作する営みが近年盛んになっています.Twitterでは「#つぶやきProcessing」や「#creativecoding」などのハッシュタグでたくさんの作品が公開されています.個人的にもいくつか作っていて,基本的にGitHubやTwitterで公開しています.本記事の執筆時点でStarが13もついているので,それなりに見られている気がします.
また,PCJ ZINEという有志で作る雑誌のようなものにも寄稿させていただきました.Processingがオアシス的存在であることを熱弁しています.このZINEの発行について,関係者の皆様に感謝申し上げます.
それから,Processing Advent Calender 2020の初日として記事を投稿しました.この記事内でも同じような振り返りをしています.
NAISTに合格した
NAISTに合格しました.(以下ポエム)この面接は2020年で一番緊張した.学会よりも.そりゃそうだ,学会でヘマしても人生は変わらないが,面接でヘマると人生変わるのでな.でも僕はなぜか受かるだろうという気持ちで臨んだ.それは今思えば,かつて高校入試で落ちた時と同じ気持ちだった.あの時はなぜ俺が落ちたのか分からなかった.でも今度は受かった.僕にとって初めての第一希望への合格という成果だった.
もっと長いポエムが書けそうなので,また別の機会に自分語りをすることにします.
これに関しては受験期を書いています.
ブログ執筆した
本ブログでは,今年は32本の記事を書きました.この記事を入れると33本です.大した内容は書いていませんが,Processing関係ではゲーム制作講座とか,機械学習・深層学習関係ではツールの紹介をメインで書いたように思います.最近徐々にアクセスも増えている(300アクセス/日くらいですけども)ので,ある程度の需要があるのかなーと思っています.来年も何かしら書いていきます.
おわりに
他にもいろいろあった気がしますが,大きな出来事はこんな感じでした.小さなところでは,ポケモンパンのシールホルダーを買えたこと,小学生の頃乗れた自転車が大学4年で乗れなくなっていたが再びちゃんと乗れるようになったこと,コロナをきっかけに育て始めたサボテンが順調に育っていること,Apple Watchが手に入ったこと,などいろいろありました.
来年も,何かしらの成果を上げられるよう,どこかに貢献できるよう,頑張りたいと思います.また来年,2021年振り返りで書くことがありますように...
良いお年を.
アートを切り替えて不思議に魅せる技法について(Processing Advent Calendar 2020 Day1)
本記事は,Processing Advent Calendar 2020の1日目の記事です.10周年だそうで,おめでとうございます!
目次
2020振り返り・Processingコミュニティについて
せっかくのアドカレの記事なので,簡単な振り返り(という名の過去作の宣伝)と,コミュニティ関係の話を少しだけ書きます.
今年もアート制作という形でProcessingにたくさん触れました.今年は20個ほど作品を作っていて,今までの分と合わせてGitHubで公開しています.GitHubにはそれなりに厳選して載せているので,つぶやきProcessingなどの作品も含めるともっと作ったように思います.
また,コミュニティとの関わりという点では,PCJ ZINEのVol.0に寄稿させていただきました.Processingがオアシス的存在であることを熱弁しております.このZINEの発行について,関係者の皆様に感謝申し上げます.
このように,今年は無理なく作品制作もできたし,少しだけコミュニティにも関わることができたしで,非常に楽しいProcessingライフでした.(まだ12月に入ったばかりで気が早いかもしれませんが,)来年も楽しみたいですね.
はじめに
さて,本記事では,「アートを適切なタイミングで切り替えて不思議な感じにする技法」について書きます.イメージとしては,次のようなものです(両方自作です).


うまくやっているものほど見ていて不思議な気持ちになれるので,個人的に好きなパターンの一つです.本記事では,言語としてProcessingを用いて,実装をメインに紹介します.
雛形
全体の構造はこんな感じです.以下では,2種類のアートを90フレーム単位で切り替えます.
void setup(){} void draw(){ if(timeCount%180 < 90) アート1(); else アート2(); }
timeCountはProcessingのシステム変数で,開始時点からのフレーム数を取得できます.また,アート1とアート2は周期性のあるアートを描画する関数で,両者がどこかで同じ絵柄を持つように作ります.あまり抽象化していませんが,上の例だと90フレームごとに切り替わることになるのです.
簡単な実例で!
市松模様で作るアート
では,簡単な実例で詳細を見てみましょう.以下のような,白黒タイルが回転するものを作ります.白と黒は市松模様のように配置します.

まず,雛形を作ります.
void setup(){ size(500,500); } void draw(){ if(frameCount%180 < 90)art1(); else art2(); } void art1(){ } void art2(){ }
この例では,「黒のタイルが回転するアート」と,「白のタイルが回転するアート」が切り替わることになります.この2つをそれぞれart1()とart2()に書くわけです.今回は,黒タイル側をart1()に,白タイル側をart2()に書くことにします.
前準備
パラメータの準備だけサクッとしましょう.一行/一列に並べるタイルの数をNで表して,タイル一辺の長さをwidth/Nで計算します.それから,回転させる都合上,rectMode(CENTER)を設定します.
int N=10, len; void setup(){ size(500,500); rectMode(CENTER); len = width/N; }
「黒タイル側」の実装
黒側は,背景を白にして,黒の四角を描画します.市松模様に並べるためには,四角を横にも縦にも一個飛ばしで並べる必要がありますが,これは変数i,jの2重ループを回すとすれば,i+jの偶奇に注目すると簡単に実装できます.黒は奇数のときに書くことにしましょう.
また,四角を回転させて描画する処理は,
座標軸の原点を,
translate()で四角の中心に持ってくる座標軸を,
rotate()で回す原点に四角を
rect()で描画する座標軸を
resetMatrix()で元に戻す
という4ステップで実装できるため,これを全ての四角について行います.
回す角度については,frameCountをラジアンに変換する必要があります.今回はmap()を使って,[0,89]の範囲を[0,PI/2]の範囲に変換します.[0.89]は切り替える周期を90フレームにしていることから来ていて,[0,PI/2]は今回のアートが90度回るたびに切り替わることから来ています.
void art1(){ background(255); fill(0); float rad = map(frameCount%90, 0, 89, 0, PI/2.0); for(int i=0;i<N+1;i++){ for(int j=0;j<N+1;j++){ if((i+j)%2 == 1){ translate(len*i, len*j); rotate(rad); rect(0, 0, len, len); resetMatrix(); } } } }
これで,黒タイル側は完了です.
「白タイル側」の実装
白側は,背景を黒にして,白の四角を描画します.また,ループ変数のi+jが偶数のときに書くことにします.ロジックは黒タイル側と同じです.
void art2(){ background(0); fill(255); float rad = map(frameCount%90, 0, 89, 0, PI/2.0); for(int i=0;i<N+1;i++){ for(int j=0;j<N+1;j++){ if((i+j)%2 == 0){ translate(len*i, len*j); rotate(rad); rect(0, 0, len, len); resetMatrix(); } } } }
以上で,全体としては以下のようになり,完成です!いかがでしょうか.正直なところ,両方とも処理が似ているので,本来は一つの関数にして引数で調整するべきですが,今回はあえて冗長に書いています.
int N=10, len; void setup(){ size(500,500); rectMode(CENTER); len = width/N; } void draw(){ background(0); if(frameCount%180 < 90)art1(); else art2(); } void art1(){ background(255); fill(0); float rad = map(frameCount%90, 0, 89, 0, PI/2.0); for(int i=0;i<N+1;i++){ for(int j=0;j<N+1;j++){ if((i+j)%2 == 1){ translate(len*i, len*j); rotate(rad); rect(0, 0, len, len); resetMatrix(); } } } } void art2(){ background(0); fill(255); float rad = map(frameCount%90, 0, 89, 0, PI/2.0); for(int i=0;i<N+1;i++){ for(int j=0;j<N+1;j++){ if((i+j)%2 == 0){ translate(len*i, len*j); rotate(rad); rect(0, 0, len, len); resetMatrix(); } } } }
拡張:切り替わる速さの調節
今回の例では,90フレームごとに切り替えています.60fpsの環境なら1.5秒ごとに切り替わることになりますが,作品によっては速すぎる場合があります.この時は,切り替えるフレーム数を増やせば良いです.
一つの案としては,定数として切り替わるフレーム数を設定する方法があります.これは(適当に付けた)FRAME_UNITという変数を使って,
int FRAME_UNIT = 90; // draw()では if(frameCount%(2*FRAME_UNIT) < FRAME_UNIT)art1(); else art2(); //フレーム数 → 角度への変換は float rad = map(frameCount%FRAME_UNIT, 0, FRAME_UNIT-1, 0, PI/2.0);
という感じで書けます.こうすると,FRAME_UNITを変えるだけで速さ調整ができて,便利です.(もちろん,mapメソッドのPI/2.0というところも,作品によって変わるかと思います.)
考察:この技法はどのようなアートに適用できるか?
ここではこの技法に関する個人的な考察を書きます.間違っているかもしれません.
この技法は,前面の模様と背景の模様の役割を入れ替えながら,前面の模様に対して何かしらの処理を行う技法です.例えば,市松模様の例では,前面の模様のつもりでタイルを市松模様に並べると,その背景も自然と市松模様になるので,これらを一定の周期で入れ替えることで成立しました.他にも,円を敷き詰めた場合には,その背景はアステロイド曲線で囲まれるような図形を並べた模様になるはずです.このような性質から,前面の模様と背景の模様が共に実装可能でなければいけません.例えば,リサージュ曲線で囲まれる領域を敷き詰めたような模様に対しては,その背景の模様を実装することは難しそうです.
また,色についても制約があると思っていて,切り替える瞬間の模様は2色で構成しないと成立しません.この技法による作品がなぜ不思議なのかというと,今まで図形だと思っていたところがいつの間にか背景になるからです.言い換えると,個々に独立していたはずの領域が連続的になるから,とも言えます.このような性質から,例えば,切り替える瞬間の模様に3色を使ってしまうと,ある1色が前面の役割として動いている間にも残りの2色が独立した領域を作ってしまって,不思議には見えません.ただし,3次元空間では,立方体などのように複数の面を備えたオブジェクトを扱えるので,周期の途中で一時的に他の色を出現させることは可能です.しかしこの場合でも,やはり切り替える瞬間の模様は2色だけにしないと成立しないと思います(後述の参考3のリンクを参照).
元々,僕がこの技法を知ったのは,Twitterでdave(@beesandbombs)さんの作品を見たのがきっかけでした.daveさんの作品ではこの技法がよく使われており,学ぶものが多いです.参考として,以下に3作品ほど,ツイートのリンクを貼っておきます.
- 参考1:2次元
— dave (@beesandbombs) 2020年10月16日
参考2:2次元
— dave (@beesandbombs) 2020年10月25日
参考3:3次元
— dave (@beesandbombs) 2020年8月30日
おわりに
今回は,アートを切り替えて不思議に魅せる技法について紹介しました.もっと良い実装方法,関連する話題などありましたら教えていただけますと幸いです.
ありがとうございました.
ICPC アジア地区予選2016-A Rearranging a Sequence 解説
問題: http://judge.u-aizu.ac.jp/onlinejudge/description.jsp?id=1367
C++で解説しています.
問題の概要
数列(1,2,...,n)があります.その後,の順で,
を数列の先頭に出します.最終的な数列を出力してください.
例えばsample1では,
1,2,3,4,5
4,1,2,3,5
2,4,1,3,5
5,2,4,1,3
となって,答えを得ます.
解法
まず,の最後にある値ほど先頭に来ることが分かります.よって,最終的な数列は,
を逆順にしたものが先頭に来て,それから残りを単に昇順にしたものが後ろにくっついたものになりそうです.sample1では,
4,2,5の順で前に出しているので,最終的な数列はその逆順の5,2,4が先頭に来て,残りの1,3が後ろにくっついたものになります.
でも一つだけ罠があって,同じ値が何度も前に出されることがあります.一見ややこしそうに見えますが,2回目以降に前に出された値は,それ以前の位置は気にする必要はありません.とにかく,最後に先頭に出された値ほど,最終的な数列でも先頭にくるということが重要で,値が何回前に出されたかは気にする必要がありません.
このことは,を逆順に出力するときに,初めて出現した値だけを出力することで実現できます.実装としては,「既に出力したか?」を表すフラグ用配列を作っておくことが考えられます.
また,に出現しなかった残りの値の出力方法については,
1,2,...,nの値を,フラグ用配列と照らしながら順番に出力するようなことが考えられます.
#include <iostream> #icnlude <vector> using namespace std; int main(){ int n,m; cin>>n>>m; vector<int> e(m); // e_iの入力 rep(i,0,m){ cin>>e[i]; } // 既に出力したか?を管理するフラグ用配列 vector<int> outed(n, 0); // e_iは後ろから見て for(int i=e.size()-1;i>=0;i--){ // フラグが0なら出力 if(outed[e[i]-1] == 0){ cout<<e[i]<<endl; // フラグを1に outed[e[i]-1] = 1; } } // 残りを出力.1~nまで回して,フラグが0なら出力 for(int i=1;i<=n;i++){ if(outed[i-1] == 0){ cout<<i<<endl; outed[i-1] = 1; } } }
ICPC 2020-B 接触追跡 解説
問題: https://onlinejudge.u-aizu.ac.jp/challenges/sources/ICPC/Prelim/1641?year=2020
問題の概要
人がm人います.最初,そのうちの一人がウイルスに感染しています.その後,nペアの人が順番に接触します.このとき,感染者と接触した人は感染疑いになります.また,感染疑いの人と接触した場合も感染疑いになります.
最終的に,感染/感染疑いの人は何人いますか?
解法(一般論)
(感染/感染疑いというのがめんどくさいので,以降は単に感染と書くことにします.)
接触者のペアを見たとき,少なくとも片方が感染しているなら両者とも感染します.よって,処理を効率よく行うには,利用者IDから,その人が感染しているかを高速に判定できれば良いです.これは,[利用者ID] = 1(感染) or 0(感染してない)となるような,0と1で構成される配列を使うことで、O(1)でできます.
はじめに,利用者IDがpの人だけ1を代入しておいて,接触者のペアのうち,どちらかの利用者IDの値に1が代入されていれば,両者ともに1を代入することを繰り返します.
最後に,配列の1の数が,そのまま答えになります.配列の要素が0か1であることを考慮すると,これは単に配列の要素の合計値として構いません.
実装(C/C++)
#include <stdio.h> int main(){ int m,n,p; while(scanf("%d %d %d", &m, &n, &p)){ if(n+m+p == 0)break; // 利用者分の配列を確保して,0で初期化 int v[100]={0}; p--; // 0始まりに v[p] = 1; // IDがpの人は感染 for(int i=0;i<n;i++){ int a,b; scanf("%d %d", &a, &b); a--; b--; // 0始まりに // どっちか感染してたら if(v[a] == 1 || v[b] == 1){ // 両方感染する v[a] = 1; v[b] = 1; } } int ans = 0; // 合計を求める for(int i=0;i<m;i++){ ans += v[i]; } printf("%d\n", ans); } }
実装(python)
while True: m,n,p = map(int, input().split()) if n+m+p == 0: break # 利用者分のリストを確保して,0で初期化 v = [0 for i in range(m)] p -= 1 # 0始まりに v[p] = 1 # IDがpの人は感染 for i in range(n): a,b = map(int, input().split()) a -= 1 b -= 1 # どっちか感染してたら if v[a] == 1 or v[b] == 1: # 両方感染 v[a] = 1 v[b] = 1 # 合計を求める print(sum(v))
別解: boolのOR演算
これはちょっとトリッキーですが,「どちらか一方でも感染してたら両者とも感染」というのは,OR演算そのものです.いま,感染していることをTrue,感染してないことをFalseとすると,
- 両方感染してるとき,
True | True = True - aだけ感染してるとき,
True | False = True - bだけ感染してるとき,
False | True = True - 両者感染してないとき,
False | False = False
となって,感染ルールはOR演算そのものだということが分かります.これを利用すると,各ペアについて,「どちらか一方でも感染している?」ことを気にせずに実装できます.
#include <stdio.h> int main(){ int m,n,p; while(scanf("%d %d %d", &m, &n, &p)){ if(n+m+p == 0)break; // 利用者分を確保して,falseで初期化 bool v[100]; for(int i=0;i<m;i++)v[i] = false; p--; v[p] = true; for(int i=0;i<n;i++){ int a,b; scanf("%d %d", &a, &b); a--; b--; // お互いに,単に相手とOR演算 v[a] |= v[b]; v[b] |= v[a]; } int ans = 0; // 合計が答え for(int i=0;i<m;i++){ ans += v[i]; } printf("%d\n", ans); } }
ICPC 2020-A カウントダウンアップ2020 解説
問題:
https://onlinejudge.u-aizu.ac.jp/challenges/sources/ICPC/Prelim/1640?year=2020
問題の概要
0から9までの整数で構築された配列があります。この配列の部分列として2,0,2,0はいくつありますか?
ただし、部分列が重なっていても別に数えます。
解法(一般論)
配列の要素を先頭から順に見ていって、そこから先の4要素が2,0,2,0かを判定すれば良いです。
具体的には、i = 0,1,....,n-4に対して、[i]=2, [i+1]=0, [i+2]=2, [i+3]=0かどうかを判定します。これはfor文の中でif文を4つ書いたりして頑張ると書けます。
後述しますが、C++では事前にstring型にしてしまってから.substr()を使う、pythonではリストのスライスを使うことで、処理を簡略化できます。
実装(C/C++)
C言語では、前述した方法をそのまま適用すれば解けます。
#include <stdio.h> int main(){ int n; while(scanf("%d", &n)){ if(n==0)break; int v[1005]; // 入力 for(int i=0;i<n;i++)scanf("%d", &v[i]); // 数える変数 int ans = 0; // 判定 for(int i=0;i<n-3;i++){ if(v[i]==2 && v[i+1]==0 && v[i+2]==2 && v[i+3]==0){ ans++; } } // 出力 printf("%d\n",ans); } }
実装(C++の別解)
別解としては、先に文字列にしてしまって、.substr(idx, len)を使う方法があります。substr(idx, len)は、文字列の添字idxから、len文字だけ切り取ります。例えば、
#include <iostream> #include <string> using namespace std; int main(){ string s = "abcde"; // 1番目の文字から2文字切り取る string sub = s.substr(1, 2); cout<<sub<<endl; // "bc"が出力される }
です。
これを使うと、以下のように書けます。
#include <iostream> #include <string> using namespace std; int main(){ int n; while(cin>>n){ if(n==0)break; int v[1005]; // 入力 for(int i=0;i<n;i++)cin>>v[i]; string s = ""; // 文字列化 for(int i=0;i<n;i++){ s += '0'+v[i]; } int ans = 0; // 判定 for(int i=0;i<n-3;i++){ // 添字iから4文字切り取る if(s.substr(i, 4) == "2020"){ ans++; } } cout<<ans<<endl; } }
判定は楽になりますが、文字列に直す処理がめんどくさいので、プラマイゼロって感じです。
実装(python)
pythonは、デフォルトで入力を文字列として受け取るので、非常に楽です。一部を切り取るのもスライス[:]でできます。
この場合に気をつけないといけないのは,文字列には空白も含むので,切り取る長さは7文字になることです.また,for文の範囲もnまでではなく,len(文字列)までになることに注意です.(以下のコードでは,スライスが配列外参照しないことを利用して,forの範囲は少しサボっています.)
while True: n = int(input()) if n == 0: break # 入力 s = input() ans = 0 # 判定 for i in range(len(s)): # 7文字切り取る if s[i:i+7] == "2 0 2 0": ans += 1 print(ans)
もし、整数のリストに直したとしても、スライスで一撃です。
while True: n = int(input()) if n == 0: break # 入力 v = list(map(int, input().split())) ans = 0 # 判定 for i in range(n): # 4要素切り取る if v[i:i+4] == [2,0,2,0]: ans += 1 print(ans)
A問題みたいに,特に計算量を考えなくて良い場合はpythonのがサクッと書けて良いかもしれない.