論文メモ:ACl2021, Instantaneous Grammatical Error Correction with Shallow Aggressive Decoding
ACL 2021 long paper, Instantaneous Grammatical Error Correction with Shallow Aggressive Decodingの論文メモです.
@inproceedings{sun-etal-2021-instantaneous,
title = "Instantaneous Grammatical Error Correction with Shallow Aggressive Decoding",
author = "Sun, Xin and
Ge, Tao and
Wei, Furu and
Wang, Houfeng",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-long.462",
doi = "10.18653/v1/2021.acl-long.462",
pages = "5937--5947",
}
この論文は,Copyright © 1963–2021 ACL,Creative Commons Attribution 4.0 International Licenseの元で公開されています.
概要
文法誤り訂正のためのモデルとして,Shallow Aggressive Decoding (SAD)を提案しています.SADは,seq2seqのモデルにおいてデコーダを工夫することで高速な生成を可能にします.具体的には,Aggressive Decodingと呼ばれるteacher forcing的な生成手法と,Re-decodingと呼ばれる自己回帰的な生成方法を切り替えながら生成します.さらに,seq2seqのアーキテクチャとしてエンコーダの層を増やしてデコーダの層は減らすことで高速化します.結果,完全な自己回帰型のseq2seqモデルよりも10倍程度高速で,かつ高性能になりました.
推論方法
推論は,Aggressive DecodingとRe-decodingの2つを交互に切り替えることで行います.
Aggressive Decodingは,一つ前の系列をteacherとしてTeacher-Focing的に生成する手法です.特に,初回のAggressive Decodingではソース文をteacherとして系列を生成します.形式的には(2)式に従います.ここでがモデルの出力,
が一つ前の系列,
がソース文の系列を表しています.初回に限り,
です.
は当然givenなので,並列計算が可能です.後で議論がありますが,Aggressive Decodingでは系列の長さに制限を設けずに生成します.
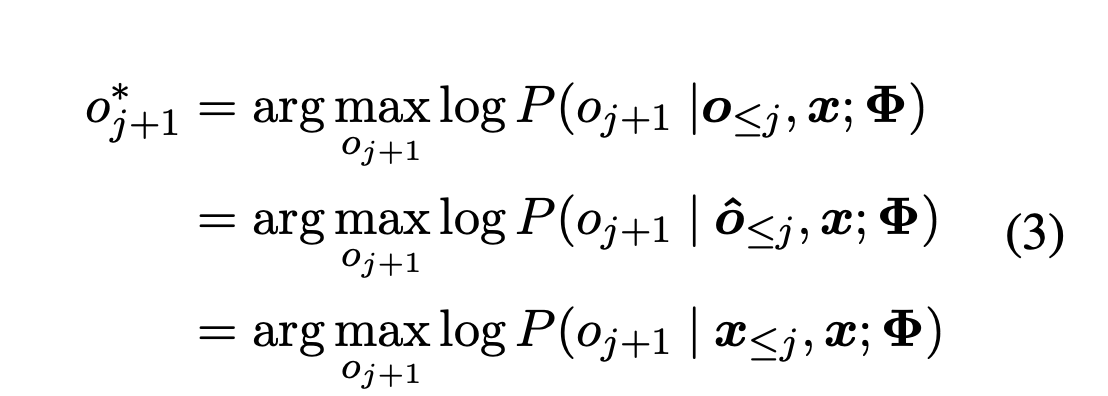
次に,生成した系列と
を先頭から比べて,完全に一致していれば
には誤りが無いとみなし,終了します.もし一致しない場合,先頭から比べて初めてトークンが異なるインデックス
を求めます.形式的には,
であり,
であるような
です.この時点で,
は生成結果として確定します.また,
より後ろの系列は破棄します.
インデックスが見つかれば,Re-decodingに切り替えます.Re-decodingでは,
から1単語ずつ自己回帰的に生成します.具体的には,
について式(4)に従って生成します.
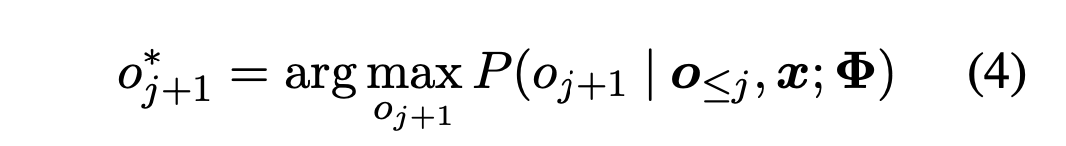
Re-decodingは,入力系列と一致するトークンのsuffix(末尾からの部分列)が見つかるまで行います.形式的には,
について
を推定したときに
となるような
が見つかれば良いです.もしこのsuffixが見つかれば,再度Aggressive Decodingに切り替えます.この時点で,
までが生成結果として確定します.
再度Aggressive Decodingに戻ってきたときには,Teacher-Focingに用いる系列として式(6)のようにconcatしたものを用います.つまり,過去にAggressive DecodingやRe-decodingによって得られた系列と,それ以降に対応するソース文の系列をconcatします.Re-decodingのときにソース文の系列とのsuffixの比較をしているので,「それ以降に対応するソース文の系列」は一意に決まります.
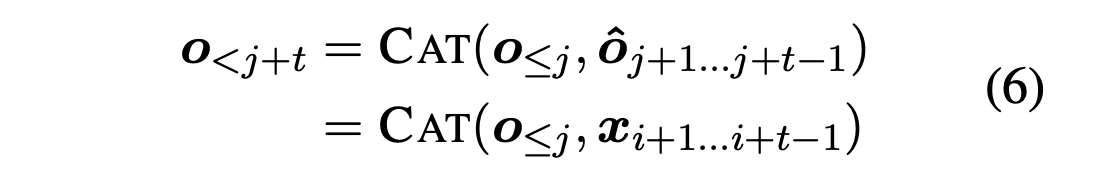
このように,Aggressive DecodingとRe-decodingを切り替えることで系列が生成できます.切り替えは条件を満たせば何度でも行われます.Aggressive Decodingは並列計算可能で高速であり,Re-decodingは自己回帰なので低速です.しかし,全てを自己回帰で生成するよりは明らかに高速に動作します.
また,Aggressive Decodingにおいてさらに低コストに計算するため,デコーダを浅くするshallow decoderを採用しています.
これらをより一般化したアルゴリズムはAlgorithm1に示されています.

Aggressive Decodingの評価
評価データで性能を見る前に,開発データとしてCoNLL-2013を使って性能を分析しています.
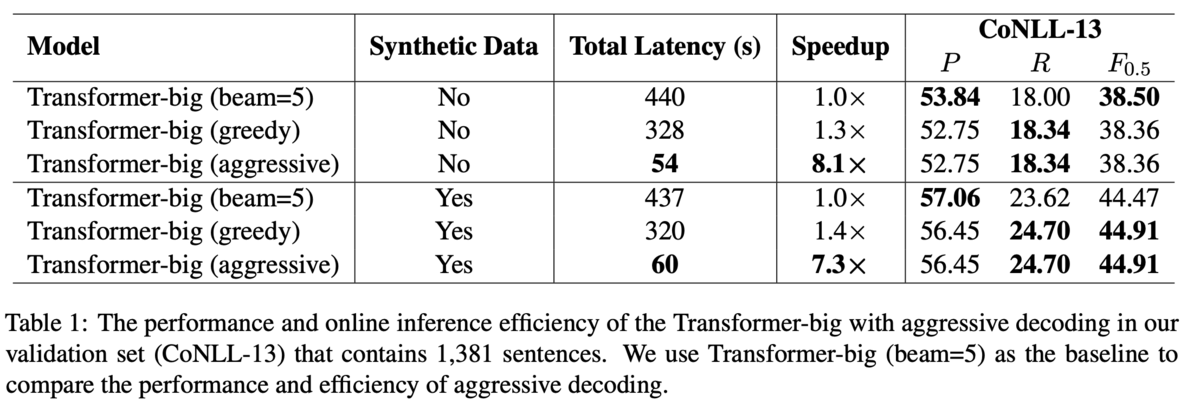
まず,提案手法の速度と性能を調査するために,全てを自己回帰で生成するseq2seqモデルをベースラインとして比較します.結果,提案手法は明らかに高速に動作し,Recallは上昇するがPrecisionは低下する傾向にあるとしています(Table 1).
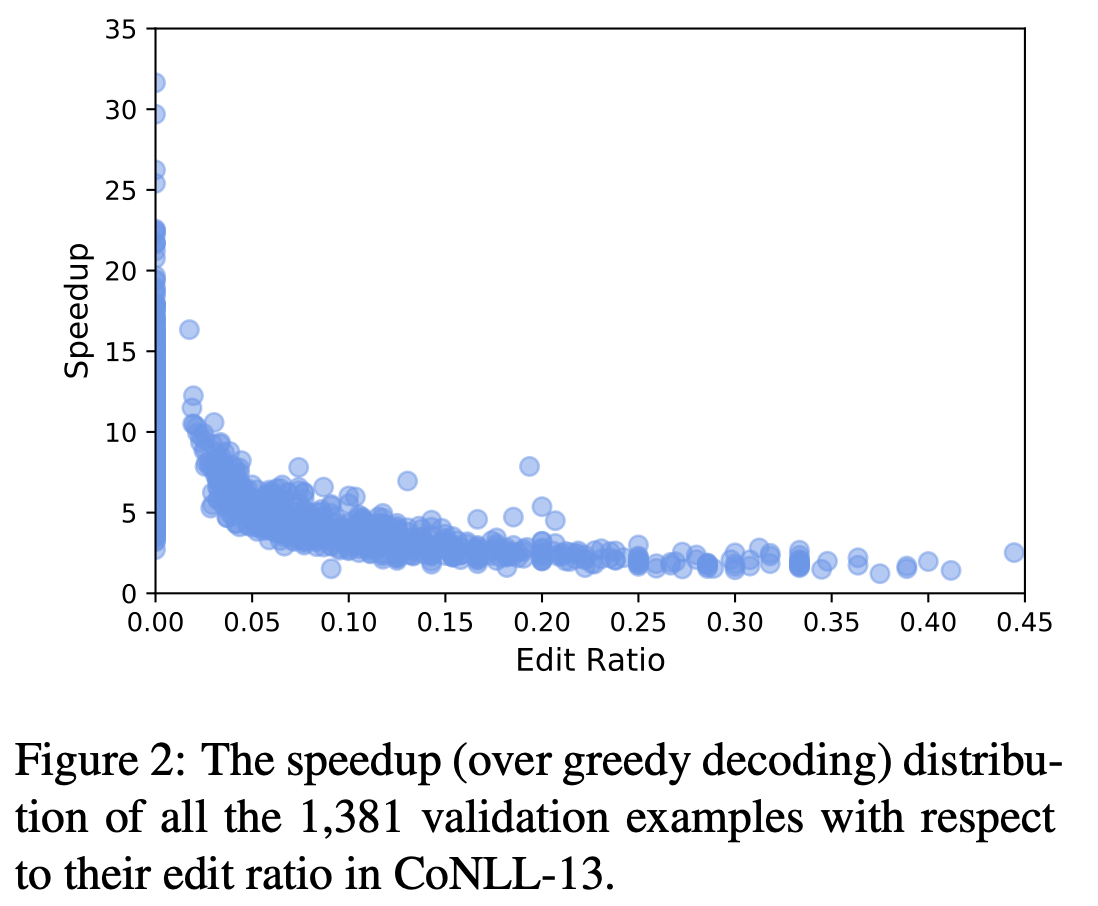
また,編集率が高いほど速度が低下します(Figure 2).この理由として,編集率が高いと低速なRe-decodingが頻繁に実行されるからだと分析しています.これはTable2に具体例があります(本記事では割愛).
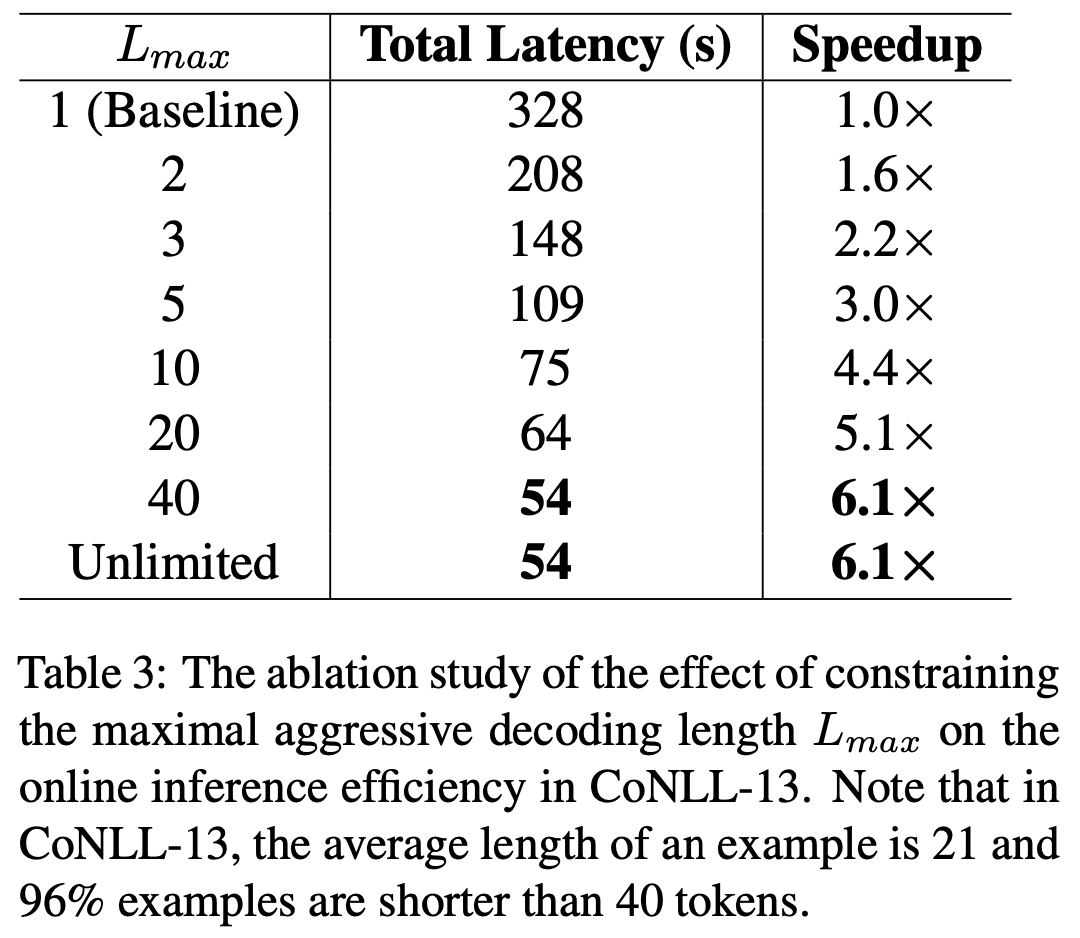
次に,Aggressive Decodingでデコードするトークンの長さは制限しなくて良いとしています(Table 3).Aggressive Decodingで長々と出力しても,入力系列と異なるトークンがあればそのトークン以降は破棄されてRe-decodingに移ってしまいます.よって長々と出力するのはリスクが大きそうですが,むしろ制限しないほうが高速でした.この理由として,GECの入力となる文にそこまで長いものは無いからだと分析しています.
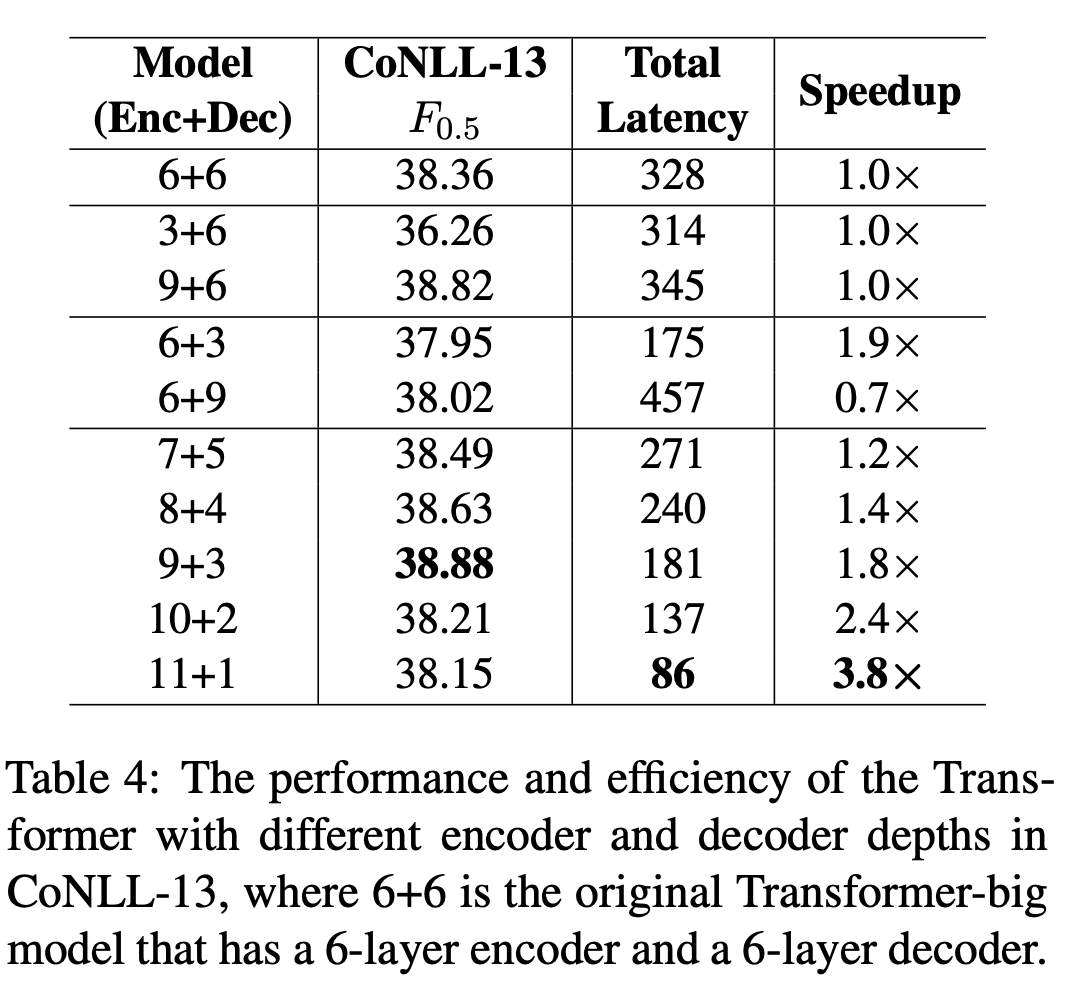
最後に,エンコーダは深く,デコーダを浅くするのが良いとしています(Table 4).Table 4中の3+6と9+6のブロックからはエンコーダを深くすると速度を維持したまま性能が向上することが分かり,6+3と6+9のブロックからはデコーダを深くすると速度が落ちるのに性能はほぼ変わらないことが分かります.11+1のように極端に深さを変えると性能が落ちることから,論文中では9+3を使っています.
結果
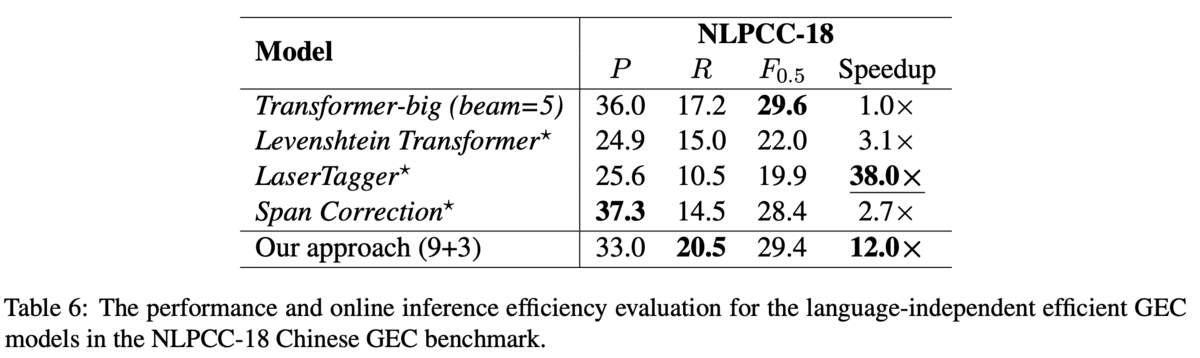
英語(CoNLL-14データセット,Table 5)と中国語(NLPCC-18データセット,Table 6)で評価しています.
英語のデータセットについて,Multi-stage Fine-tuningなしの部門では,9+3のモデルが最高性能,かつベースラインを10倍高速化しています.また,先行研究のGECToRではBERTなどの事前学習モデルを用いていることに倣って,12+2のモデルをBARTで初期化しています.その結果で66.4を達成しました.
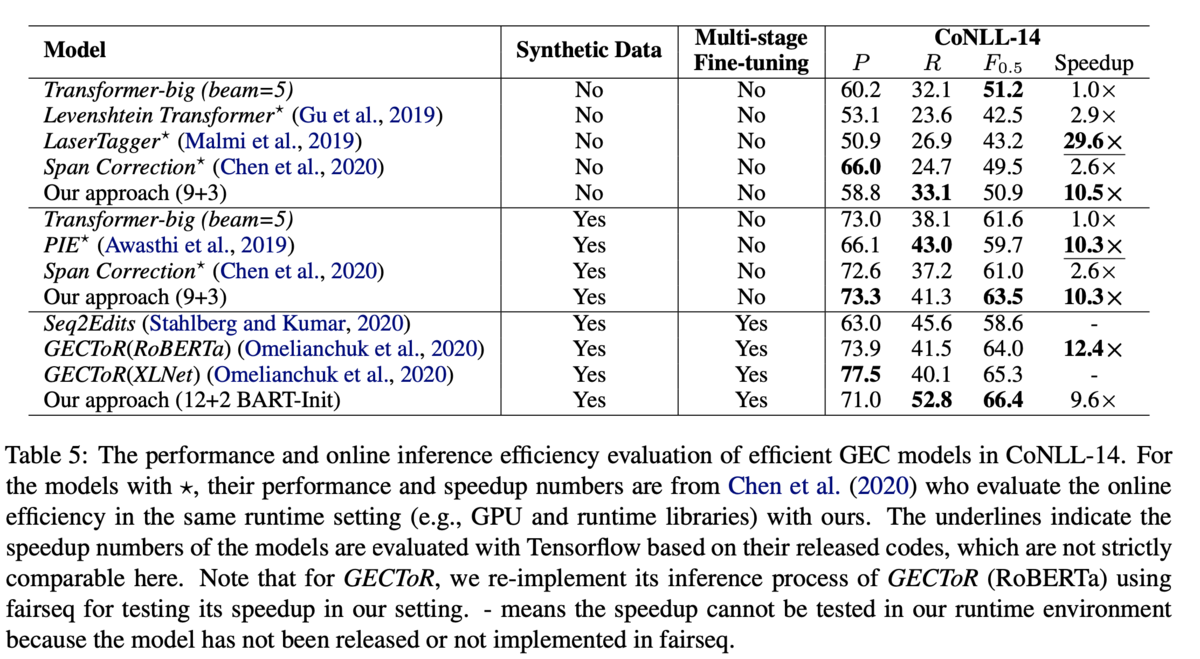
中国語のデータセットでも,性能は完全自己回帰であるようなTransformerと同等の性能で,12倍もの高速化を達成しています.また,ここでは英語や中国語のように言語非依存なGECが行えることも貢献としています.例えば,GECを系列タギングとして解いたGECToRでは,英文法の事前知識をもとにg-transformationと呼ばれるタグを用いて訂正を行っていますが,このタグを用いると英語のデータにしか適用できません.一方提案手法はタグを使わないモデルですし,文法に関する事前知識は必要ないため,言語によらず適用できます.