文法誤り訂正の可視化ツールを作ってみた
本記事は,GEC (Grammatical Error Correction) Advent Calendar 2021 の22日目の記事です.
はじめに
Gold / システム出力に含まれる訂正としてどんなものがあるか,実例をボーッと眺めたいと思う時がありませんか?今はなくてもそのうちあるかもしれません.そんなときに役立つツールを作りたいということで,作ってみたという話です.GECのアドカレが始まってから思いついて,一人ハッカソン的なノリでやってみました.今までこういうツールはないと思ってやっていますが,もし存在すればこの企画が潰れます(あれば教えてください...).
Web開発的な記事になりますが,技術的な話はほぼしません.結果として何ができたかを報告するような内容になります.
できたツールは以下に公開しています(こういう開発はほとんどしたことがないので,ありえない実装をやってるかもしれませんが,ご容赦ください...).
何ができればいいのか
誤り訂正の様子を原文と共にハイライトしたいです.M2形式は確かに素晴らしいですが,人間にとってはスパンの認識が厳しく,ボーッと眺めるには頭を使います.そこで,原文の間にいい感じに割り込むようにして訂正情報を表示したいと思いました.さらに,ハイライトする誤りを,誤りタイプや置換・挿入・削除の分類で絞り込みたいです.
何ができたか
以下のような見た目のものができました.訂正情報を赤(オレンジ?)でハイライトし,誤りタイプも併記します.また,チェックボックスによって誤りタイプの絞り込みができます.例えば,誤りタイプM:DETのみを見たい場合は,MとDETのみにチェックを入れます.

使い方
冒頭に掲載したリポジトリのREADME を見ていただければ話が早いですが,原文と訂正文のファイル,もしくはM2形式のファイルを入力として,プログラムを走らせるだけです.実行したらローカルにサーバが立つので,ブラウザで見にいけば可視化したものが閲覧できます.
python run.py --orig <orig file> --cor <corrected file> # もしくは python run.py --m2 <m2 file> # 実行したら,http://127.0.0.1:5000/を見にいきましょう
原文と訂正文のファイルを入力とした場合,ERRANTによって訂正のスパンを獲得します.M2形式のファイルを入力とした場合は,訂正のスパンや誤りタイプはM2形式が示すものに従います.M2を入力とする場合は--ref_idオプションでアノテータIDも指定できます.デフォルトは0です.逆に言うと,マルチリファレンスを同時に可視化することはできません,
先に述べたように,本ツールは誤りタイプで絞り込む機能があります.誤りタイプとしては基本的にERRANTの定義を想定しており,置換・挿入・削除と,品詞が関係するもの(VERBとかNOUNとか)を別々に指定できるようにしています.そのため,チェックボックスを2つのブロックに分けています.一方で,M2形式のファイルを入力とする場合,誤りタイプの定義が異なる場合があります.例えば,CoNLL-2014のアノテーションは誤りタイプの定義が異なりますし,置換・挿入・削除は明示的に付与されません.このような場合,チェックボックスは片方のブロックのみ用いられます(ちょっと色々な理由からこうなっています.これを書きながら,別に分ける必要もない気がしてきました).
展望
今後も開発するか分かりませんが,ひとまず僕が欲しい機能は実装できたと思います.M2形式を入力に受け付けるおかげで,任意の言語を入力に受け付ける点が結構良いなと思っています(対象言語の訂正情報がM2形式に従う仕様であれば).ロクにテストをしていないせいでバグがあるかもしれないので,そこは一応今後もチェックしたいと思います.
あとできたらいいなと思うのは,2つの訂正情報について比較するようなことですね.システムAとシステムBの出力があったときに,Aはこんな訂正をたくさんしているけどBはしてないね,みたいなことが分かりやすく比較できれば,GECの分析において一役買うのではないかと思っています.同様の比較はシステム出力と参照文に対しても適用可能で,そうするとエラー分析が容易になる気がします.
おわりに
ということで,今回は訂正の可視化ツールを作ってみました.
評価手法としてではない評価手法
本記事は,GEC (Grammatical Error Correction) Advent Calendar 2021 の18日目の記事です.
はじめに
評価手法は,基本的に「評価手法を提案した」ことをメインに発表されることが多いです.一方で,それ以外の主張をメインとするときでも,評価手法(とみなせるもの)が含まれることがあります.この記事では前者を「評価手法としての評価手法」,後者のことを「評価手法としてではない評価手法」と呼び,後者にフォーカスします.こうした話は,「良い訂正文とは何か」とか,「Grammaticalとは何か」という話題について,他の研究者がどう考えているかを知ることにつながると思っています.
ひとまず概要として「評価手法としてではない評価手法」がどういうものに該当するかを書きます.その後,具体的な手法をつらつらと書きたいと思います.
概要
ひとまずどういうものが「評価指標としてではない評価手法」になりうるか,というと
- リランキング手法
- 強化学習のリワード計算手法
- データクリーニング手法
あたりがあると思っています.
リランキングはGECモデルに複数の訂正文を生成させて,それらの文を別のモジュールで並び替えることです.この処理においては「別のモジュール」が複数の訂正文をそれぞれ評価し,順位をつけているとみなせます.
強化学習のリワードも評価手法として捉えられます.例えばSakaguchi+ 2016はGLEUをリワード計算手法として用いています.そういう意味では,既存の評価手法がリワード計算に用いられるケースが多い気もしますが,リワード計算手法を独自に設計した場合は「評価手法としてではない評価手法」に該当します.
データのクリーニングもある種の評価手法が使われていると思います.クリーニングすべき文を判断するときや,クリーニング後の文を採用するかどうかに関する意思決定においては,文を特定の観点で評価する必要があります.
逆に考えると,評価手法は単にベンチマーク上でシステムの順位づけをするだけではなく,上のことにも応用できると思っています.そういう意味でも,評価って面白いですよね(僕だけかも).
以下には具体的な手法を列挙しますが,基本的に上の3つの文脈に当てはまると思います.このテーマについて腰を据えてサーベイしたわけではないので雑かもしれませんが,ご容赦ください(あまり時間がなかった...).
評価手法としてではない評価手法
R2L(Right to Left)
文の末尾からの確率で評価する方法です.リランキングの文脈で使われています.GECではKiyono+ 2019で使われている印象が強いです.評価軸は文の最もらしさでしょう.おそらく初出はLiu+ 2016で,ほぼ同時にSennrich+ 2016も試していたという感じだと思います.
誤り検出器
GECの訂正結果を誤り検出器の検出結果と比べて評価する方法です.リランキングの文脈で使われています.代表的なのはYuan+ 2021です.誤り検出ラベルを定義しており,検出器と訂正器のラベルの近さで並び替えます.検出はFalse Positive(モデルが修正したけど間違い)を減らすというモチベーションで導入されることが多い印象です.つまり,評価軸は誤検出が少ないかどうかになると思います.
ちなみに,「評価手法としての評価手法」ではNapoles+ 2016が誤り検出に基づいています.
入力文と生成文を用いた文ペア分類
GECの生成文を入力文(ソース)と一緒にニューラルベースの評価器に入力し,評価する方法です.Raheja+ 2020が強化学習のリワード計算の文脈で提案しています.特にこの研究では,文ペア分類器は生成文を「人が訂正したものか?Generatorが訂正したものか?」という観点で分類するように学習します.ですので,評価軸は人間らしい訂正かどうかになると思います.
LM-Critic
評価対象の文に対する近傍の文を多数生成し,評価対象の文のPPLが一番低ければOKみたいな評価方法です.Yasunaga+ 2021が,BIFIという手法をGECに適用するために提案しました.BIFIの詳細は11日目の記事で触れましたが,主にデータクリーニングの文脈で使われていると思っています.評価軸は文がGrammaticalかどうかです(著者らはGrammaticalにおける前提をけっこう強く置いていて,だからこそなせる技かもしれない).
PPLの比較(2文に対する比較)
ある2文が存在するときにPPLを比べて優劣をつけるための評価方法です.Mita+ 2020はデータのデノイズの文脈で,PPLを比べることで文の優劣を評価しています.PPLは文の尤度に絡むものなので,評価軸はR2Lと同様,文の最もらしさです.
上で述べたLM-CriticもPPLに基づきますが,入力が1文です.ここでは2文を比べて何かモノをいう場面を想定していて,項目を分けました.
「評価手法としての評価手法」では,参照なし評価手法であるScribendi Score(Islam+ 2021)がPPLの比較に基づいています.
おわりに
「評価手法としてではない評価手法」にフォーカスしました.個人的には,評価手法はベンチマークの評価以外にも応用できるということが再確認できました.また,今回紹介したように,モデルを提案する手法の中にも評価を独自の視点で組み込んでいることがあるので,今後も注目すると面白いかもしれません.
GECの論文紹介:EMNLP2021
本記事は,GEC (Grammatical Error Correction) Advent Calendar 2021 の11日目の記事です.
はじめに
国際会議EMNLP2021にフォーカスし,GEC(Grammatical Error Correction,文法誤り訂正)に関する論文で特に気になったものを3件紹介します.本当はGEC関係の論文を全て紹介するつもりでしたが,文字数がえらいことになるので3件にしました.読者の多くは既に内容を知っている気がするので,内容は簡単に済ませて,個人的な考えを多めに盛り込むような構成になっていると思います.
本記事の記述の中には厳密でない表現があるかもしれませんが,ご容赦ください.
1. Is this the end of the gold standard? A straightforward reference-less grammatical error correction metric
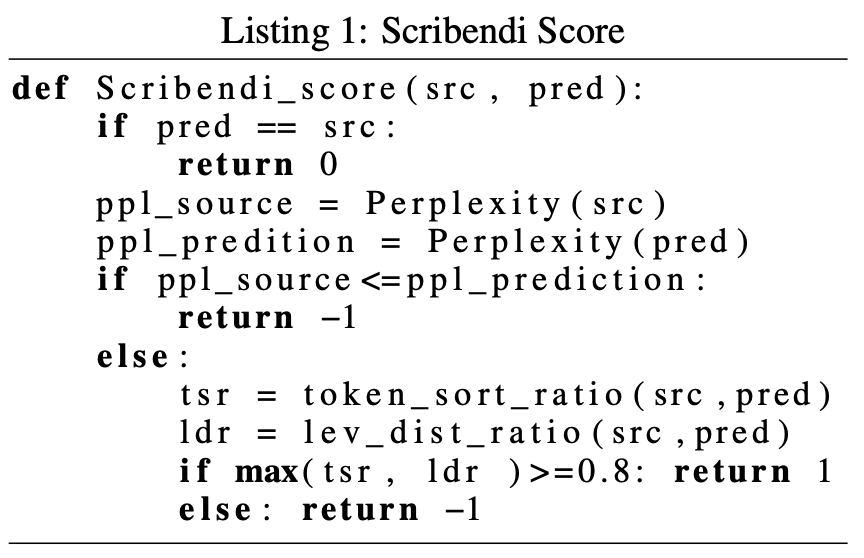
参照なし評価尺度を提案した論文です.システム出力文を0(訂正なし),1(改善した),-1(悪化した)の3値で評価します.出力文それぞれに対してこの評価値を計算し,合計がシステムの評価値になります.つまり,文数をとすると評価値は
]のレンジになります.
改善した/悪化した ことは,Listing 1に示されたプロセスで判断します.はじめに一致判定を行い,次にPPLの値を見ます.PPLの値は低いほど良いので,sourceよりpredictionのほうがPPLの値が高いとき,それは悪化したと判断します(-1が返る).最後に,token_sort_ratioとlevenshtein-distance_ratioのうち,いずれかが0.8以上であれば改善したと判断し,そうでなければ悪化したと判断します.token_sort_ratioは,2つの文に同じトークンが同じ数含まれているほど高くなるような一致度です.levenshtein_distance_ratioは,で定義される一致度です(
は編集距離.ただし,置換コストが2,挿入・削除のコストが1).
結果としては,人手相関が高いこと,同じフレーズを繰り返すような文をちゃんと悪いと言えることを示しています.
個人的には,3値分類というざっくりとした基準での評価であるにも関わらず,人手相関が0.8前後あることに驚きました.人手評価に近いランキングを得ることだけを目標にするなら,案外ざっくりでも良いのかもしれません.一方で,学術的な議論をする上で,モデルが何を解けて何を解けないかを分析することを考えると,この評価指標は使いにくいと思います.
疑問点としては,流暢な訂正がちゃんと良いと言えるか?というところが気になります.token sort ratioやlevenshtein distance ratioは,表層的に近いものを評価する尺度になっていると思います.一方で,流暢な訂正はそれなりに大きな書き換えになることが言われている(JFLEGの論文をreferしておきます)と思いますが,ratioによる評価は表層的に近いものを認めるようになっているので,流暢な訂正を悪いと言ってしまいそうな気もします(maxを取る方法や0.8という閾値が絶妙で,うまくやっているのかもしれません).
あと気になったのは,人がアノテーションした正解文をpredだと思って提案評価尺度に入れると,全部1(改善した)になるのでしょうか?そのうちやってみたいと思います.
おまけ:Levenshtein distance ratioの実装
import numpy as np def lev_dist_ratio(src: str, pred:str) -> float: len_src = len(src) len_pred = len(pred) dp = np.zeros((len_src+1, len_pred+1)) for i in range(1, len_src+1): dp[i][0] = i for j in range(1, len_pred+1): dp[0][j] = j for i in range(1, len_src+1): for j in range(1, len_pred+1): cost = 0 if src[i-1] != pred[j-1]: cost = 2 # 置換コストは2 dp[i][j] = min( dp[i-1][j-1] + cost, min(dp[i-1][j] + 1, dp[i][j-1] + 1) ) return 1 - dp[len_src][len_pred] / (len_src + len_pred)
2. LM-Critic: Language Models for Unsupervised Grammatical Error Correction
GECの教師なしアプローチを提案しています.ソースコード修復タスクのために提案されたBIFIという手法をGECに適用しました.また,BIFIは文が正しいかどうか見極めるCriticの機構を必要とするので,GECのためのCriticであるLM-Criticも提案しています.
GECにおけるBIFIは,誤りを生成するbreakerと,誤りを訂正するfixerが相互に働いて学習を進めます.最終的にはfixerをGECモデルとして使うことになります.BIFIは,以下の(8)から(11)式を1サイクルとし,このサイクルを回すことで学習を進めます.つまり,breakerが作った誤りデータを元にfixerが学習し,fixerが作った正しいデータでbreakerが学習し,breakerが作った誤りデータでfixerが学習し・・・というプロセスを繰り返すことになります.いわゆるGAN的な構造だとは思いますが,お互いにデータを作るだけでパラメータの更新には直接関与しない点がちょっと違うと思います.
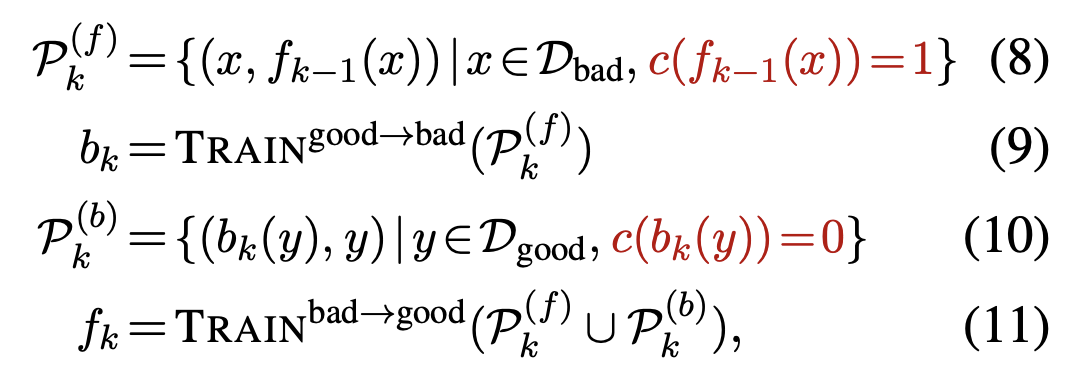
それから,breakerが生成した誤り文・fixerが訂正した文が,本当に誤っているのか ・正しいのかを判定するLM-Criticも提案しています.上の式では赤文字で表されており,xを文として,c(x) = 1(正しい文である)or 0(誤り文である)を返します.手法としては,文字レベルや単語レベルの編集を行い,xの近傍の文を数百文生成します.それから,近傍の文,それから入力であるxのPPLをそれぞれ計算し,xのPPLが最も低ければ1(正しい),そうでなければ0(誤り)として判断します.つまり,xが正しい(grammatical)であると結論づけるためには,全ての近傍の文にPPLで勝つ必要があります.
結果,CoNLL2014のF0.5で55.5を達成しました.教師なしではだいぶ高い性能だと思います.教師ありの設定では,F0.5が65.8とGECToRを少し上回るぐらいの性能を示したようです.
これを研究室の論文紹介で話したとき,「正解と誤りのペアを作っているなら教師ありなのでは」という意見があって,確かに教師なしの定義とはなんだろうと思ってしまいました.この論文では「人が作った正解データを使うかどうか」が教師あり/なしの基準になっています.従来のLMで頑張るような手法(Bryant+ 2018, Alikaniotis+ 2019など)と比べると,(擬似データのみとはいえ)誤り文と正しい文のペアを与えている時点で多少有利な設定なのかなと思いました.それから,BIFIはbreakerとfixerが交互に高め合えることが利点ですが,論文ではこれを1ラウンドしか回していません.おそらく(8)から(11)式をひと舐めして終わりだと思います.せっかくサイクルを回せるような手法になっているので,もっと回したら良いのにと思いました.回すとむしろ悪化したのかもしれません...?
一方で,近傍の文とPPLを比べるLM-Criticの発想はとても興味深いものでした.近傍の作り方は色々考えられるので,工夫すればもっと良い指標になるかもしれません.また,今回はPPLが最も低い文(だけ)がGrammaicalだ,というハードなCritic設計になっていますが,ソフトな基準にすれば使いどころが増えるのかなと思いました.例えば,PPLの低さで10位以内に入っていればOKだとか,PPL低さの順位を連続値に変換して扱うとかは考えられます.BIFIに組み込むことを考えるとハードな設計であるべきですけども.
また,この研究でのBIFIはほぼ擬似誤り生成手法と見て良いと思っています.今までの擬似データ生成手法と異なるのは,生成した擬似誤り文が本当に誤りなのかを,LM-Criticでちゃんと判断しているところです.擬似誤り生成はよく取り組まれていますが,生成した擬似誤りは全部使うのが普通だと思います.一方,BIFIではその質をちゃんとLM-Criticで判断して,質の悪い擬似誤りは捨てます.この点はけっこう重要な視点かもしれないと感じました(先行研究でこういうのはなかった気がするのですが,ありましたっけ?質の悪いデータを改善するという意味ではMita+ 2020は近そうです).
3. Multi-Class Grammatical Error Detection for Correction: A Tale of Two Systems
GECにGED(Detection)を本気で取り入れたような論文です.ICLR2020に採択されたELECTRAをベースにしたGEDシステムを提案し,Transformerに追加でEncodeしたり,リランキングに使ったりします.GEDはトークン単位でmulti-class({2, 4, 25, 55}-class)な分類をします.例えば,2-classは正解/誤りの2値分類ですが,4-classだと誤りラベルが置換/挿入/削除まで細分化します(本記事では載せませんが,詳細はTable 1).
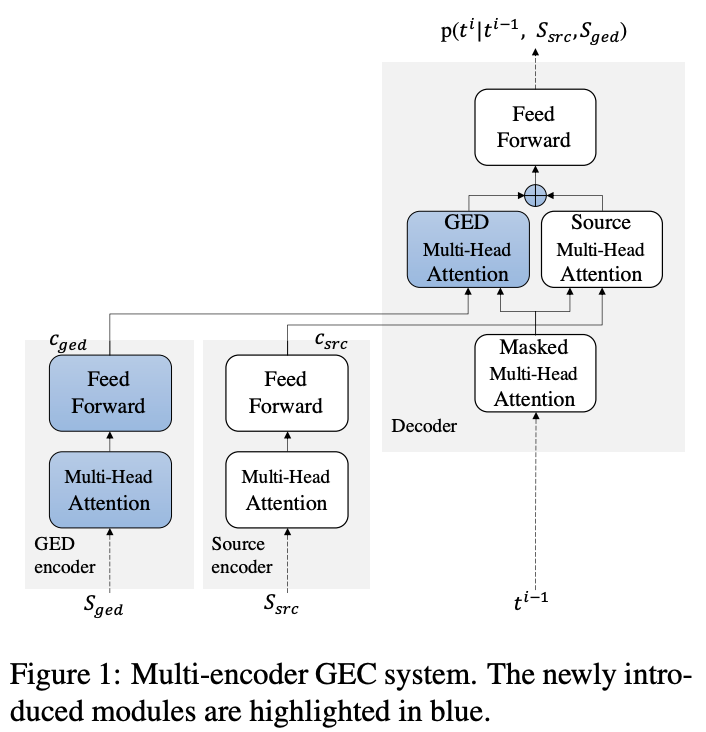
GEDの情報は,Transformerのアーキテクチャを拡張したMulti-Encoderに使われます(Figure 1).
また,リランキングにも使われます.具体的には,GEDシステムが推定した検出ラベルを正解とみなし,それと最も一致するようなGECシステムの出力を選びます(GECシステムの出力は検出ラベルではなく文ですので,入力文とのアライメントを取って検出ラベルに変換します).一致度にはハミング距離を使っているようです.
個人的には,検出の情報を明示的に与えることにどれくらい意味があるのかなと思っていました.検出できないと訂正できないので,GECシステムも既に検出の情報を考慮しているはずです.このことから,それに加えてさらに検出の情報を与えても効果は薄いのではと思っていました.論文ではこの辺りちゃんと実験がされていて,「検出情報のオラクルを用いたときに訂正がどれくらいできるか」が調べられています(ここでは載せませんが,Table 2).この実験の結果は,検出の情報がちゃんと取れているとすると訂正の精度も飛躍的に上がるということが示唆されています.検出の情報を明示的に与えることには案外意味がありそうだという気持ちになりました.
それから,現状のコミュニティでは,GECはみんなやっていますが,GEDを極めるような研究はあまり無いように思います.すぐに思いつくのはNagata+ 2021やKaneko+ 2019あたりでしょうか.でもGECに比べると圧倒的に少ない印象です.タスク設定としてはGECよりもGEDの方が明らかに解きやすいので,もっと取り組まれても良いような気はしました.GEDを極めて高い精度で検出できるようになれば,GECも大きく進化するかもしれません.
この3本を読んで
今回は3本を紹介しました.そのうち2本はモデル提案系の話ですが,「良い訂正文とは何か」をちゃんと評価する機構を採用しているのが印象的でした.2本目で紹介した論文ではLM-Criticが評価方法に対応していて,他のことにも使えそうな気がします.3本目で紹介した論文ではリランキングの方法を提案していました.リランキングはGECモデルの確率とは別の評価尺度で再評価していると捉えられます.ですので,リランキング手法は実質参照なし評価手法ぐらいに思っていて,注目してきたいと思っています.
Reference
Islam, Md Asadul, and Enrico Magnani. "Is this the end of the gold standard? A straightforward reference-less grammatical error correction metric." Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021
Yasunaga, Michihiro, Jure Leskovec, and Percy Liang. "LM-Critic: Language Models for Unsupervised Grammatical Error Correction." Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021.
Yuan, Zheng, et al. "Multi-Class Grammatical Error Detection for Correction: A Tale of Two Systems." Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021.
Gramformerを動かしてみた
本記事は,GEC (Grammatical Error Correction) Advent Calendar 2021 の9日目の記事です.
はじめに
2021/11月末にGramformerというリポジトリを見つけました.
特に何かの論文の実装というわけではなさそうで,プロジェクトを立ち上げたという感じの雰囲気です.出来たてのプロジェクトですが(first commitは今年7月),既にStarが800以上付いており,注目されていることが伺えます.まだまだ未実装の部分も多く未知数ですが,面白そうな取り組みなので速報的に紹介します.
何に使えるか
READMEによると,Gramformerは次のようなケースで使えるとしています.
Post-processing machine generated text
Human-In-The-Loop (HITL) text
Assisted writing for humans
Custom Platform integration
(今から書くのは僕の妄想ですが)これらを見る限り,単にGECシステムを扱うリポジトリというわけではなく,もっと広いところを見ているように感じます.1.からはGECに止まらないタスクとの関わりを予感します.また,2.からは誤りのない正しい文とか,システム出力をpost-processing的に人手修正したようなデータが蓄積されそうな気がしています.最後に4.はよりアプリケーションを意識した記述です.おそらくgrammarlyなどの既に知られた訂正ツールは企業運営のものばかりなので,オープンソースなものが構築されることに意義を主張しているのだと思います.3.は現在のGECコミュニティが最も強く意識している項目だと思います.GECに関する大きなプロジェクトになりそうなので,楽しみですね.
何ができるか
現状公開されている範囲では,Correcter(訂正器),Detector(検出器),Get Edits),Highlighterの機能を提供するようです.
Install
pythonは3.7推奨のようです.
pip3 install pip==20.1.1 # IMPORTANT NOTE: (If install runs endlessly resolving package versions in for instance colab, refer to issue #22 - https://github.com/PrithivirajDamodaran/Gramformer/issues/22) pip3 install -U git+https://github.com/PrithivirajDamodaran/Gramformer.git
Correcter
文中の誤りを訂正します.Gramformerオブジェクトの.correct()を呼ぶだけなので,簡単です.
from gramformer import Gramformer import torch def set_seed(seed): torch.manual_seed(seed) if torch.cuda.is_available(): torch.cuda.manual_seed_all(seed) set_seed(1212) gf = Gramformer(models = 1, use_gpu=False) # 1=corrector, 2=detector influent_sentences = [ "He are moving here.", "I am doing fine. How is you?" ] for influent_sentence in influent_sentences: corrected_sentences = gf.correct(influent_sentence, max_candidates=1) print("[Input] ", influent_sentence) for corrected_sentence in corrected_sentences: print("[Correction] ",corrected_sentence) print("-" *100) ''' 出力: [Gramformer] Grammar error correct/highlight model loaded.. [Input] He are moving here. [Correction] ('He is moving here.', -31.02850341796875) ---------------------------------------------------------------------------------------------------- [Input] I am doing fine. How is you? [Correction] ('I am doing fine, how are you?', -37.6710205078125) ---------------------------------------------------------------------------------------------------- '''
Get Edits
ERRANTのアライメント手法を用いてアライメントを取ります.Gramformerオブジェクトの.get_edits()を呼ぶだけです.ERRNATは2019年12月ごろにpythonモジュールとしてimportできるようになっているので,それを活用した形になります.
... <前略> ... for influent_sentence in influent_sentences: corrected_sentences = gf.correct(influent_sentence, max_candidates=1) print("[Input] ", influent_sentence) for corrected_sentence in corrected_sentences: print("[Edits] ", gf.get_edits(influent_sentence, corrected_sentence[0])) print("-" *100) ''' 出力: [Gramformer] Grammar error correct/highlight model loaded.. [Input] He are moving here. [Edits] [('VERB:SVA', 'are', 1, 2, 'is', 1, 2)] ---------------------------------------------------------------------------------------------------- [Input] I am doing fine. How is you? [Edits] [('OTHER', 'fine.', 3, 4, 'fine,', 3, 4), ('ORTH', 'How', 4, 5, 'how', 4, 5), ('VERB:SVA', 'is', 5, 6, 'are', 5, 6)] ---------------------------------------------------------------------------------------------------- '''
Highlighter
ソースに訂正スパンを埋め込む形で出力します.Gramformerオブジェクトの.highlight()を呼ぶことで使えます.
... <前略> ... for influent_sentence in influent_sentences: corrected_sentences = gf.correct(influent_sentence, max_candidates=1) print("[Input] ", influent_sentence) for corrected_sentence in corrected_sentences: print("[Edits] ", gf.highlight(influent_sentence, corrected_sentence[0])) print("-" *100) ''' 出力: [Gramformer] Grammar error correct/highlight model loaded.. [Input] He are moving here. [Edits] He <c type='VERB:SVA' edit='is'>are</c> moving here. ---------------------------------------------------------------------------------------------------- [Input] I am doing fine. How is you? [Edits] I am doing <c type='OTHER' edit='fine,'>fine.</c> <c type='ORTH' edit='how'>How</c> <c type='VERB:SVA' edit='are'>is</c> you? ---------------------------------------------------------------------------------------------------- '''
Detector
検出器は現在(2021/12/8)未実装ですが,Gramformerオブジェクトの.detect()で利用できることが示されています.
モデル
モデルはgrammar_error_correcter_v1と呼ばれるSeq2Seqなモデルを使っているようです.アーキテクチャはよくわかりません.訓練データはWikiEdits,C4ベースの擬似誤りデータ(Stahlberg+ 2020),PIEの擬似誤りデータ(Awasthi+ 2019)を使っているようです.推論時には,GPT-2のスコアによるリランキングをしています.
性能をざっくり検証
せっかくなのでCoNLL-2014 test setの性能を見てみたいと思います.Gramformerがトップで出力した文をそのまま評価に使います.
- コード(p.pyとします)
from gramformer import Gramformer import torch import argparse def set_seed(seed): torch.manual_seed(seed) if torch.cuda.is_available(): torch.cuda.manual_seed_all(seed) gf = Gramformer(models = 1, use_gpu=False) # 1=corrector, 2=detector def main(args): set_seed(1212) gf = Gramformer(models = 1, use_gpu=False) outputs = [] with open(args.in_file) as fp: for src in fp: src = src.rstrip() corrected_sentences = gf.correct(src, max_candidates=1) outputs.append(corrected_sentences[0][0]) with open(args.out_file, "w") as fp: fp.writelines(outputs) def get_parser(): parser = argparse.ArgumentParser() parser.add_argument('--in_file', required=True) parser.add_argument('--out_file', required=True) args = parser.parse_args() return args if __name__ == '__main__': args = get_parser() main(args)
* コマンドたち
# データの準備 wget https://www.comp.nus.edu.sg/~nlp/conll14st/conll14st-test-data.tar.gz tar -xf conll14st-test-data.tar.gz cat conll14st-test-data/noalt/official-2014.combined.m2 | grep '^S ' | cut -d ' ' -f 2- > conll14st-test-data/noalt/orig.txt # 実行 python p.py --in_file conll14st-test-data/noalt/orig.txt --out_file conll14_out.txt # 評価 wget https://www.comp.nus.edu.sg/~nlp/sw/m2scorer.tar.gz tar -xf m2scorer.tar.gz cd m2scorer ./m2scorer ../conll14_out.txt ../conll14st-test-data/noalt/official-2014.combined.m2
* 結果
Precision : 0.1873 Recall : 0.2637 F_0.5 : 0.1988
変に低いですね.出力を眺めると,Detokenizeまでされているので,単語のインデックスが合わなくなっているようです(CoNLL-2014の評価データのソースはtokenizeされている).そこで,Post-processingとしてspacyでtokenizeしました(これはちょっと適当です.ゆるして).その後もう一度評価すると
Precision : 0.4565 Recall : 0.2778 F_0.5 : 0.4045
ということで,RNNのベースラインくらいの性能でしょうか(よりも低い?).ちょっと雑なので正確な性能ではないかもしれませんが,今後のモデルの追加に期待です.
おわり
Gramformerが面白そうですねという記事でした.今の感じだと結構簡単に使えそうなので,この先どれくらい強いモデルが入るか?というところに期待です.この記事の情報はすぐに古くなると思いますが,使用感が伝わればと思います.
文法誤り訂正タスクの情報源
本記事は,GEC (Grammatical Error Correction) Advent Calendar 2021 の7日目の記事です.
はじめに
文法誤り訂正タスク(GEC, Grammatical Error Correction)は翻訳や情報抽出などのタスクに比べるとマイナータスクですが,最近は研究する人が増えている印象です.これに伴って,情報収集に役立つようなページの需要も高まっていると思いますので,いくつか紹介したいと思います.その後,個人的にこういう情報がまとまっていたら嬉しいなという気持ちを書きます.
既存の情報源
web上では,次のような資料が情報源として有用です.
NLP-progress
言語処理関係のタスクにおいてSoTAをまとめたリポジトリです.GECも含まれており,現状の性能が高いモデルを知ることができます.論文とコードのリンクが貼られているのもありがたいです.一方で,性能ベースで文献が追加されるため網羅性は低いです.基本的にSoTAな論文でないとマージされにくい印象があります.しかしながら,ターニングポイントというか,「この手法により性能が上がった」という流れを追うには十分だと思います.
サーベイ論文
GECはサーベイ論文がほとんど無い印象なのですが,2020年にサーベイ論文が出ています.2019年くらいまでのデータセットやGECモデル,評価指標について重要な研究がまとまっている印象です(まだ全部読んで無いんですけど...).定期的にサーベイ論文が出ると助かりますね.
私のブックマーク「自然言語処理による文法誤り訂正」
2018年までの話題について,重要な文献がまとまっています.日本語で書かれたGECのまとめ記事はこれしか無いのでは?というくらい貴重な記事だと思っています.pdf版とweb版があって,web版のほうが直接各種リンクに飛べるので便利です.
A Crash Course in Automatic Grammatical Error Correction
国際会議COLING2020におけるGECのチュートリアルです.GECのタスク説明から始まり,ルールベースの手法→SMT→DNNといった流れを追うことができます.個人的にはニューラル以降から参入した身なので,ルールベースのような古典的なアプローチを知ることも重要だよなと思うなどしました(古典的と表現していいのか分かりませんが).
著者もRoman Grundkiewicz, Christopher Bryant, Mariano Feliceと豪華です.例えば,Christopher Bryant氏とMariano Felice氏はERRANT([Felice+ 2016], [Bryant+ 2017])の著者です.また,Roman Grundkiewicz氏は多数のモデル提案系の論文に関わっていますし,システムの人手評価の研究([Grundkiewicz+ 2015])でも有名だと思います.
Chunngai/gec-papers
2019-2020あたりの期間について,GECの論文がまとまっています.論文の簡単な要約も書かれています.
GEC-Info(ステマ)
主にニューラル以降の手法について,論文やツールがまとまっています.性能は一切関係なく,手法別で分類するようなポリシーでまとめられています.論文が中心ですが,関連するツールや資料なども一部掲載されています.今後もジャンジャン追加予定です.分類形態も模索中です.
今後の展望(お気持ち)
実装
実装はどうしても分散するので,まとまった情報源というものはないですかね....翻訳でいうfairseqのようにGECの実装も同じフレームワークの元でまとまってくれたらなあとはよく思います.フレームワークが分散していると,何かを拡張したいときにそのフレームワークをそれぞれ学ぶ必要があるので,個人的には大変に感じます.例えば,コピー機構 [Zhao+ 2019]の公式実装は2年前のfairseqを直置き&書き換えて実装しているので,これをベースに拡張するには2年前のfairseqのアレコレを学ぶ必要があります.他方でGECToR [Omelianchuk + 2019]の公式実装に目をやるとAllenNLPを使っていて,やーなかなか大変だなと思うなどします.もちろんコードを整備して公開してくれているだけで神なんですが,人は欲張りなのでこういうことを思ってしまいます(僕だけなのかもしれない).実装力を鍛えねば....
何か統一的なもの,できないですかねえ 壁|▱°)
システム出力
他の要素としては,システム出力がまとまった場所があると嬉しいなと思います.気軽に色々な手法の出力を引っ張ってこれるようになると,分析が簡単に始められます.個人的には,難易度を考慮した評価尺度([Gotou+ 2020])を研究したとき,その手法からたくさんのシステム出力を必要としたこともあります.(ところで,たまにCoNLL-2014のシステム出力がGitHubに上がっているのを見ますが,データのライセンス的には大丈夫なんでしょうか?見方によっては改変しての再配布になりそうですが...)
おわり
情報がまとまっていれば嬉しいよね〜〜という話を書いてみました.
cLang-8データセット:ツールの動かし方の備忘録
ACL2021,"A Simple Recipe for Multilingual Grammatical Error Correction"の論文[Rothe+ 2021]で,cLang-8データセットが報告されました.cLang-8データセットはCleaned LANG-8 Corpusの呼称で,既に公開されているLang-8コーパス[Mizumoto+ 2011]のノイズを取り払うことで綺麗にしたようなデータセットです.
この記事では公開されているツールの動かし方の備忘録を残しておきます.cLang8は直接公開されておらず,Lang8からcLang8を作るようなスクリプトが公開されています.このスクリプトを使って,各自の環境でcLang8を作ることになります.基本的に公式のリファレンスの通りにやれば動きます.
手順
Official Repository:
1. Git Large File Storageをインストール
$ brew install git-lfs
でインストールした後,
$ git-lfs install
とやるとGit LFS initialized.と言ってくれるのでこれで完了.インストールできたか確認したいときは
$ git-lfs version
を実行してみる.
詳細は公式サイトを参照.
2. 公式リポジトリをclone
$ git clone https://github.com/google-research-datasets/clang8.git
3. Lang-8コーパスをダウンロード
以下のGoogle Formにアクセスして,必要事項を書き込んで送信.すぐにリンク付きのメールが送られてきます.リンクは2つ掲載されていますが,... raw format containing all the data up to 2010.と書いてあるほうのリンクを選びます.300MBくらいのzipなので,適当な手段でダウンロードして解凍.
解凍結果のディレクトリ構造が
├── lang-8-20111007-L1-v2.dat └── README
みたいになっていればok.
4. run.shを書き換える
cloneしたリポジトリの中にあるrun.shのLANG8_DIR=を編集します.
readonly LANG8_DIR='<INSERT LANG8 DIRECTORY HERE>' ↓ readonly LANG8_DIR='/lang-8-20111007-2.0/'
みたいな感じです.
5. run.shを実行
結構時間かかります(CPU次第?).
$ sh run.sh
6. 出力を確認
結果はoutput_data/に保存されます.各tsvの行数は公式リポジトリの記載の通りになるはずです.試しに英語のものを見てみて,
$ wc output_data/clang8_source_target_en.spacy_tokenized.tsv 2372119 56656257 267513611 output_data/clang8_source_target_en.spacy_tokenized.tsv
みたいになればokです.
出力にはソースとターゲットがタブ区切りになったペアが1行1ペアの形式で格納されます.
7. 蛇足
fairseqの学習などのためにソースとターゲットを別々のファイルにする場合は
$ cut -f 1 clang8_source_target_en.spacy_tokenized.tsv > train.src $ cut -f 2 clang8_source_target_en.spacy_tokenized.tsv > train.trg
などのように書けます.また,ERRANT [Felice+ 2016, Bryant+ 2017] を用いてreferenceのM2ファイルを作る場合,
$ errant_parallel -orig train.src -cor train.trg -out ref.m2
のように書けます.
エラーたち
いくつかエラーが出ました.
Could not find a version that satisfies the requirement ...
Could not find a version that satisfies the requirement thinc<8.1.0,>=8.0.8 (from versions: 6.12.0, 6.12.1, 7.0.0.dev1, 7.0.0.dev2, 7.0.0.dev6, 7.0.0, 7.0.1, 7.0.2, 7.0.3, 7.0.4, 7.0.5, 7.0.6, 7.0.8, 7.1.0, 7.1.1, 7.2.0.dev3, 7.2.0, 7.3.0, 7.3.1, 7.4.0.dev0, 7.4.0.dev1, 7.4.0.dev2, 7.4.0, 7.4.1, 8.0.0.dev0, 8.0.0.dev2, 8.0.0.dev4, 8.0.0a0, 8.0.0a1, 8.0.0a2, 8.0.0a3, 8.0.0a6, 8.0.0a8, 8.0.0a9, 8.0.0a11, 8.0.0a12, 8.0.0a13, 8.0.0a14, 8.0.0a16, 8.0.0a17, 8.0.0a18, 8.0.0a19, 8.0.0a20, 8.0.0a21, 8.0.0a22, 8.0.0a23, 8.0.0a24, 8.0.0a25) No matching distribution found for thinc<8.1.0,>=8.0.8 You are using pip version 10.0.1, however version 21.2.4 is available. You should consider upgrading via the 'pip install --upgrade pip' command.
原因:pipのバージョンが低いです.とりあえずupgradeしとけばいいので,run.shを
virtualenv -p python3 . source ./bin/activate pip install -r requirements.txt ↓ virtualenv -p python3 . source ./bin/activate pip install --upgrade pip pip install -r requirements.txt
のように追記して対応.
clang8/run.sh: 12: clang8/run.sh: source: not found
お使いのbashか何かにはsourceコマンドがありません.代わりにピリオドなら動きます.run.shを次のように編集
source ./bin/activate ↓ . ./bin/activate
ValueError: not enough values to unpack (expected 5, got 1)
このissueにもある通り,データが正確にcloneできていません.git-lfsが動いていない状態でcloneしたリポジトリのrun.shを実行した場合にこのエラーが出ます.git-lfsを正しくインストールしましょう.
参考文献
Rothe, S., Mallinson, J., Malmi, E., Krause, S., & Severyn, A. (2021). A Simple Recipe for Multilingual Grammatical Error Correction. arXiv preprint arXiv:2106.03830.
Mizumoto, T., Komachi, M., Nagata, M., & Matsumoto, Y. (2011, November). Mining revision log of language learning SNS for automated Japanese error correction of second language learners. In Proceedings of 5th International Joint Conference on Natural Language Processing (pp. 147-155).
Felice, M., Bryant, C., & Briscoe, E. (2016). Automatic extraction of learner errors in ESL sentences using linguistically enhanced alignments. Association for Computational Linguistics.
Bryant, C., Felice, M., & Briscoe, E. (2017, July). Automatic annotation and evaluation of error types for grammatical error correction. Association for Computational Linguistics.
論文メモ:ACL2017, Automatic Annotation and Evaluation of Error Types for Grammatical Error Correction
@inproceedings{bryant-etal-2017-automatic,
title = "Automatic Annotation and Evaluation of Error Types for Grammatical Error Correction",
author = "Bryant, Christopher and
Felice, Mariano and
Briscoe, Ted",
booktitle = "Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = jul,
year = "2017",
address = "Vancouver, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/P17-1074",
doi = "10.18653/v1/P17-1074",
pages = "793--805",
概要
文法誤り訂正の評価のためのツールとしてERRANTを提案しました.Felice(2016)らのアライメント手法をベースに,エラータイプを付与する手法を提案しています.また,CoNLL-2014 Shared Taskの参加システムを再評価し,訂正の傾向について分析しました.
この論文の立ち位置
この論文では,誤り訂正の自動アノテーションと自動評価を行うツールであるERRANTを提案しています.あくまでもERRANTを提唱したのはこの論文ですが,手法としては2本の論文が合わさった成果であり,この論文は2本目の立場です.
1本目はFelice et. al(2016)の研究で,原文と訂正文から自動でアライメントをとって,訂正情報を抽出する手法を提案しています.2本目はこの論文で,抽出できた訂正情報からエラータイプを付与する方法と,評価値の算出方法を提案しています.1本目の詳細は以下にも解説してあります. gotutiyan.hatenablog.com
手法
この論文では,訂正情報を入力とし,エラータイプを出力とする分類器を提案しました.特に,50個程度のルールに基づいたルールベースな分類器を用いています.基本的には品詞に基づいてエラータイプを付与しますが,語順やスペル誤りといった品詞に依存しないエラータイプも考慮したルールになっています.例えば,「小文字化すると一致するか?」のルールでは,訂正情報がOrthography(例:we → We)のエラータイプに分類できるかどうかが分かります.
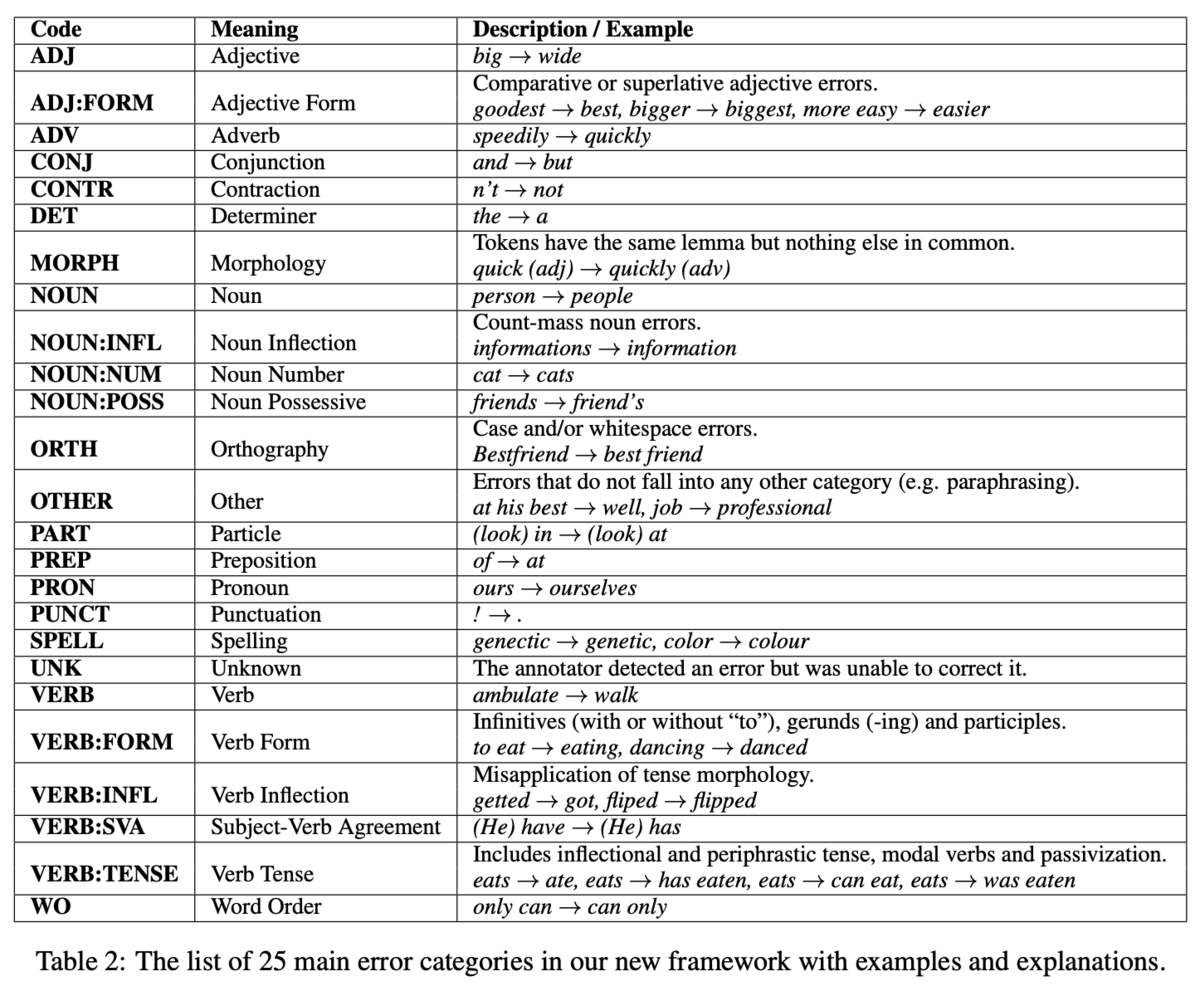
エラータイプは25種類を定義します(Table 2).これらのエラータイプは,それが置換,削除,挿入のいずれかを表す文字列R:,U:,M:を接頭辞として用いることができます.例えば,名詞に関する置換の誤りはR:NOUNと表すことができます.また,Rのみに注目すれば置換する誤り全体の評価が行えるし,NOUNのみに注目すれば,置換・削除・挿入を考慮せずに名詞全体の評価が行えるため,柔軟な視点で評価できることが利点です.
このルールベースな手法には説明性や一貫性があると主張しています.先行研究には機械学習に基づいてエラータイプを分類するような手法も存在します.しかし,学習に用いるデータが大量に必要なことや,あるデータセットで学習した分類器は,ドメインの違いから他のデータセットでは正しく分類できない可能性もあります.一方,ルールベースな手法では,言語情報のみを用いてエラータイプを付与するので,データセットに非依存に適用できます.
エラータイプ分類器の評価
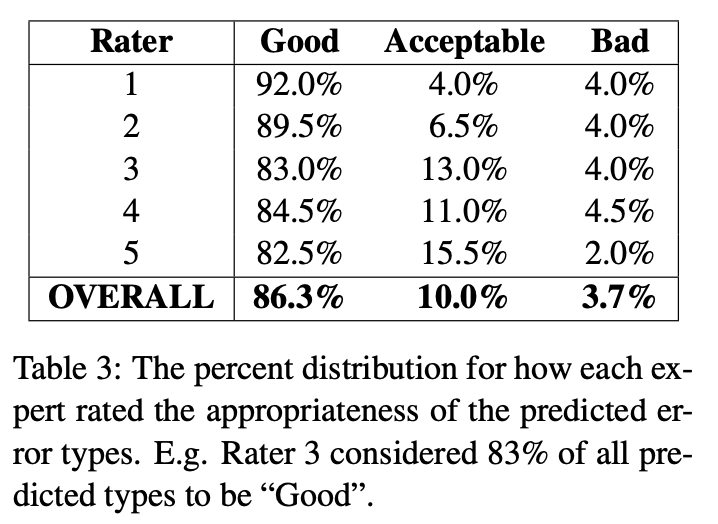
事前実験として,エラータイプ分類器の性能を人手で評価しています.具体的には,訂正情報と分類されたエラータイプを評価者に見せて,「良い」,「許容できる」,「悪い」の3段階で評価しました.「許容できる」は,付与されたエラータイプが適切ではあるが最適ではないと判断したときの評価です.
5人の評価者に実験してもらったところ,95%以上が「良い」または「許容できる」という結果でした(Table 3).また,評価者間のカッパスコアは0.724であり,評価者間でもある程度一致することを示しました.また,「悪い」と評価された事例を分析すると,その主な原因はPOSタグのエラーや構文解析のエラーが原因だったようです.この結果から,ルールベースなエラータイプ分類器は十分有効だと結論づけています.
エラータイプ別の性能評価
25種類のエラータイプを考慮した評価指標は存在しないので,新たに提案しています.評価は訂正情報のオーバーラップを見るだけで済みます.Felice et. al (2016)の手法を使えば,「原文ー正解文」と「原文ーシステムの訂正文」の間でそれぞれ訂正情報が自動で獲得できます.その後,「原文ー正解文」と「原文ーシステムの訂正文」の訂正情報のオーバーラップを見ることで評価できます.この指標ではTP,FP, FNを定義することができます.それぞれの指標は次のとおりです.
- TP:単語インデックスのスパンと訂正前後の文字列が一致するもの
- FP:「原文ーシステムの訂正文」の訂正情報であって,「原文ー正解文」の訂正情報にないもの
- FN:「原文ー正解文」の訂正情報であって,「原文ーシステムの訂正文」の訂正情報にないもの
また,エラータイプでグルーピングすることにより,エラータイプ別の評価も計算できます.
Gold ReferenceとAuto Reference
先ほど述べたように,評価には「原文ー正解文」と「原文ーシステムの訂正文」の2つの訂正情報を必要としますが,両者の訂正情報が異なる基準で付与されていれば,正しく評価が行えません.例えば,「原文ー正解文」は人がアノテートした訂正情報で,「原文ーシステムの訂正文」は ERRANTが自動でアノテートした訂正情報である場合が該当します.そこで,両者をERRANTの基準に合わせるために,既存の訂正情報をERRANTの基準に変換する機能を提供しています.
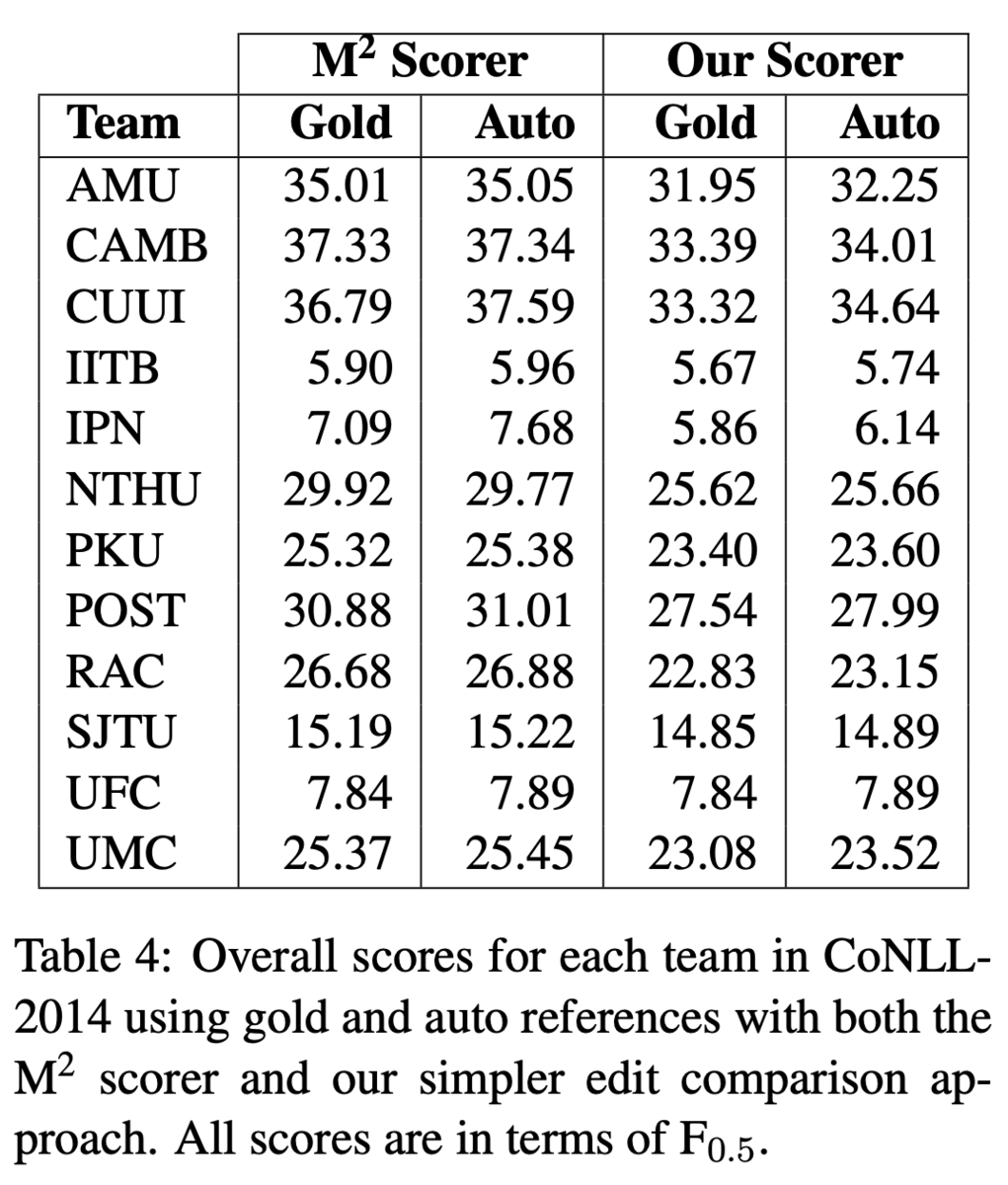
また,再アノテーションの結果が人のアノテートの結果と遜色ないことを示しました.具体的には,CoNLL-2014 Shared TaskのテストデータをERRANTで再アノテートし,これをreferenceとして参加システムを評価しました.Table 4では人がつけた既存のアノテーションをGold,ERRANTで再アノテートしたものをAutoとしています.スコアに大きな違いがないことから,ERRANTのアノテーションは人のアノテーションに遜色ないという結論です.
M2スコアラとの違い
Table 4からもわかるように,ERRANTの評価値は,M2スコアラと比較してF_0.5が低めに出る傾向があります.しかし,これはERRANTが性能を過小評価しているわけではなく,M2スコアラが過大評価しているからだと分析しています.M2スコアラはその由来がMax-Matchであるように,True Positiveができるだけ多く,かつFalse Positiveができるだけ少なくなるように振る舞うためです.
CoNLL-2014 Shared Taskにおける再評価
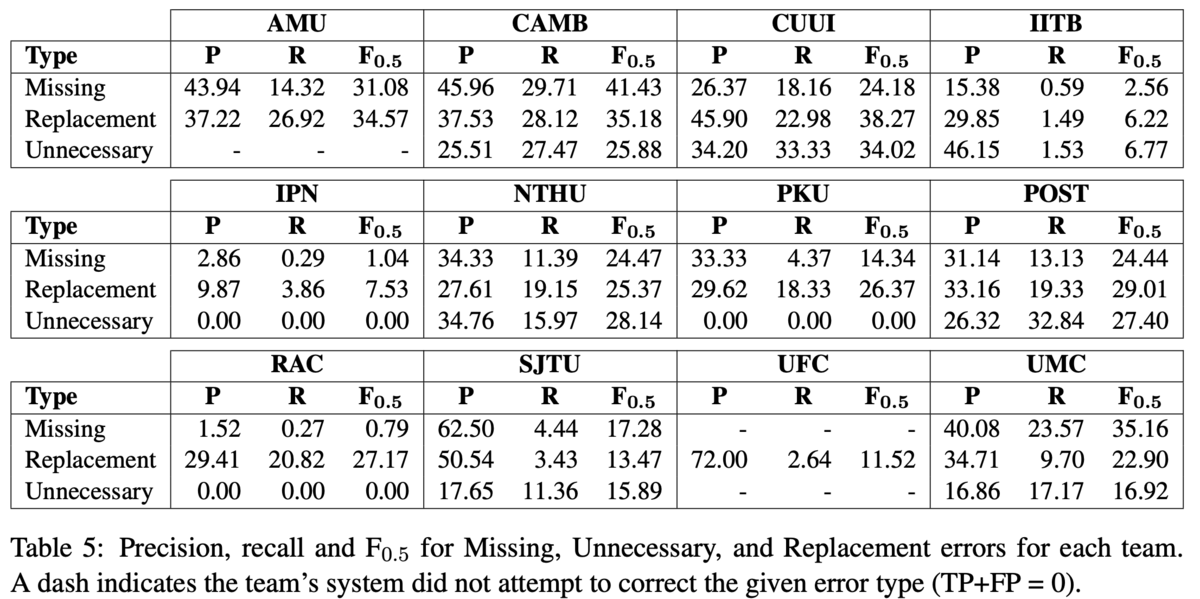
ERRANTによる自動アノテーションと自動評価尺度を用いて,CoNLL-2014の参加システムを再評価しました.Table 5では,訂正の種類が挿入,削除,置換の3種類についてそれぞれ評価を行い比較しました.この結果,システムによってかなり訂正の傾向が異なることがわかりました.
最も注目すべき結果として,AMU, IPN, PKU, RAC, UFCの5チームは,削除すべき誤りを一切解けていないということでした.この理由として,UFCルールベースの手法が削除の訂正を考慮していないことや,SMTベースの手法が削除の訂正をうまく学習できないことだと分析しています.一方,CUUIの手法は削除すべき誤りを最も訂正できていました.
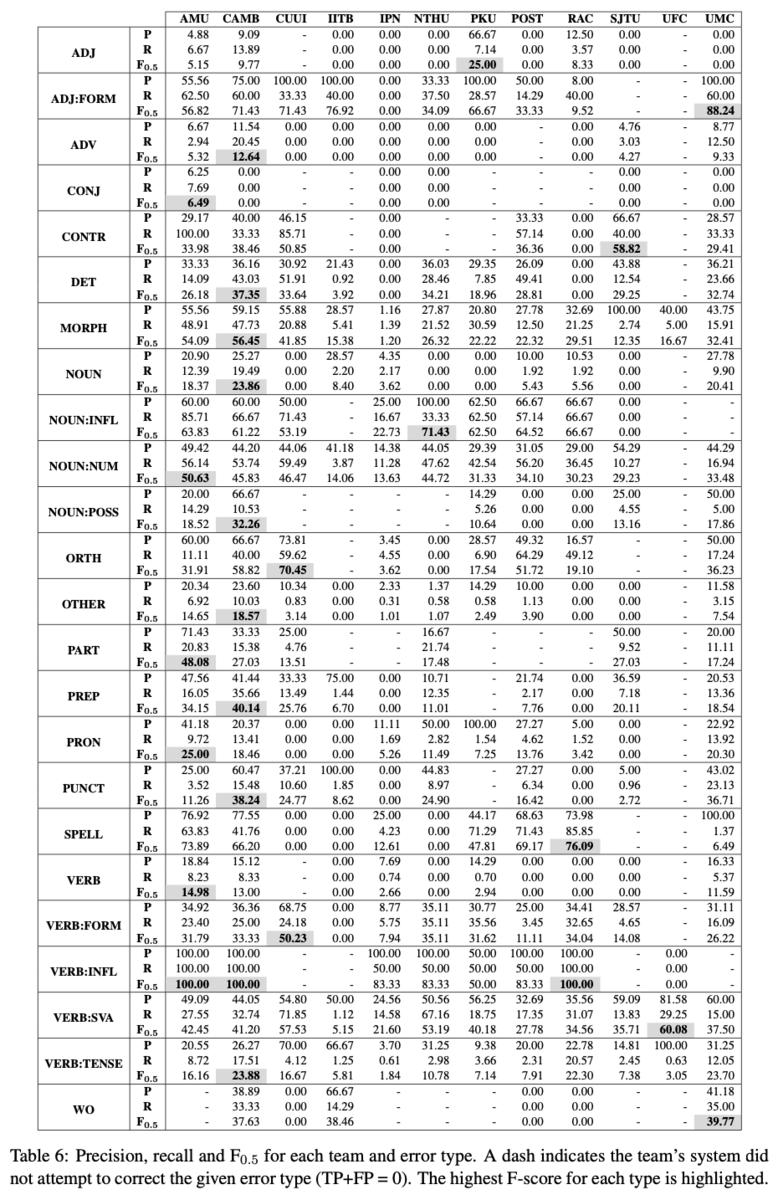
また,全てのエラータイプについて各システムのPrecison,Recall,F_0.5を分析しました(Table 6).まず分かるのは,IITB,IPN,POST3以外のシステムは,少なくとも1つのエラータイプにおいて最高性能を達成しています.これは,手法が異なれば解けるエラータイプが異なることを示しています.他にも,より粒度が細かいエラータイプに注目すると,それぞれの手法が得意なことが詳細に分析できました(Table 7, 本記事では割愛).
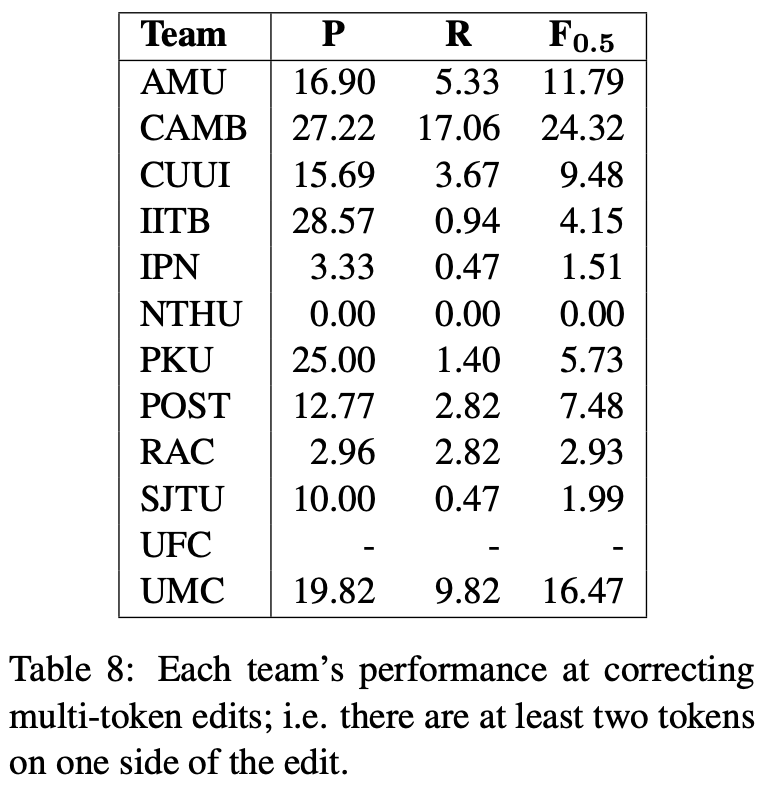
さらに,マルチトークンな訂正に限定した性能も評価しました(Table 8).マルチトークンな訂正とは,訂正前や訂正後のいずれかのトークン数が2以上になる訂正です.Table 8の結果からは,システムの多くはマルチトークンな訂正を苦手としていることがわかりました.今後はさらに結果の流暢さが求められることを考慮すると,このような誤りを解くためにはさらに工夫が必要だと分析しています.
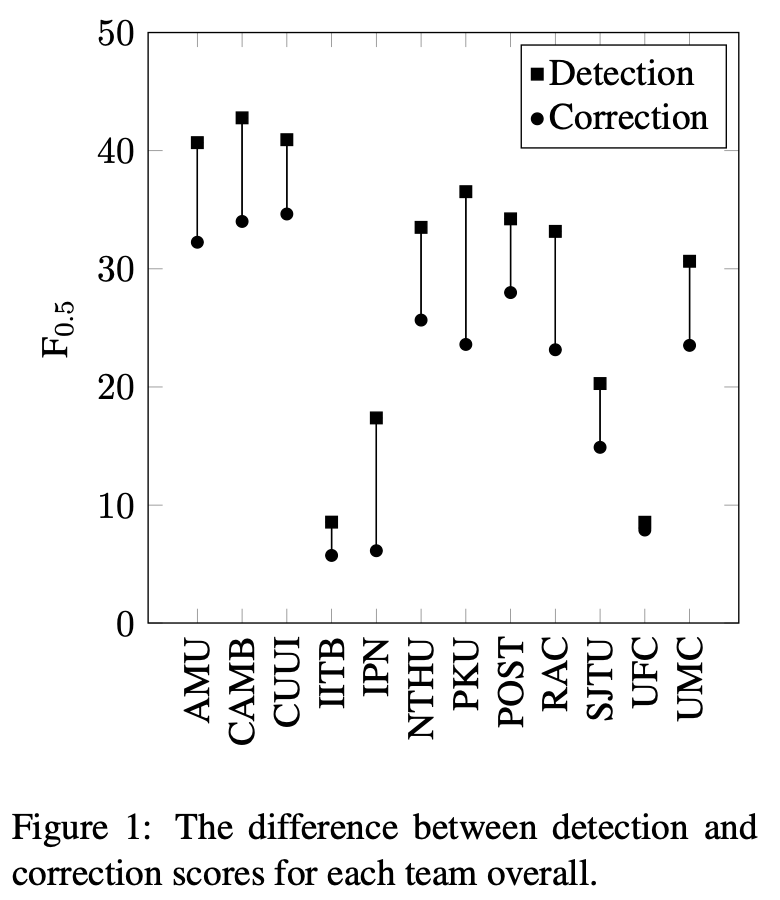
最後に,誤り検出の精度と誤り訂正の性能を比較しています(Figure 1).ここで,誤り検出の性能は,訂正後の文字列は気にせず,単語インデックスのスパンが正しく取れているかのみを測れば計算できます.Figure 1の結果からは,検出の性能が高いからといって訂正の性能も高いとは限らないことが分かります.また逆に,訂正の性能が低くても,検出の性能が高ければ学習者へのヒントとなる情報を提示する役割は果たせるとしています.
ERRANTの動かし方
実装はこちら: github.com
インストール:
python3 -m venv errant_env source errant_env/bin/activate pip3 install -U pip setuptools wheel pip3 install errant python3 -m spacy download en
ツールは3つの機能を提供しています.
errant_parallel -orig <orig_file> -cor <cor_file1> [<cor_file2> ...] -out <out_m2>
生文から訂正情報を自動で獲得します.入力は原文(-orig)とシステム出力文(-cor)の2つで,出力はM2フォーマットの訂正情報です.-corには複数のファイルを与えることができます.この場合,M2フォーマットの末尾である<annotator id>のところが0, 1, 2, ...とナンバリングされて記録されます.
errant_m2 {-auto|-gold} m2_file -out <out_m2>
既存のM2形式のアノテート情報を,ERRANT の仕様に沿ったものに変換します.-goldでは,アライメントはそのままに,エラータイプのみをERRANTが定義するものに変換します.-autoでは,アライメントやエラータイプを全てERRANTが再計算します.
errant_compare -hyp <hyp_m2> -ref <ref_m2> -ds -cat {1,2,3}
評価値を計算します.入力はM2フォーマットで表されたモデルの訂正情報(-hyp)と正解の訂正情報(-ref)です.-dsや-catは,評価値の出力をどのように行うかを指定します.-dsはSpan-based Detectionの評価値,-dtはToken-based Detectionの評価値を出力します.デフォルトは-scで,Span-based Correctionです.この3種類の違いは以下の表にあります.Detectionは訂正のスパン(単語インデックスのレンジ)のみで判断し,Correctionは訂正後の文字列まで見ます.

-cat {1,2,3}は,エラータイプの粒度を表します.-cat 1は置換誤り,不足誤り,余剰誤りの3種類の評価値のみ出力,-cat 2はエラータイプ25種類のみについて出力,-cat 3は各エラータイプについて置換,不足,余剰(最大55種類)のそれぞれの評価値を出力します.
参考文献
Felice, Mariano, Christopher Bryant, and Edward Briscoe. "Automatic extraction of learner errors in ESL sentences using linguistically enhanced alignments." Association for Computational Linguistics, 2016.