GECの論文紹介:EMNLP2021
本記事は,GEC (Grammatical Error Correction) Advent Calendar 2021 の11日目の記事です.
はじめに
国際会議EMNLP2021にフォーカスし,GEC(Grammatical Error Correction,文法誤り訂正)に関する論文で特に気になったものを3件紹介します.本当はGEC関係の論文を全て紹介するつもりでしたが,文字数がえらいことになるので3件にしました.読者の多くは既に内容を知っている気がするので,内容は簡単に済ませて,個人的な考えを多めに盛り込むような構成になっていると思います.
本記事の記述の中には厳密でない表現があるかもしれませんが,ご容赦ください.
1. Is this the end of the gold standard? A straightforward reference-less grammatical error correction metric
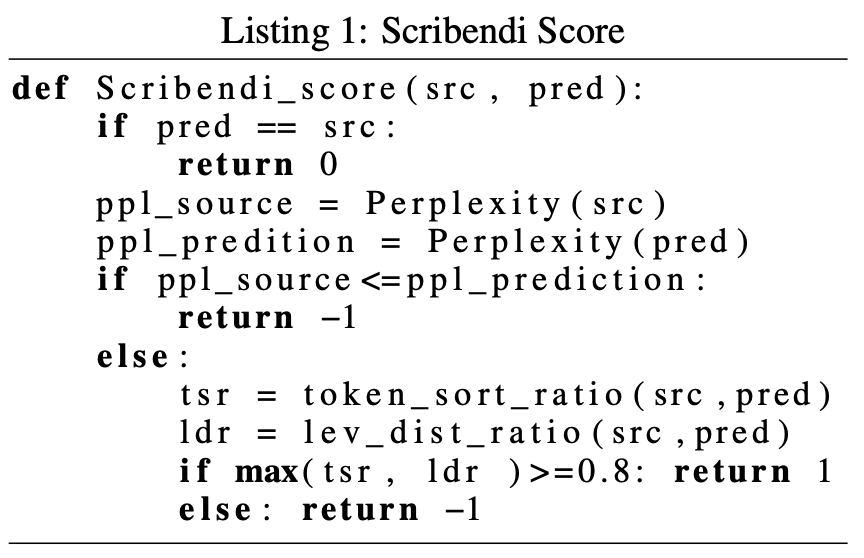
参照なし評価尺度を提案した論文です.システム出力文を0(訂正なし),1(改善した),-1(悪化した)の3値で評価します.出力文それぞれに対してこの評価値を計算し,合計がシステムの評価値になります.つまり,文数をとすると評価値は
]のレンジになります.
改善した/悪化した ことは,Listing 1に示されたプロセスで判断します.はじめに一致判定を行い,次にPPLの値を見ます.PPLの値は低いほど良いので,sourceよりpredictionのほうがPPLの値が高いとき,それは悪化したと判断します(-1が返る).最後に,token_sort_ratioとlevenshtein-distance_ratioのうち,いずれかが0.8以上であれば改善したと判断し,そうでなければ悪化したと判断します.token_sort_ratioは,2つの文に同じトークンが同じ数含まれているほど高くなるような一致度です.levenshtein_distance_ratioは,で定義される一致度です(
は編集距離.ただし,置換コストが2,挿入・削除のコストが1).
結果としては,人手相関が高いこと,同じフレーズを繰り返すような文をちゃんと悪いと言えることを示しています.
個人的には,3値分類というざっくりとした基準での評価であるにも関わらず,人手相関が0.8前後あることに驚きました.人手評価に近いランキングを得ることだけを目標にするなら,案外ざっくりでも良いのかもしれません.一方で,学術的な議論をする上で,モデルが何を解けて何を解けないかを分析することを考えると,この評価指標は使いにくいと思います.
疑問点としては,流暢な訂正がちゃんと良いと言えるか?というところが気になります.token sort ratioやlevenshtein distance ratioは,表層的に近いものを評価する尺度になっていると思います.一方で,流暢な訂正はそれなりに大きな書き換えになることが言われている(JFLEGの論文をreferしておきます)と思いますが,ratioによる評価は表層的に近いものを認めるようになっているので,流暢な訂正を悪いと言ってしまいそうな気もします(maxを取る方法や0.8という閾値が絶妙で,うまくやっているのかもしれません).
あと気になったのは,人がアノテーションした正解文をpredだと思って提案評価尺度に入れると,全部1(改善した)になるのでしょうか?そのうちやってみたいと思います.
おまけ:Levenshtein distance ratioの実装
import numpy as np def lev_dist_ratio(src: str, pred:str) -> float: len_src = len(src) len_pred = len(pred) dp = np.zeros((len_src+1, len_pred+1)) for i in range(1, len_src+1): dp[i][0] = i for j in range(1, len_pred+1): dp[0][j] = j for i in range(1, len_src+1): for j in range(1, len_pred+1): cost = 0 if src[i-1] != pred[j-1]: cost = 2 # 置換コストは2 dp[i][j] = min( dp[i-1][j-1] + cost, min(dp[i-1][j] + 1, dp[i][j-1] + 1) ) return 1 - dp[len_src][len_pred] / (len_src + len_pred)
2. LM-Critic: Language Models for Unsupervised Grammatical Error Correction
GECの教師なしアプローチを提案しています.ソースコード修復タスクのために提案されたBIFIという手法をGECに適用しました.また,BIFIは文が正しいかどうか見極めるCriticの機構を必要とするので,GECのためのCriticであるLM-Criticも提案しています.
GECにおけるBIFIは,誤りを生成するbreakerと,誤りを訂正するfixerが相互に働いて学習を進めます.最終的にはfixerをGECモデルとして使うことになります.BIFIは,以下の(8)から(11)式を1サイクルとし,このサイクルを回すことで学習を進めます.つまり,breakerが作った誤りデータを元にfixerが学習し,fixerが作った正しいデータでbreakerが学習し,breakerが作った誤りデータでfixerが学習し・・・というプロセスを繰り返すことになります.いわゆるGAN的な構造だとは思いますが,お互いにデータを作るだけでパラメータの更新には直接関与しない点がちょっと違うと思います.
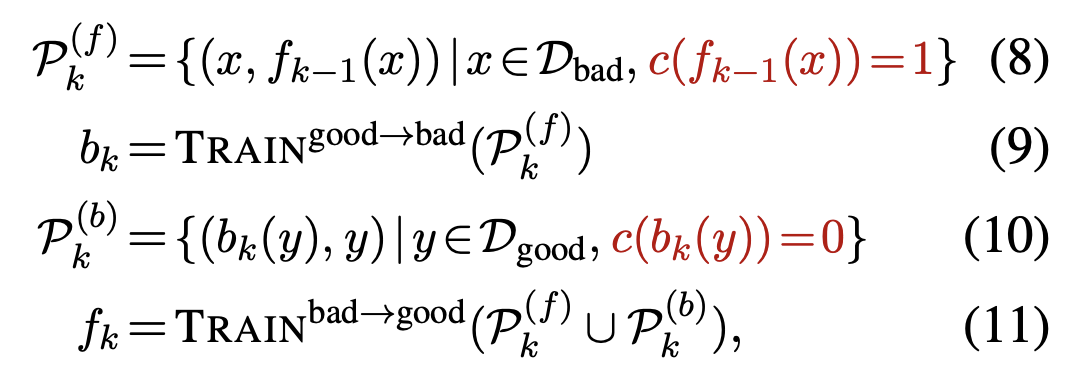
それから,breakerが生成した誤り文・fixerが訂正した文が,本当に誤っているのか ・正しいのかを判定するLM-Criticも提案しています.上の式では赤文字で表されており,xを文として,c(x) = 1(正しい文である)or 0(誤り文である)を返します.手法としては,文字レベルや単語レベルの編集を行い,xの近傍の文を数百文生成します.それから,近傍の文,それから入力であるxのPPLをそれぞれ計算し,xのPPLが最も低ければ1(正しい),そうでなければ0(誤り)として判断します.つまり,xが正しい(grammatical)であると結論づけるためには,全ての近傍の文にPPLで勝つ必要があります.
結果,CoNLL2014のF0.5で55.5を達成しました.教師なしではだいぶ高い性能だと思います.教師ありの設定では,F0.5が65.8とGECToRを少し上回るぐらいの性能を示したようです.
これを研究室の論文紹介で話したとき,「正解と誤りのペアを作っているなら教師ありなのでは」という意見があって,確かに教師なしの定義とはなんだろうと思ってしまいました.この論文では「人が作った正解データを使うかどうか」が教師あり/なしの基準になっています.従来のLMで頑張るような手法(Bryant+ 2018, Alikaniotis+ 2019など)と比べると,(擬似データのみとはいえ)誤り文と正しい文のペアを与えている時点で多少有利な設定なのかなと思いました.それから,BIFIはbreakerとfixerが交互に高め合えることが利点ですが,論文ではこれを1ラウンドしか回していません.おそらく(8)から(11)式をひと舐めして終わりだと思います.せっかくサイクルを回せるような手法になっているので,もっと回したら良いのにと思いました.回すとむしろ悪化したのかもしれません...?
一方で,近傍の文とPPLを比べるLM-Criticの発想はとても興味深いものでした.近傍の作り方は色々考えられるので,工夫すればもっと良い指標になるかもしれません.また,今回はPPLが最も低い文(だけ)がGrammaicalだ,というハードなCritic設計になっていますが,ソフトな基準にすれば使いどころが増えるのかなと思いました.例えば,PPLの低さで10位以内に入っていればOKだとか,PPL低さの順位を連続値に変換して扱うとかは考えられます.BIFIに組み込むことを考えるとハードな設計であるべきですけども.
また,この研究でのBIFIはほぼ擬似誤り生成手法と見て良いと思っています.今までの擬似データ生成手法と異なるのは,生成した擬似誤り文が本当に誤りなのかを,LM-Criticでちゃんと判断しているところです.擬似誤り生成はよく取り組まれていますが,生成した擬似誤りは全部使うのが普通だと思います.一方,BIFIではその質をちゃんとLM-Criticで判断して,質の悪い擬似誤りは捨てます.この点はけっこう重要な視点かもしれないと感じました(先行研究でこういうのはなかった気がするのですが,ありましたっけ?質の悪いデータを改善するという意味ではMita+ 2020は近そうです).
3. Multi-Class Grammatical Error Detection for Correction: A Tale of Two Systems
GECにGED(Detection)を本気で取り入れたような論文です.ICLR2020に採択されたELECTRAをベースにしたGEDシステムを提案し,Transformerに追加でEncodeしたり,リランキングに使ったりします.GEDはトークン単位でmulti-class({2, 4, 25, 55}-class)な分類をします.例えば,2-classは正解/誤りの2値分類ですが,4-classだと誤りラベルが置換/挿入/削除まで細分化します(本記事では載せませんが,詳細はTable 1).
GEDの情報は,Transformerのアーキテクチャを拡張したMulti-Encoderに使われます(Figure 1).
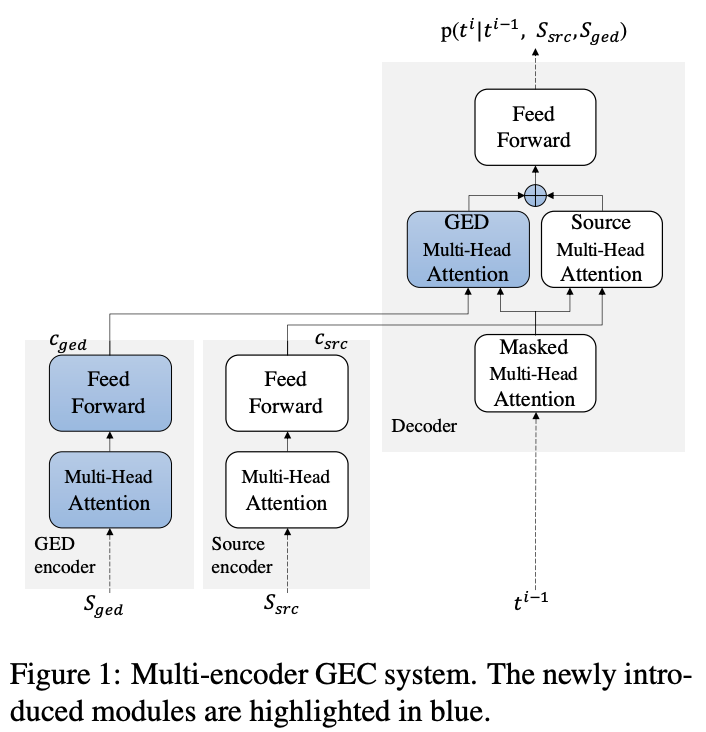
また,リランキングにも使われます.具体的には,GEDシステムが推定した検出ラベルを正解とみなし,それと最も一致するようなGECシステムの出力を選びます(GECシステムの出力は検出ラベルではなく文ですので,入力文とのアライメントを取って検出ラベルに変換します).一致度にはハミング距離を使っているようです.
個人的には,検出の情報を明示的に与えることにどれくらい意味があるのかなと思っていました.検出できないと訂正できないので,GECシステムも既に検出の情報を考慮しているはずです.このことから,それに加えてさらに検出の情報を与えても効果は薄いのではと思っていました.論文ではこの辺りちゃんと実験がされていて,「検出情報のオラクルを用いたときに訂正がどれくらいできるか」が調べられています(ここでは載せませんが,Table 2).この実験の結果は,検出の情報がちゃんと取れているとすると訂正の精度も飛躍的に上がるということが示唆されています.検出の情報を明示的に与えることには案外意味がありそうだという気持ちになりました.
それから,現状のコミュニティでは,GECはみんなやっていますが,GEDを極めるような研究はあまり無いように思います.すぐに思いつくのはNagata+ 2021やKaneko+ 2019あたりでしょうか.でもGECに比べると圧倒的に少ない印象です.タスク設定としてはGECよりもGEDの方が明らかに解きやすいので,もっと取り組まれても良いような気はしました.GEDを極めて高い精度で検出できるようになれば,GECも大きく進化するかもしれません.
この3本を読んで
今回は3本を紹介しました.そのうち2本はモデル提案系の話ですが,「良い訂正文とは何か」をちゃんと評価する機構を採用しているのが印象的でした.2本目で紹介した論文ではLM-Criticが評価方法に対応していて,他のことにも使えそうな気がします.3本目で紹介した論文ではリランキングの方法を提案していました.リランキングはGECモデルの確率とは別の評価尺度で再評価していると捉えられます.ですので,リランキング手法は実質参照なし評価手法ぐらいに思っていて,注目してきたいと思っています.
Reference
Islam, Md Asadul, and Enrico Magnani. "Is this the end of the gold standard? A straightforward reference-less grammatical error correction metric." Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021
Yasunaga, Michihiro, Jure Leskovec, and Percy Liang. "LM-Critic: Language Models for Unsupervised Grammatical Error Correction." Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021.
Yuan, Zheng, et al. "Multi-Class Grammatical Error Detection for Correction: A Tale of Two Systems." Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021.