論文メモ:ACL2017, Automatic Annotation and Evaluation of Error Types for Grammatical Error Correction
@inproceedings{bryant-etal-2017-automatic,
title = "Automatic Annotation and Evaluation of Error Types for Grammatical Error Correction",
author = "Bryant, Christopher and
Felice, Mariano and
Briscoe, Ted",
booktitle = "Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = jul,
year = "2017",
address = "Vancouver, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/P17-1074",
doi = "10.18653/v1/P17-1074",
pages = "793--805",
概要
文法誤り訂正の評価のためのツールとしてERRANTを提案しました.Felice(2016)らのアライメント手法をベースに,エラータイプを付与する手法を提案しています.また,CoNLL-2014 Shared Taskの参加システムを再評価し,訂正の傾向について分析しました.
この論文の立ち位置
この論文では,誤り訂正の自動アノテーションと自動評価を行うツールであるERRANTを提案しています.あくまでもERRANTを提唱したのはこの論文ですが,手法としては2本の論文が合わさった成果であり,この論文は2本目の立場です.
1本目はFelice et. al(2016)の研究で,原文と訂正文から自動でアライメントをとって,訂正情報を抽出する手法を提案しています.2本目はこの論文で,抽出できた訂正情報からエラータイプを付与する方法と,評価値の算出方法を提案しています.1本目の詳細は以下にも解説してあります. gotutiyan.hatenablog.com
手法
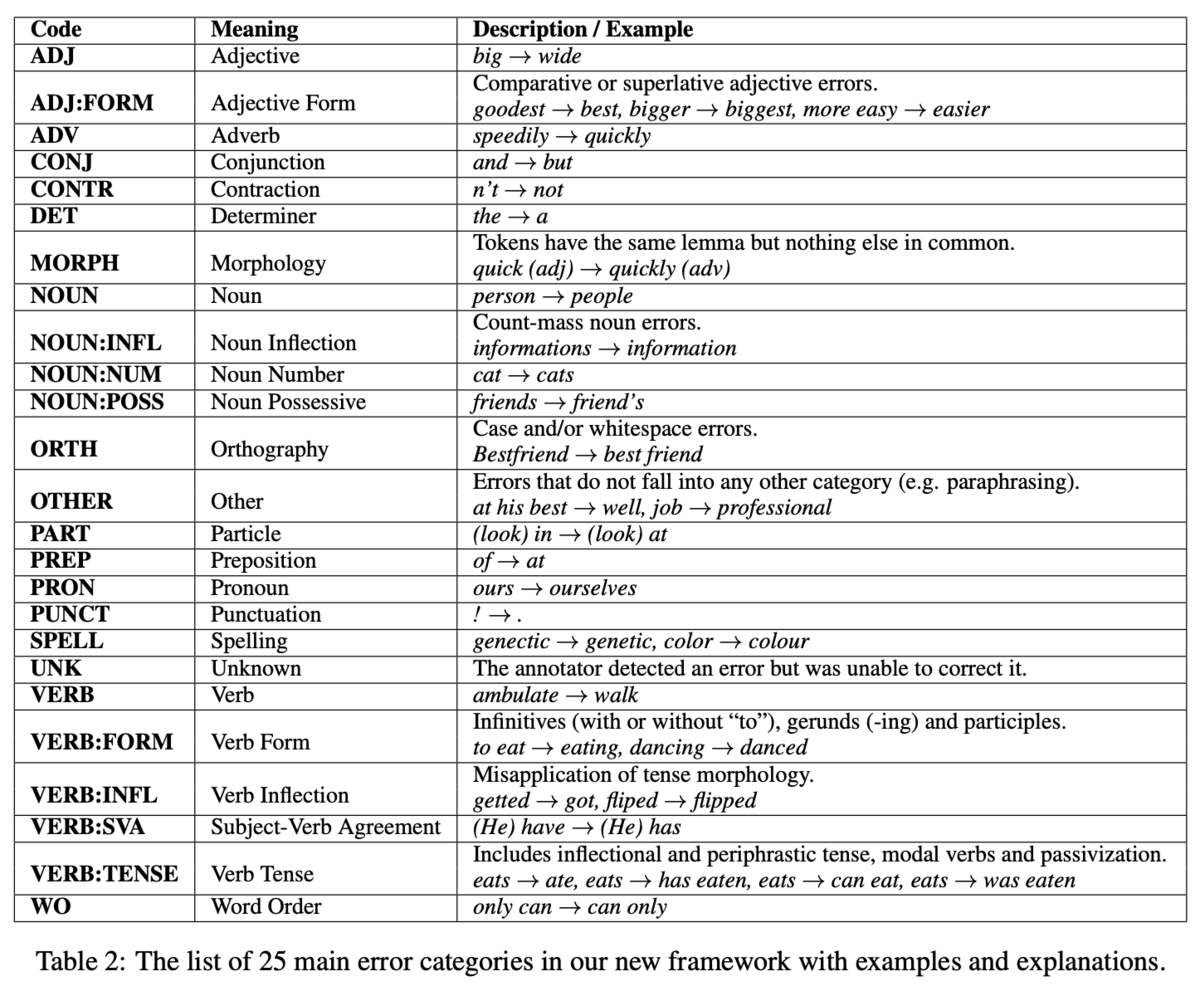
この論文では,訂正情報を入力とし,エラータイプを出力とする分類器を提案しました.特に,50個程度のルールに基づいたルールベースな分類器を用いています.基本的には品詞に基づいてエラータイプを付与しますが,語順やスペル誤りといった品詞に依存しないエラータイプも考慮したルールになっています.例えば,「小文字化すると一致するか?」のルールでは,訂正情報がOrthography(例:we → We)のエラータイプに分類できるかどうかが分かります.
エラータイプは25種類を定義します(Table 2).これらのエラータイプは,それが置換,削除,挿入のいずれかを表す文字列R:,U:,M:を接頭辞として用いることができます.例えば,名詞に関する置換の誤りはR:NOUNと表すことができます.また,Rのみに注目すれば置換する誤り全体の評価が行えるし,NOUNのみに注目すれば,置換・削除・挿入を考慮せずに名詞全体の評価が行えるため,柔軟な視点で評価できることが利点です.
このルールベースな手法には説明性や一貫性があると主張しています.先行研究には機械学習に基づいてエラータイプを分類するような手法も存在します.しかし,学習に用いるデータが大量に必要なことや,あるデータセットで学習した分類器は,ドメインの違いから他のデータセットでは正しく分類できない可能性もあります.一方,ルールベースな手法では,言語情報のみを用いてエラータイプを付与するので,データセットに非依存に適用できます.
エラータイプ分類器の評価
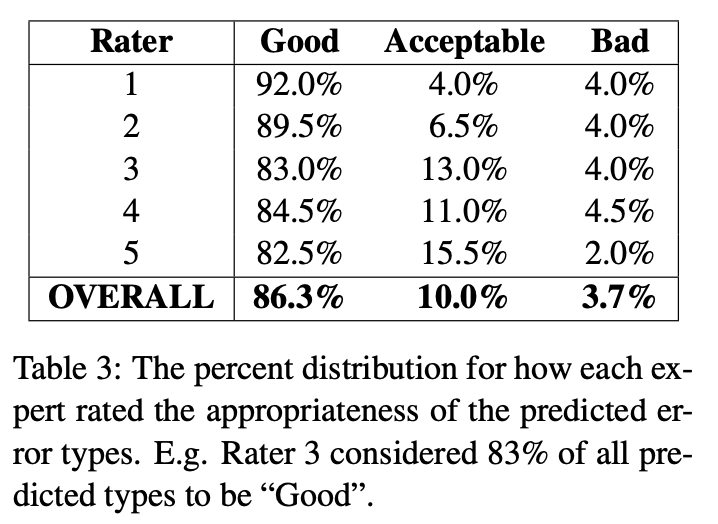
事前実験として,エラータイプ分類器の性能を人手で評価しています.具体的には,訂正情報と分類されたエラータイプを評価者に見せて,「良い」,「許容できる」,「悪い」の3段階で評価しました.「許容できる」は,付与されたエラータイプが適切ではあるが最適ではないと判断したときの評価です.
5人の評価者に実験してもらったところ,95%以上が「良い」または「許容できる」という結果でした(Table 3).また,評価者間のカッパスコアは0.724であり,評価者間でもある程度一致することを示しました.また,「悪い」と評価された事例を分析すると,その主な原因はPOSタグのエラーや構文解析のエラーが原因だったようです.この結果から,ルールベースなエラータイプ分類器は十分有効だと結論づけています.
エラータイプ別の性能評価
25種類のエラータイプを考慮した評価指標は存在しないので,新たに提案しています.評価は訂正情報のオーバーラップを見るだけで済みます.Felice et. al (2016)の手法を使えば,「原文ー正解文」と「原文ーシステムの訂正文」の間でそれぞれ訂正情報が自動で獲得できます.その後,「原文ー正解文」と「原文ーシステムの訂正文」の訂正情報のオーバーラップを見ることで評価できます.この指標ではTP,FP, FNを定義することができます.それぞれの指標は次のとおりです.
- TP:単語インデックスのスパンと訂正前後の文字列が一致するもの
- FP:「原文ーシステムの訂正文」の訂正情報であって,「原文ー正解文」の訂正情報にないもの
- FN:「原文ー正解文」の訂正情報であって,「原文ーシステムの訂正文」の訂正情報にないもの
また,エラータイプでグルーピングすることにより,エラータイプ別の評価も計算できます.
Gold ReferenceとAuto Reference
先ほど述べたように,評価には「原文ー正解文」と「原文ーシステムの訂正文」の2つの訂正情報を必要としますが,両者の訂正情報が異なる基準で付与されていれば,正しく評価が行えません.例えば,「原文ー正解文」は人がアノテートした訂正情報で,「原文ーシステムの訂正文」は ERRANTが自動でアノテートした訂正情報である場合が該当します.そこで,両者をERRANTの基準に合わせるために,既存の訂正情報をERRANTの基準に変換する機能を提供しています.
また,再アノテーションの結果が人のアノテートの結果と遜色ないことを示しました.具体的には,CoNLL-2014 Shared TaskのテストデータをERRANTで再アノテートし,これをreferenceとして参加システムを評価しました.Table 4では人がつけた既存のアノテーションをGold,ERRANTで再アノテートしたものをAutoとしています.スコアに大きな違いがないことから,ERRANTのアノテーションは人のアノテーションに遜色ないという結論です.
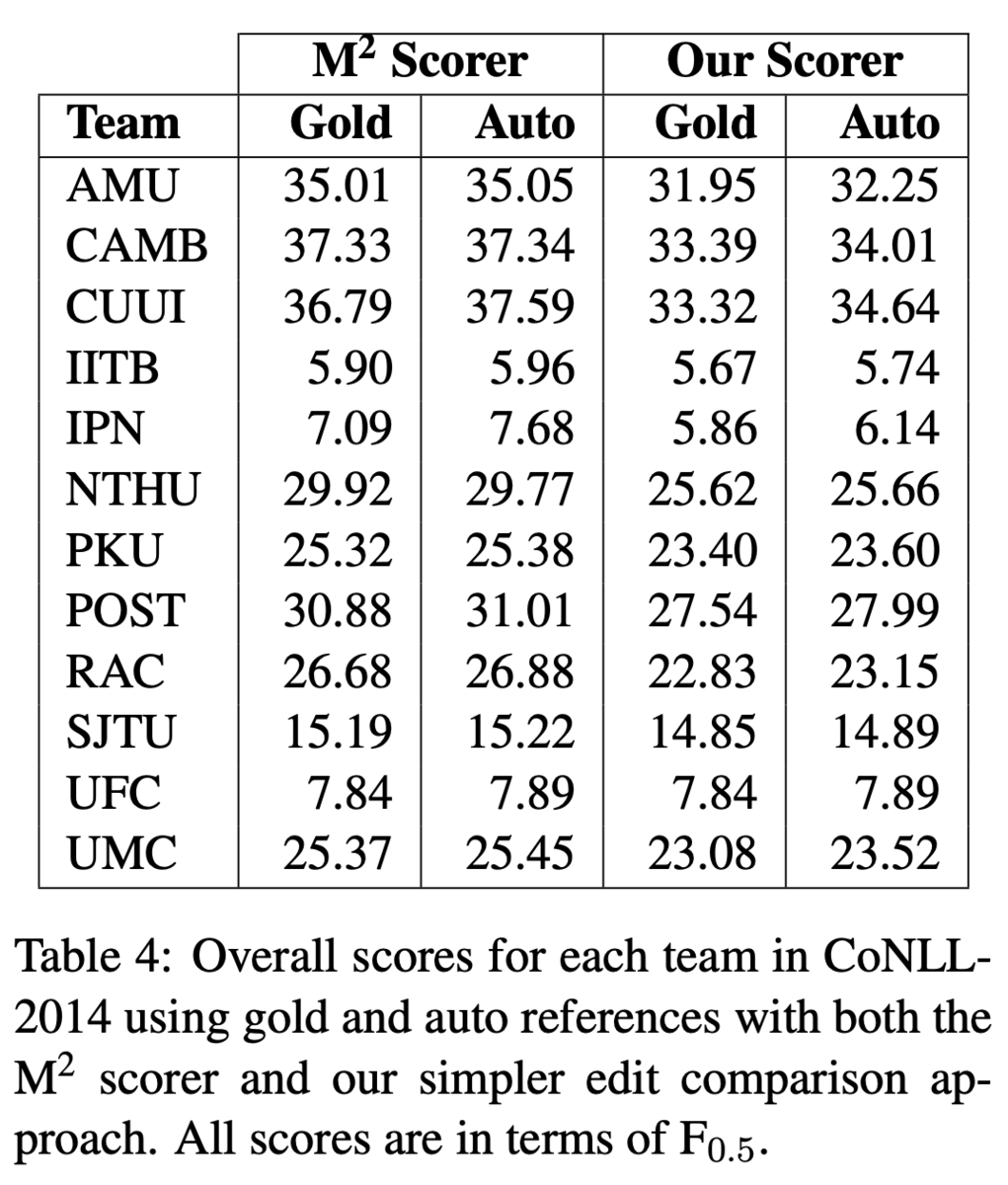
M2スコアラとの違い
Table 4からもわかるように,ERRANTの評価値は,M2スコアラと比較してF_0.5が低めに出る傾向があります.しかし,これはERRANTが性能を過小評価しているわけではなく,M2スコアラが過大評価しているからだと分析しています.M2スコアラはその由来がMax-Matchであるように,True Positiveができるだけ多く,かつFalse Positiveができるだけ少なくなるように振る舞うためです.
CoNLL-2014 Shared Taskにおける再評価
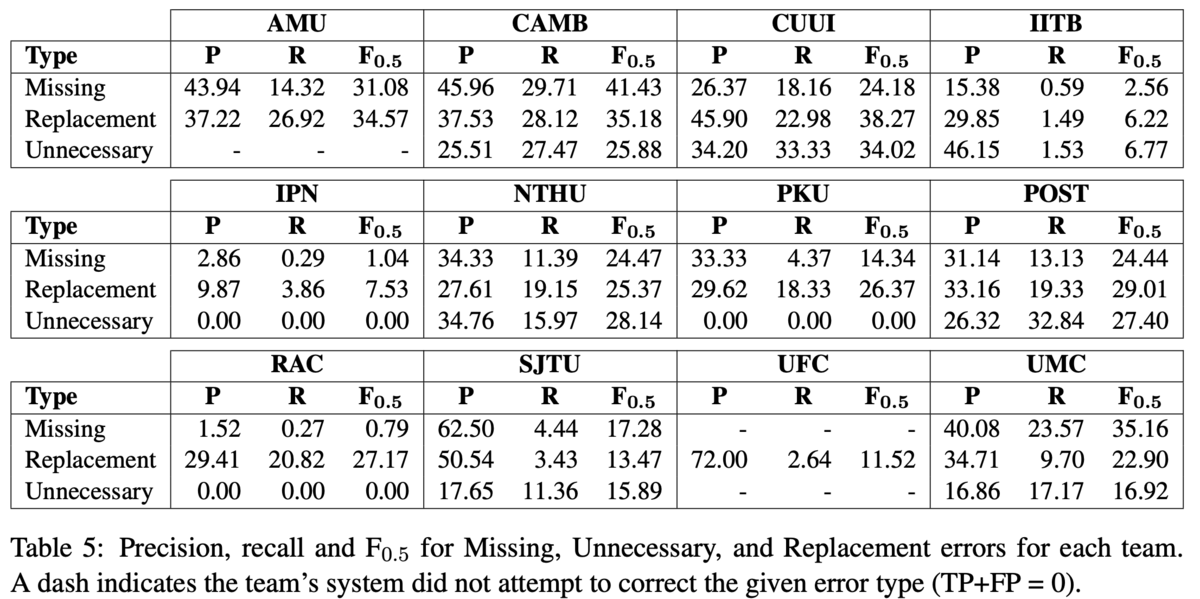
ERRANTによる自動アノテーションと自動評価尺度を用いて,CoNLL-2014の参加システムを再評価しました.Table 5では,訂正の種類が挿入,削除,置換の3種類についてそれぞれ評価を行い比較しました.この結果,システムによってかなり訂正の傾向が異なることがわかりました.
最も注目すべき結果として,AMU, IPN, PKU, RAC, UFCの5チームは,削除すべき誤りを一切解けていないということでした.この理由として,UFCルールベースの手法が削除の訂正を考慮していないことや,SMTベースの手法が削除の訂正をうまく学習できないことだと分析しています.一方,CUUIの手法は削除すべき誤りを最も訂正できていました.
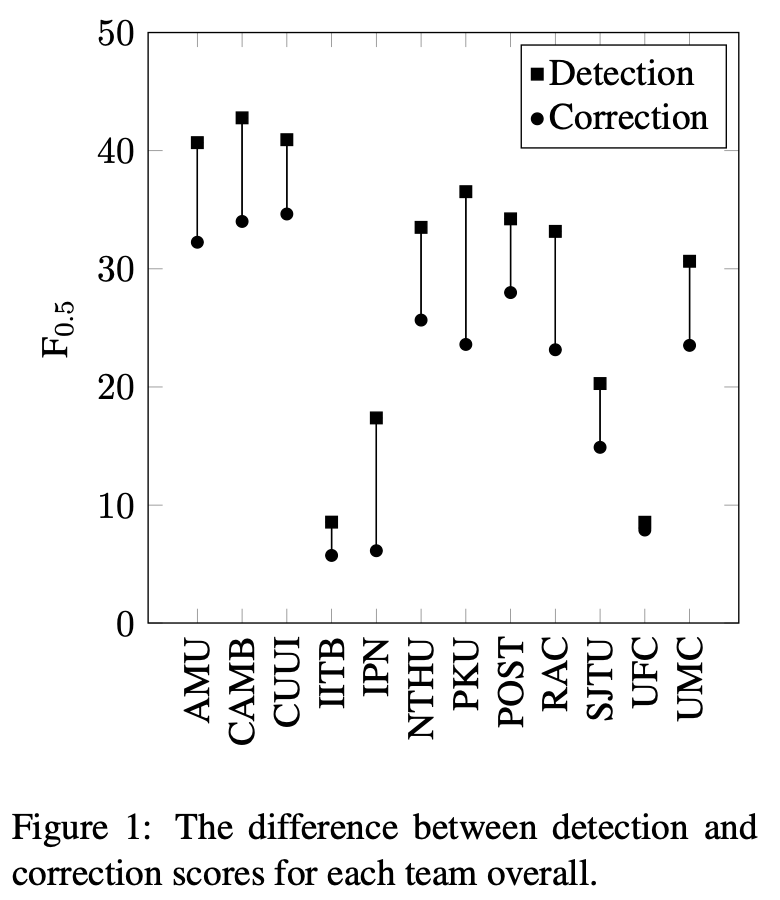
また,全てのエラータイプについて各システムのPrecison,Recall,F_0.5を分析しました(Table 6).まず分かるのは,IITB,IPN,POST3以外のシステムは,少なくとも1つのエラータイプにおいて最高性能を達成しています.これは,手法が異なれば解けるエラータイプが異なることを示しています.他にも,より粒度が細かいエラータイプに注目すると,それぞれの手法が得意なことが詳細に分析できました(Table 7, 本記事では割愛).
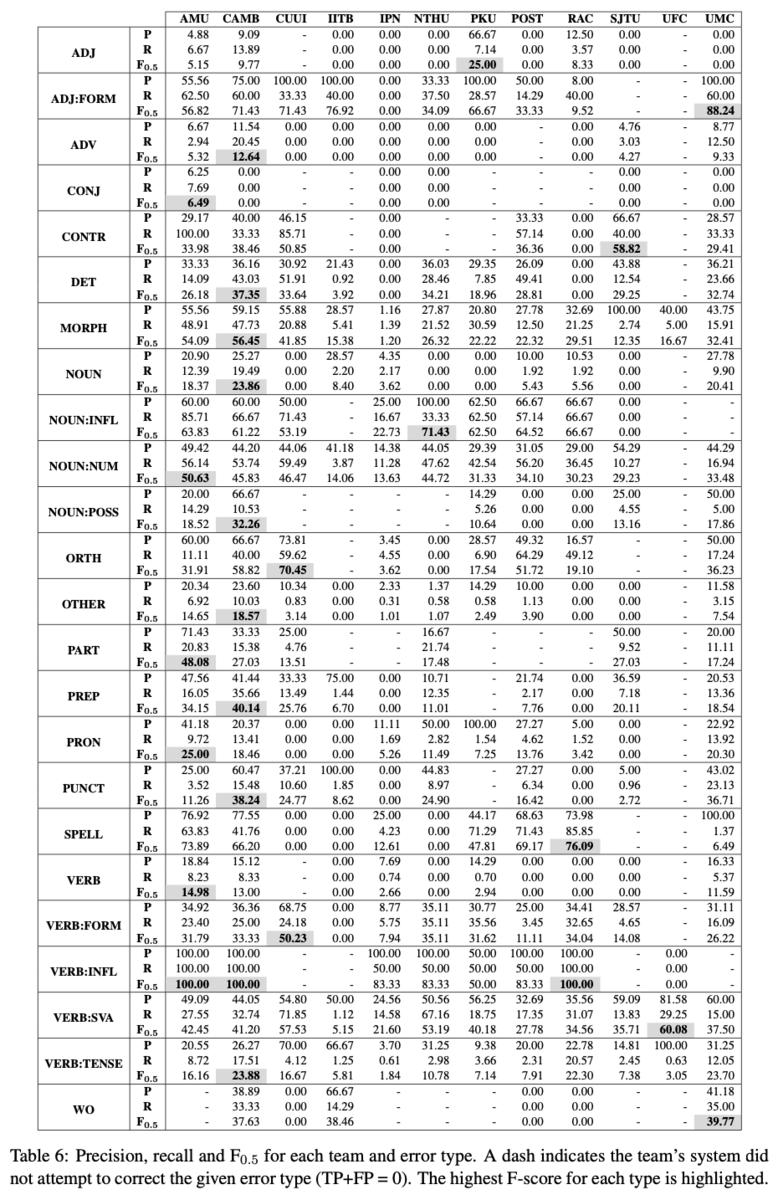
さらに,マルチトークンな訂正に限定した性能も評価しました(Table 8).マルチトークンな訂正とは,訂正前や訂正後のいずれかのトークン数が2以上になる訂正です.Table 8の結果からは,システムの多くはマルチトークンな訂正を苦手としていることがわかりました.今後はさらに結果の流暢さが求められることを考慮すると,このような誤りを解くためにはさらに工夫が必要だと分析しています.
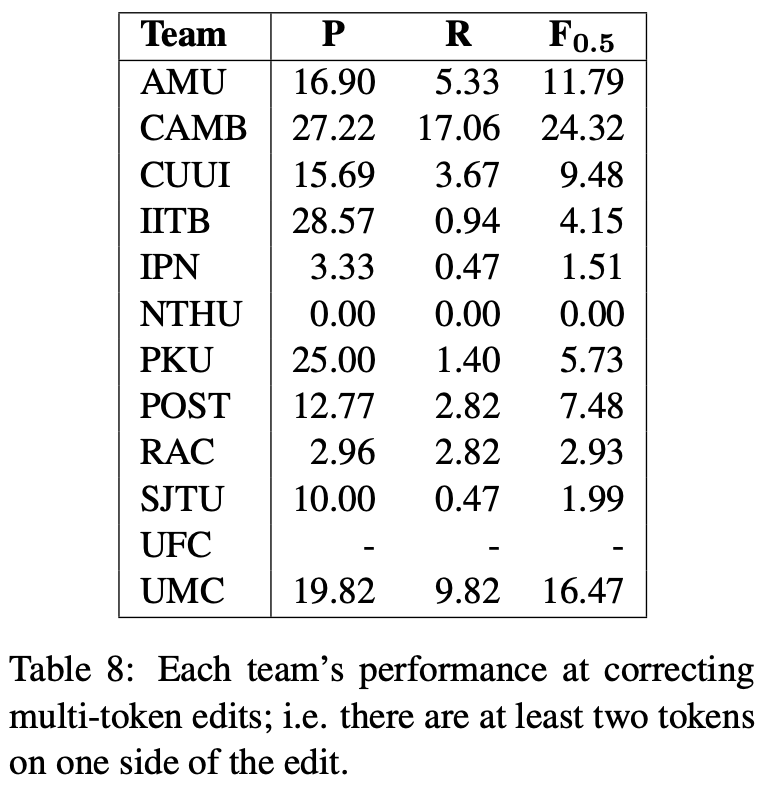
最後に,誤り検出の精度と誤り訂正の性能を比較しています(Figure 1).ここで,誤り検出の性能は,訂正後の文字列は気にせず,単語インデックスのスパンが正しく取れているかのみを測れば計算できます.Figure 1の結果からは,検出の性能が高いからといって訂正の性能も高いとは限らないことが分かります.また逆に,訂正の性能が低くても,検出の性能が高ければ学習者へのヒントとなる情報を提示する役割は果たせるとしています.
ERRANTの動かし方
実装はこちら: github.com
インストール:
python3 -m venv errant_env source errant_env/bin/activate pip3 install -U pip setuptools wheel pip3 install errant python3 -m spacy download en
ツールは3つの機能を提供しています.
errant_parallel -orig <orig_file> -cor <cor_file1> [<cor_file2> ...] -out <out_m2>
生文から訂正情報を自動で獲得します.入力は原文(-orig)とシステム出力文(-cor)の2つで,出力はM2フォーマットの訂正情報です.-corには複数のファイルを与えることができます.この場合,M2フォーマットの末尾である<annotator id>のところが0, 1, 2, ...とナンバリングされて記録されます.
errant_m2 {-auto|-gold} m2_file -out <out_m2>
既存のM2形式のアノテート情報を,ERRANT の仕様に沿ったものに変換します.-goldでは,アライメントはそのままに,エラータイプのみをERRANTが定義するものに変換します.-autoでは,アライメントやエラータイプを全てERRANTが再計算します.
errant_compare -hyp <hyp_m2> -ref <ref_m2> -ds -cat {1,2,3}
評価値を計算します.入力はM2フォーマットで表されたモデルの訂正情報(-hyp)と正解の訂正情報(-ref)です.-dsや-catは,評価値の出力をどのように行うかを指定します.-dsはSpan-based Detectionの評価値,-dtはToken-based Detectionの評価値を出力します.デフォルトは-scで,Span-based Correctionです.この3種類の違いは以下の表にあります.Detectionは訂正のスパン(単語インデックスのレンジ)のみで判断し,Correctionは訂正後の文字列まで見ます.

-cat {1,2,3}は,エラータイプの粒度を表します.-cat 1は置換誤り,不足誤り,余剰誤りの3種類の評価値のみ出力,-cat 2はエラータイプ25種類のみについて出力,-cat 3は各エラータイプについて置換,不足,余剰(最大55種類)のそれぞれの評価値を出力します.
参考文献
Felice, Mariano, Christopher Bryant, and Edward Briscoe. "Automatic extraction of learner errors in ESL sentences using linguistically enhanced alignments." Association for Computational Linguistics, 2016.