論文メモ:EMNLP2020, Improving the Efficiency of Grammatical Error Correction with Erroneous Span Detection and Correction
EMNLP2020,Improving the Efficiency of Grammatical Error Correction with Erroneous Span Detection and Correctionの論文メモです.
@inproceedings{chen-etal-2020-improving,
title = "Improving the Efficiency of Grammatical Error Correction with Erroneous Span Detection and Correction",
author = "Chen, Mengyun and
Ge, Tao and
Zhang, Xingxing and
Wei, Furu and
Zhou, Ming",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.emnlp-main.581",
doi = "10.18653/v1/2020.emnlp-main.581",
pages = "7162--7169",
}
ACL Anthology:
https://aclanthology.org/2020.emnlp-main.581/
この論文は,Copyright © 1963–2021 ACL,Creative Commons Attribution 4.0 International Licenseの下で公開されています.
概要
文法誤り訂正タスク(GEC)は,誤りを含む文から正解文への翻訳としてみなされ,EncoderDecoderのアーキテクチャ が使われてきました.しかし,GECでは誤りのないトークンについては入力から出力へコピーすることが多く,コピーの処理までEncDecのアーキテクチャに任せるのは非効率です.そこで,誤りスパンの検出器と,スパンの訂正器のパイプライン型のモデルを提案しています.結果,seq2seqに劣らない性能を維持したまま推論速度を50%程度削減することに成功しました.また,検出器の閾値を調整することで柔軟な推論が可能だとしています.
提案モデルのアーキテクチャ
アーキテクチャは,誤り検出器であるerroneous span detection(ESD),erroneous span correction (ESC)の2つをパイプライン的につなげたものです(Figure1).ESDは系列タギングに基づくモデルで,入力文の各トークンに対して正解か誤りかの2値をタグ付けします(Figure1 (a)).この結果をもとに,入力文に<s1></s1>のような誤りスパンを示す目印をつけます.
ESCはEncoder-Decoderなモデルです.Encdoerには誤りスパンの目印も含めた入力文を全て入れて,Decoderは目印をつけたスパン内のみ出力します(Figure1 (b)).

ESDを訓練する上では,あるトークンが誤りかどうかの正解情報が必要です.そこで,アノテーションツールであるERRANTと同じ方法でsourceとtarget間のアライメントを取ります.また,ESCの訓練時には,誤りのスパン以外にもランダムに選択したスパンも加えて学習させます.これはESDの検出エラーがESCに及ぼす影響を緩和するためです(ESDが誤って検出したスパンはESCが訂正しないことも大事).ランダムなスパンの選択は,SpanBERTの論文の3.1節に書かれている方法と同じです.これは,スパンの長さをGeometric distribution(小さい値に偏った分布)からサンプリングし,スパンの開始点を一様分布からサンプリングして作ったスパンを追加することを,文に占めるスパンの割合が閾値を超えるまで続けるものです.
データ
学習データとして,英語ではBEA-2019 Shared Taskの訓練データを使っています.さらに,事前学習として260M文の擬似データを用いています.この擬似データは,誤りでないトークンをランダムで選択し,そのトークンをConfusion-setで対応する誤りトークンに置換して作成します.
中国語のデータには,NLPCC-2018 Chinese GEC shared taskの公式データを使用します.
結果
英語(CoNLL-2014テストデータ,BEA-2019テストデータ)と中国語(NLPCC-2018テストデータ)で評価しています.
英語のデータセットでは,提案手法は先行研究のトップの性能には及ばないものの高速に動作するため,実応用に向いているとしています(Table 1).Table 1は3つのグループで比較が行われています.上のグループが擬似データによる事前学習なしのグループ,中央のグループが擬似データを用いた事前学習ありのグループ,下のグループがアンサンブルやリランキングなどのヒューリスティックな手法も加えたグループです.
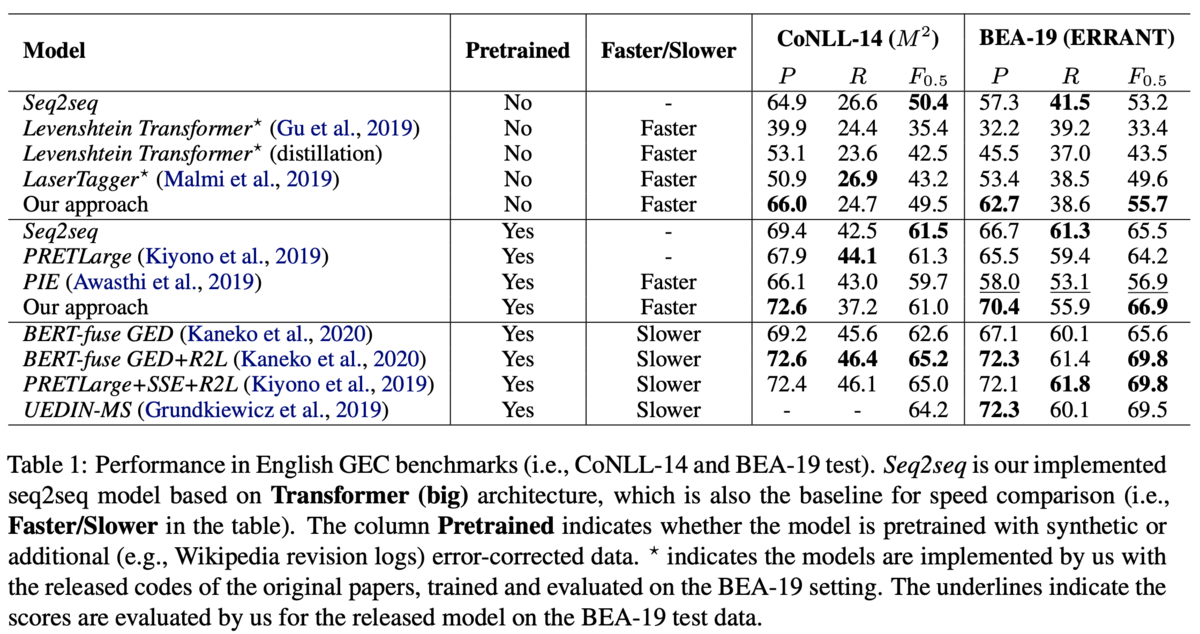
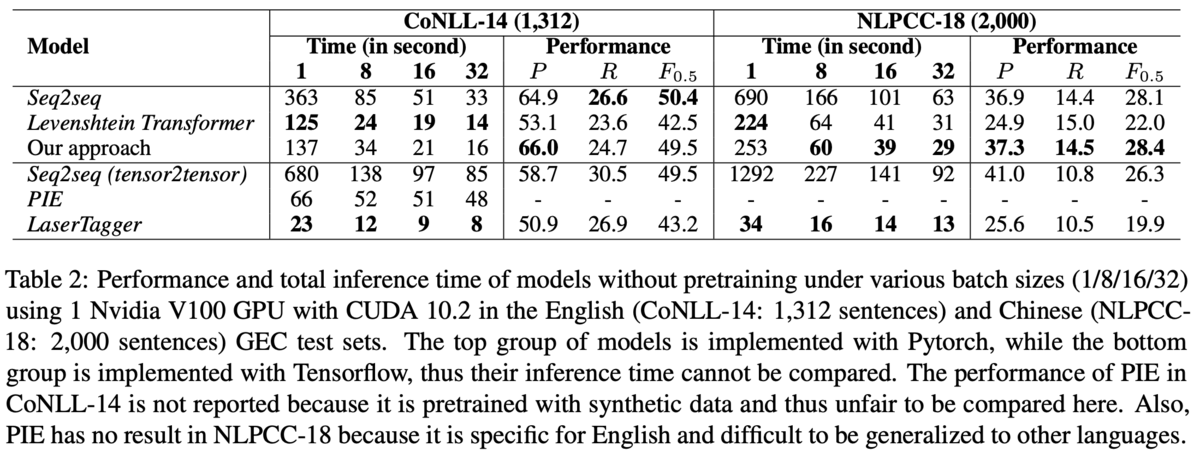
速度の比較では,全てを自己回帰で生成するseq2seqな手法の半分で推論可能だとしています(Table 2).Table 2は上のグループがpytorch実装,下のグループがtensolflow実装です.LanserTaggerやPIEは系列タギングに基づくモデルで,高速に動作することで知られています.また,英語と中国語の両方でseq2seqと遜色ない性能を達成しており,言語非依存で適用できることも示唆されます.
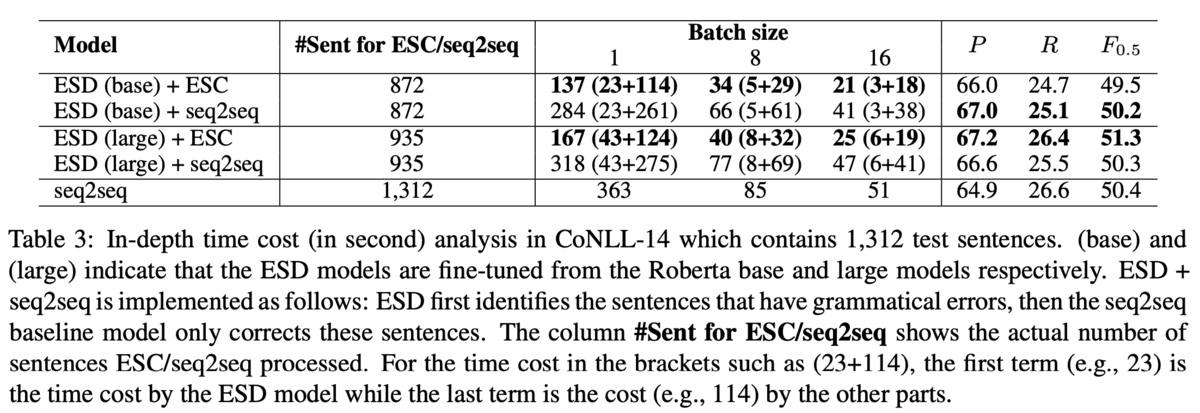
また,ESDやESCが処理した実数値も分析しています(Table 3).Table 3において,ESD+ESCは誤りスパンを検出→スパン内のみデコードする提案手法,ESD+seq2seqは誤りスパンが検出された文を(スパン関係なしに)全てデコードする手法を示しています.つまり,ESD+seq2seqとseq2seqを比較するとESDの貢献がわかり,ESD+seq2seqとESD+ESCを比較するとESCの貢献がわかります.結果,ESDはseq2seqよりもデコードする文を400文程度減らしており,ESCは時間を半分程度に削減することに成功しています.また,ESCはデコードするトークン数を1/3程度減らす効果があるようです(21,065 → 7,647).
それから,ESDの閾値を調整することで,モデルの振る舞いをPrecision重視にするかRecall重視にするかを決められることも利点だとしています.ESDの閾値を高くするとPrecisionが向上してRecallが低下し,閾値を低くするとその逆になります.これは直感的にも正しいですし,実験でも示されています(Table 4).