NAACL2021,Comparison of Grammatical Error Correction Using Back-Translation Modelsの論文メモです.
@inproceedings{koyama-etal-2021-comparison,
title = "Comparison of Grammatical Error Correction Using Back-Translation Models",
author = "Koyama, Aomi and
Hotate, Kengo and
Kaneko, Masahiro and
Komachi, Mamoru",
booktitle = "Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Student Research Workshop",
month = jun,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.naacl-srw.16",
doi = "10.18653/v1/2021.naacl-srw.16",
pages = "126--135",
}
ACL Anthology:
https://aclanthology.org/2021.naacl-srw.16/
この論文は,Copyright © 1963–2021 ACL,Creative Commons Attribution 4.0 International Licenseの元で公開されています.
概要
文法誤り訂正(GEC)では,データ不足を補うために擬似データ生成が行われています.擬似データの生成手法は逆翻訳の手法が主流であり,アーキテクチャは誤り訂正モデルと逆翻訳モデルで同じものが使われてきました.しかし,逆翻訳モデルには様々なアーキテクチャが適用可能であり,アーキテクチャによる訂正の傾向の違いは分析されていません.そこで,逆翻訳モデルとしてTransformer,CNN,LSTMの3つのモデルを用いて,性能の違いや訂正の傾向を調べています.結果,逆翻訳モデルとして単一のアーキテクチャを使うよりも,複数を組み合わせたほうが性能が上がるということを確認しました.
GECにおける逆翻訳を用いた擬似データ生成
GECでは文法誤りを含む文から正しい文へ変換することを目的とするタスクです.近年ではこの変換を翻訳するとみなして,seq2seqなモデルで解くことが主流です.しかし,seq2seqなモデルの学習には大量のデータが必要なのにも関わらず,GECの学習データは十分にありません.そこで,データの擬似生成をします.逆翻訳はデータ擬似生成手法の一つで,正解文を入力として誤り文を出力するように訓練します(GECの逆方向).こうして訓練した逆翻訳モデルの入力は正解文(誤りのない文)ですので,Wikipediaなどの単言語コーパスを入力すれば誤り文を擬似的に作ることができます.単言語コーパスは山ほどあるので,擬似データも大量に作れます.
実験
実験では,GECモデルは一種類に固定して,擬似データ生成のための逆翻訳モデルのアーキテクチャを変化させます.逆翻訳モデルはBEA-2019のtrainで訓練し,訓練後にWikipeadia(2020-07-06 dump file)から抽出した900万文を入力して擬似誤り文を生成します.アーキテクチャはTransformer,CNN,LSTMの3種類で実験します.また,異なるモデルの出力を合わせて1800万文とした擬似データや,seed値を変えた同じモデルの出力を合わせて1800万文とした擬似データでも実験します.評価はCoNLL-2014test,JFLEG,BEA-2019testの3つのデータセットで行います.
GECモデルはTransformerベースのEncoderDecoderモデルで,逆翻訳の手法で生成した擬似データ900万文(or 1800万文)で事前学習し,BEA-trainでfine-tuningします.また,ベースラインとして事前学習せず,単にBEA-trainのみで学習したモデルも訓練します.
結果
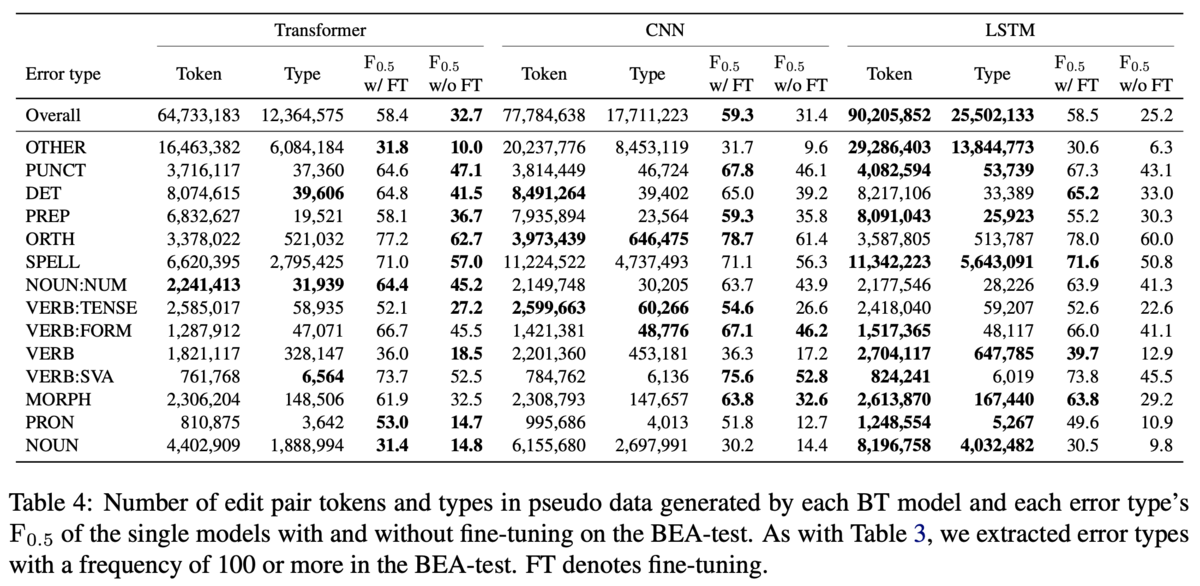
定量的な結果では,異なるモデルの出力を組み合わせた場合に最も性能が良いという結果になっています(Table2).Table2の上のブロックは単一モデルから生成した擬似データで訓練したとき,下のブロックは複数のモデルが生成した擬似データを組み合わせて訓練したときです.
上のブロックではデータセットによって異なる逆翻訳モデルが高い性能を示しています.やGLEUを見ると,CoNLL-2014ではTransformerが勝っていて,JFLEGとBEAではCNNが勝っています.近年ではTransformerが他のモデルよりも高い性能を出すことが多いですが,逆翻訳モデルに適用する場合には,必ずしもTransformerが良いとは限らないと主張しています.
下のブロックでは,やGLEUで見るとCNN&CNNがJFLEGで1位,Transformer&CNNが他2つのデータセットで1位です.CNN&CNNやTransformer&Transformerはシード値を変えて生成した擬似データを混ぜたものですが,上のブロックで示されている単一のモデルに負けることがあります.例えば,CoNLL-2014のTransformerに注目すると,単一なら
が59.0ですが,シードが異なるものを混ぜると
が58.9と劣ります.例外的にJFLEGではCNN同士で混ぜたものが僅差で勝っていますが,全体としては異なるモデルが生成した擬似データを組み合わせたほうがロバストなGECモデルになるとの結論です.
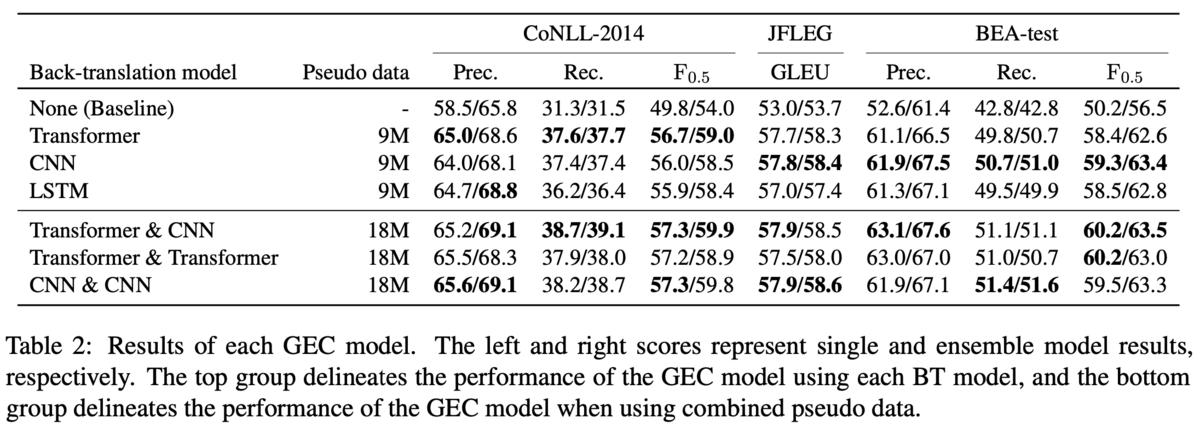
BEAのtestにおけるエラータイプ別の性能も分析しています(Table3).左のブロックは単一モデルでの性能です.逆翻訳モデルのアーキテクチャによって異なるエラータイプの性能が向上しています.しかし,PUNCTの誤り(Punctuation,カンマやピリオドなどの誤り)は他のエラータイプに比べてベースラインからの伸びが小さく,逆翻訳で生成した擬似データで解くのは難しいことを示唆しています.右側のブロックはモデルを組み合わせた場合の性能です.Table3に掲載されている14のエラータイプのうち,11のエラータイプに関しては,Transformer&CNNがCNN&CNNとTransformer&Transformerのどちらかには勝っている(=最下位ではない)ため,やはり異なるモデルが生成した擬似データを混ぜることでロバストなGECモデルになると主張しています.また,OTHERのエラータイプに注目すると,Transformer&CNNが突出して解けているので,多様な誤りの訂正に寄与するような擬似データが生成できていそうだという主張をしています.(ただ,同じモデルでもシードを変えることで性能にばらつきがあるエラータイプは,同一モデルを混ぜると性能が高くなるみたいな話も4節の終わりに書いてあります.)
考察
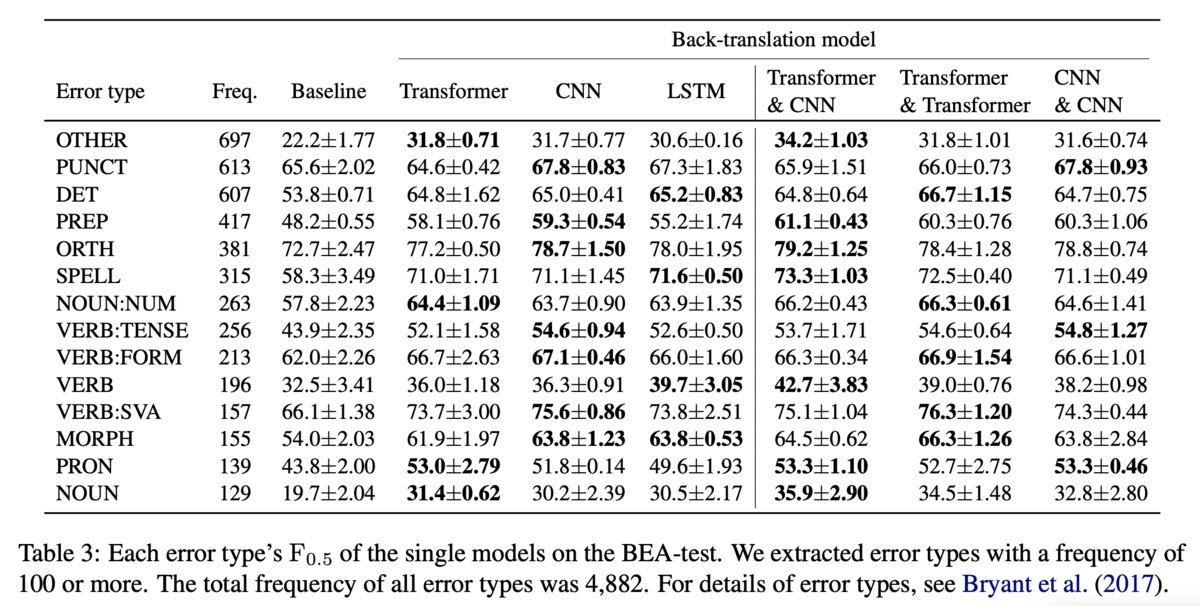
直感的にはたくさん生成されたエラータイプは性能が上がりそうですが,そうではなかったようです(Table4).擬似生成されたトークン数と誤りの数がともに1位の逆翻訳モデルと,GECモデルの性能が1位であるような逆翻訳モデルが一致するエラータイプは14種類中6種類にとどまりました.
また,事前学習の時点で逆翻訳モデルによって性能の優劣があっても,fine-tuningすればそれが逆転する可能性があることも主張しています(Table5).Table5ではBEA-testにおいてfine-tuningしたもの(w/FT)としなかったもの(w/oFT)の性能を比較しています.w/oFTにおいてLSTMはTransformerにで7ポイント程度負けていますが,w/FTでは逆に0.1ポイント勝っています.