論文メモ:EACL2021, How Good (really) are Grammatical Error Correction Systems?
EACL2021,How Good (really) are Grammatical Error Correction Systems? の論文を紹介してみます.
@inproceedings{rozovskaya-roth-2021-good,
title = "How Good (really) are Grammatical Error Correction Systems?",
author = "Rozovskaya, Alla and
Roth, Dan",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2021.eacl-main.231",
pages = "2686--2698",
}
ACL Anthology: aclanthology.org
この論文は,Copyright © 1963–2021 ACL,Creative Commons Attribution 4.0 International Licenseの元で公開されています.
概要
文法誤り訂正(GEC, Grammatical Error Correction)の参照あり評価(事前に用意した正解文を使って行う評価)では,用意された正解文が正解の集合を網羅できない問題がある.そこで,システム出力文をできるだけ変えないように人手で修正を加えて,それを正解文とみなして評価した.英語とロシア語のデータセットで評価した結果,GECシステムは従来報告されているよりも高品質な訂正が行えることを示唆した.また,10-bestの出力文の分析からは,下位のランクほど多様な訂正が行えていることを示唆した.
導入
現状の参照あり評価は,GECシステムの性能を過小評価していると主張しています.GECは入力文の誤りを発見して自動で訂正するタスクですが,訂正の候補は山ほどあります.現在使われているM2 ScorerやGLEU,ERRANTのような評価指標はいずれも参照あり評価で,事前に用意された正解文をもとに評価しています.正解文は人手でアノテーションしており,データセットによっては一つの入力文に対して正解文が複数付与されることがありますが,前述したように正解の候補は大量にあるため全てを網羅できません.よって,現状の参照あり評価は,GECシステムが持つ本当の性能を評価できていないとしています.また,こうなる主な原因は,正解文がシステム出力とは独立に作成されているから,とも主張しています.
手法
前述した問題は,システム出力から正解文を作ることで解決します.こうして作られた正解文もまた入力文に対応する正解の集合に属するため,本来は評価されるべき部分が評価されると言えます.論文中では,このように作成した正解文をClosest Golds (CGs)と呼んでいます.これと対応して,元からアノテーションされている正解文はReference Gold (RG) と呼んでいます.また,システム出力の10-bastに対して検証します(本当は1,2,5,10番目ですが).
CGsは,入力文とシステム出力文を見ながら,入力文の意味を損なわず,かつ,システム出力文との編集距離ができるだけ小さくなるように作ります.形式的には,入力文を,10-bestの出力文を順に
とすると,
の組みを見ながら,対応する
を作ることになります.結局,全体的としては,
のセットが得られる感じです.
実験
実験は英語のデータセットとロシア語のデータセットで行っています.英語データセットはCoNLL-2014とBEA test,ロシア語のデータセットはRULEC-GECとlang-8コーパスのロシア語の文です.GECモデルは,英語にはBERTベースのモデル,ロシア語にはTransformerベースのSoTAモデルを使います.
は,
について作ります.つまり,ある入力文に対してGECシステムが1,2,5,10番目だと推定した4つの出力文について,それぞれを人手で編集して
を作ります.入力文は,各データセットから100文ずつランダムに取ります.
のアノテーションは,英語ではネイティブと非ネイティブの2人,ロシア語は1人のネイティブが行います.3人とも修士号を有しており,過去にアノテーションの経験があるそうです.
結果
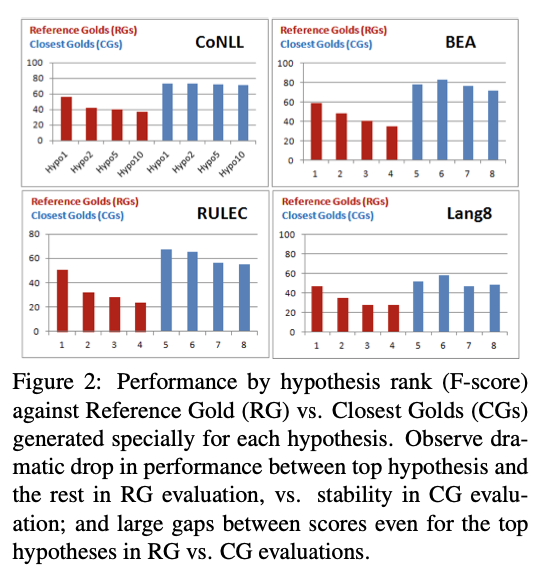
モデルの出力はに対して最適化されていることを主張しています(Figure2).まず,
に(赤色)に注目すると
から
にかけてスコアが減少していて.かつ,
と
の差が特に大きく開いています.一方で,
(青色)に注目すると,
ほどその傾向は表れていません.つまり,モデルの出力文でランクが高いものでも低いものでもやっている訂正は高品質だということです.
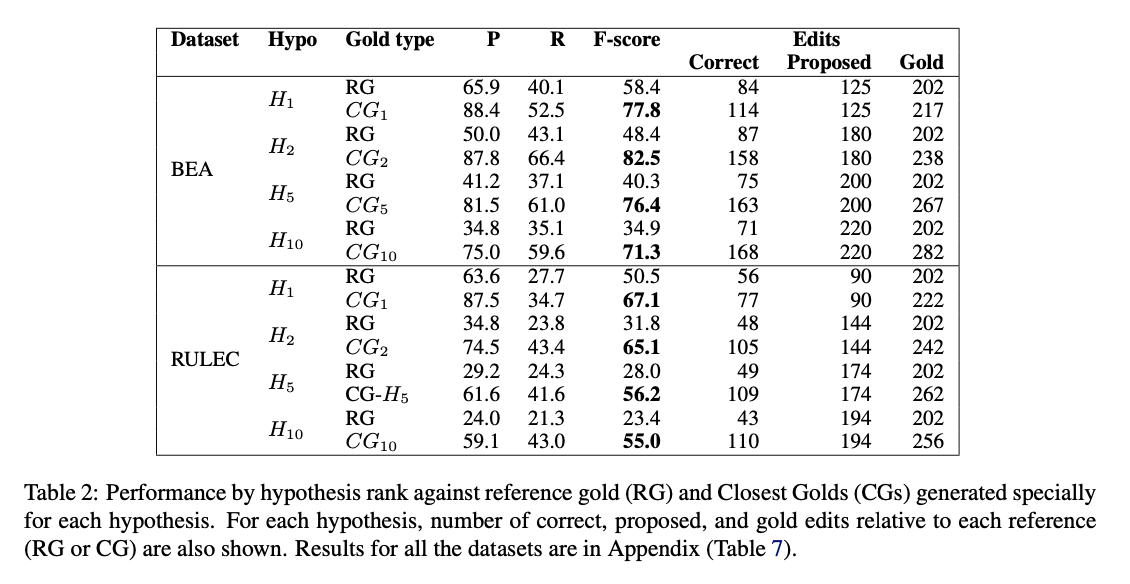
また,訂正が行われる数に注目すると,ランクが低い出力文ほど多くの訂正を行っており,かつ,RGに対する性能値とCGに対する性能値の差が大きくなることを示しています(Table2).つまり,ランクが高い出力文ほどRGに近いような訂正をするようにフィットしていることが言えます.(まあtrainもtestも人が正解文をつけているので,trainにフィットさせたモデルが自信を持って出力する文はtestの正解(RG)にもフィットするだろうというのは自然な気はします.)
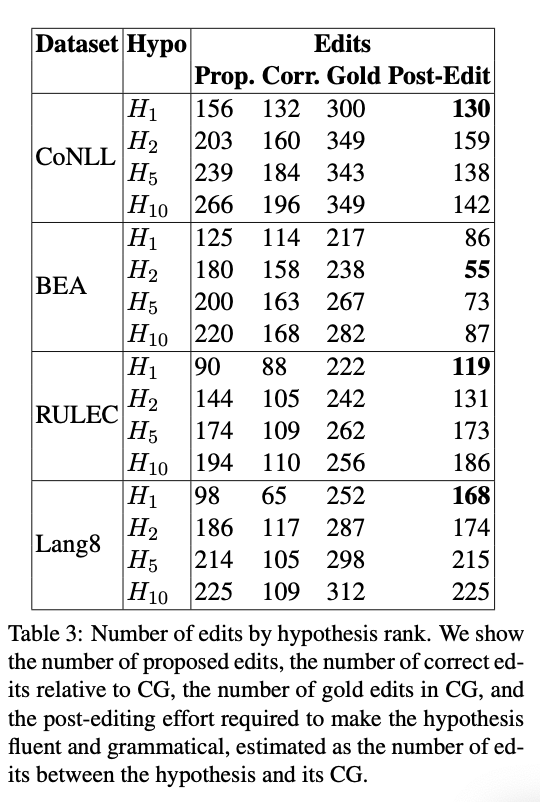
次に,編集率(Edit Rate)に注目した結果も分析しています(Table3).ここでは主にpost-editと呼ばれる,正解文であるCGとシステム出力文の間の編集距離として定義された値を計算しています.結果として,英語のデータセットではランクによるpost-editに大きな違いはなく,ロシア語のデータセットではや[tex:H{10}]はわずかにpost-editが大きくなっているが,
と
の差は特にないという結果になっています.ロシア語のデータセットでは
や[tex:H{10}]でpost-editの値が大きくなりますが,大幅に劣化しているわけではないので,やはり下位のランクの出力文も高品質ですねという結論です.
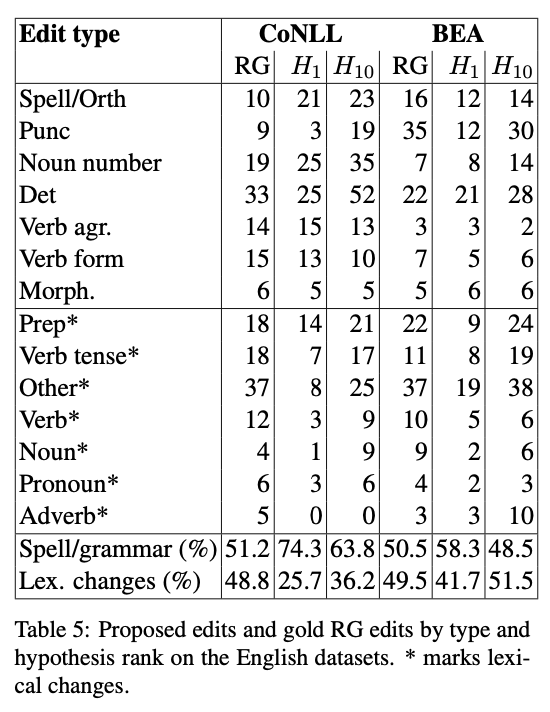
最後に,英語のデータセットで出力文のランクにおける訂正傾向の違いについて調べた結果は,低いランクの出力文ほどLexical(語彙的)な訂正を行っていることを示唆しています.Table5では上のブロックがスペル誤り/文法誤りでグルーピングした誤りタイプを,下のブロックがLexicalな誤りでグルーピングした誤りタイプを示しています.Table5最下部のパーセンテージを見ると,よりも
のほうがLexicalな誤りを多く含んでいることがわかります.つまり,実は低いランクの出力文のほうが多様な誤りを訂正できているのではないかということです.
考察など
DiscussionはConclusionみたいになっていますね.3つくらいの主張にまとめています.1つ目は,やはり現状の GECシステムってみんなが思ってるより高性能だよ,ということ.2つ目は,10-bestで1番になっている訂正はRGに寄っているので数値上は最も高品質に見えるが,下位の出力も高品質で,場合によってはトップの出力が負けることもあるということ.3つ目は,10-bestで下位の出力文は,多様な訂正をしているということです.