論文メモ:BEA2021, Document-level grammatical error correction
@inproceedings{yuan-bryant-2021-document,
title = "Document-level grammatical error correction",
author = "Yuan, Zheng and
Bryant, Christopher",
booktitle = "Proceedings of the 16th Workshop on Innovative Use of NLP for Building Educational Applications",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.bea-1.8",
pages = "75--84",
abstract = "Document-level context can provide valuable information in grammatical error correction (GEC), which is crucial for correcting certain errors and resolving inconsistencies. In this paper, we investigate context-aware approaches and propose document-level GEC systems. Additionally, we employ a three-step training strategy to benefit from both sentence-level and document-level data. Our system outperforms previous document-level and all other NMT-based single-model systems, achieving state of the art on a common test set.",
}
この論文は,Copyright © 1963–2021 ACL,Creative Commons Attribution 4.0 International Licenseの元で公開されています.
概要
文法誤り訂正(GEC,Grammatical Error Correction)は文単位で処理を行うことが一般的でした.しかし,周囲の文脈も考慮することでより正確な訂正が期待できます.例えば,動詞の時制は周囲の文脈に出現する他の動詞などから推測できる可能性があります.そこで,文書単位のGECモデルを提案しました.結果としては,訂正対象の文と周囲の文脈を別々にエンコードし,デコーダ側で足すようなアーキテクチャが最も良いとしています.また,評価データとして従来の文単位の評価データではなく,文書単位の評価データを使って評価しています.
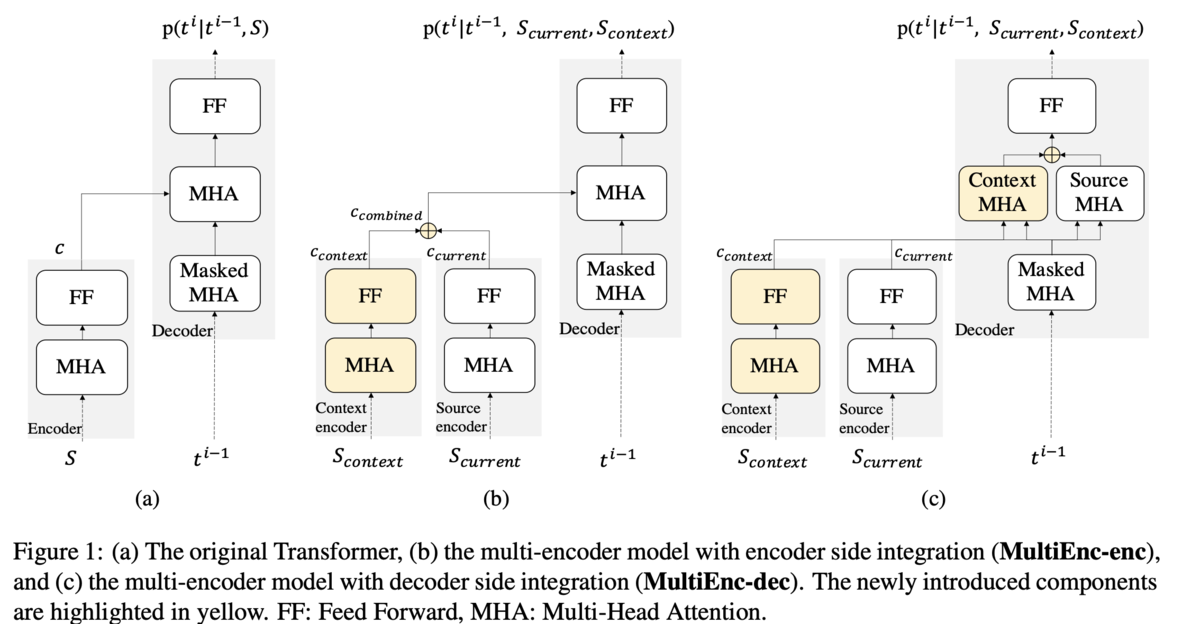
モデル
Baseline,SingleEnc,MultiEnc-enc,MultiEnc-decの4種類を比較しています.まず,BaselineはTransformerベースのseq2seqモデルです(Figure1 (a)).このモデルでは文脈を考慮せず,訂正対象の文のみを見て誤りを訂正します.SingleEncもアーキテクチャはTransformerベースのseq2seqですが,入力に周囲の文も合わせた一つの長い系列を用います.MultiEnc-encは,訂正対象の文と周囲の文を別々にエンコードし,それらの重みつき和をデコーダに送ります(Figure1 (b)).MultiEnc-decも訂正対象の文とその周囲の文を別々にエンコードしますが,デコーダ側には足さずに送り,2種類のアテンションを計算してから足します(Figure1 (c)).2種類のアテンションとは,のmasked multi-head self-attensionと,
から
への直接的なアテンションです.
は訂正対象の文のエンコード表現,
は文脈のエンコード表現です.
MultiEnc-encにおける重み付き和は,式(1)のように計算されます.ここで重みは式(2)のように計算されます.エンコードしたそれぞれのベクトルをconcatし,1層通すイメージです.

文書レベルGECの評価
これまでGECで使われてきた評価用データは,正解が文単位で用意されているため,文書レベルGECの性能を正しく評価できません.そこで,文書単位の評価データを作成しています.作成するといっても,既存の評価データの分割単位を文単位にするか文書単位にするかというだけです.CoNLL-2014やBEA-2019は,元々はエッセイをアノテーションしたデータセットで,これまではそれを文単位で分割して使ってきました.今回の文書レベルGECの評価では,文書単位に分割したデータを使います.M2形式で考えると,Sから始まる行には1文書が対応します.
ただし,この評価方法は複数のアノテーションが付与された評価データにおいて,少し厳しい評価となります.理由は,従来は文ごとに最適なアノテーションを選んで採点できていたのに対して,今回は文書ごとにしか最適なアノテーションを選べないからです.
訓練
MultiEnc-encとMultiEnc-decのモデルは3段階で訓練します.1段階目は文単位のデータを用いた事前学習です.この段階では文脈のデータがないので,文脈をエンコードする部分は無視します.データセットはCLC + FCE-train + W&I-train + NUCLEを使います.2段階目はCLCデータセットを用いた文書単位のデータで訓練し,3段階目はFCE-train + W&I-train + NUCLEの文書単位のデータでfine-tuningします.
BaselineとSingleEncのモデルもCLCで訓練し,FCE-train + W&I-train + NUCLEでfine-tuningします.BaselineとSingleEncは,訓練時に文単位のデータと文書単位のデータを混ぜることはしません.
結果
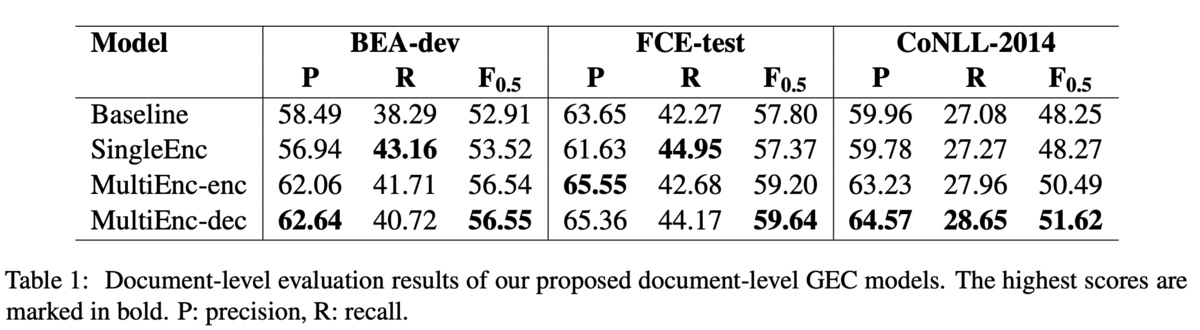
結果は,MultiEnc-Decが全ての評価データで最高のを示しました.BEA-devではMultiEnc-encと違いはほぼありませんが,FCE-testとCoNLL-2014では性能が向上しているため,デコーダがより文脈を捉えられていそうだということでした(Table 1).
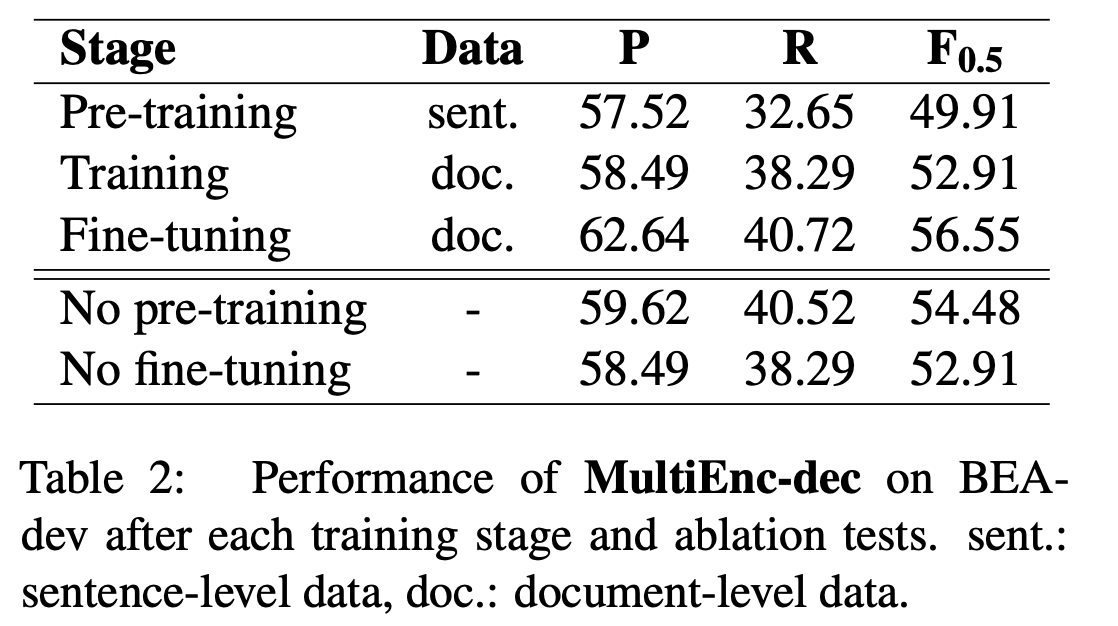
また,3段階の訓練におけるAblation studyの結果,pre-traningもfine-tuningも性能向上に寄与しているため,どちらも必要だということでした(Table 2).
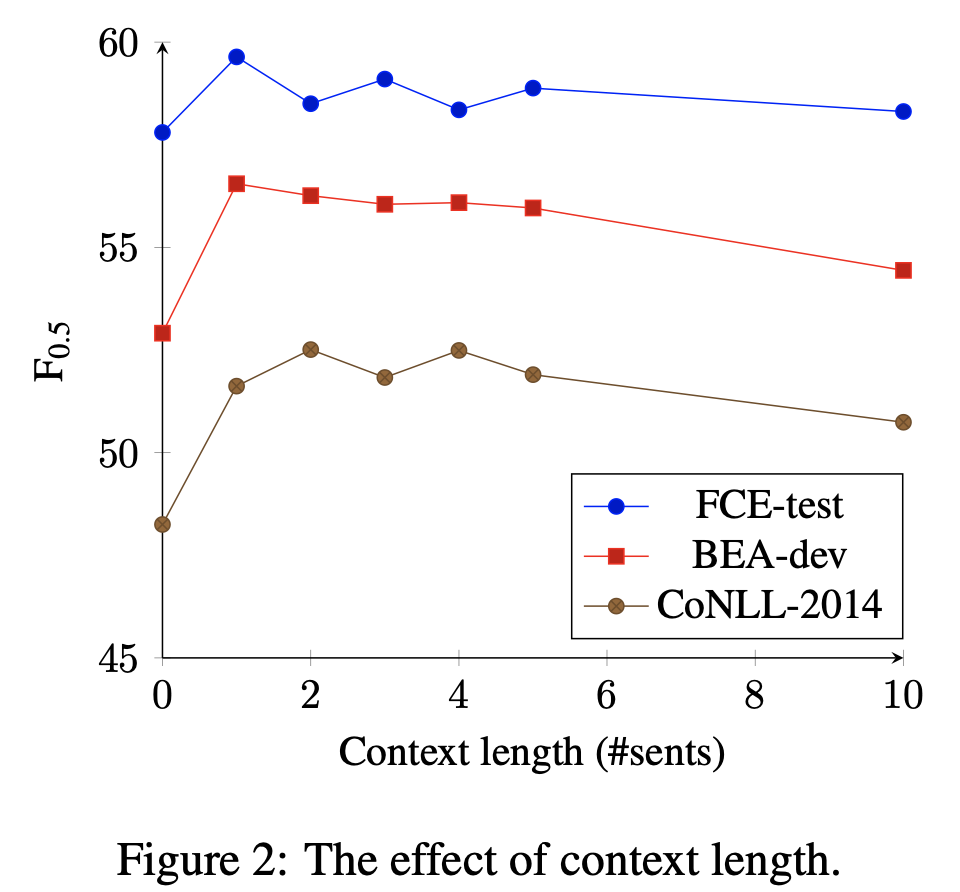
それから,入力する文脈は前後1~2文程度で良いそうです(Figure 2).BEA-devとFCE-testでは前後1文を考慮するのが最も性能がよく,CoNLL-2014では前後2文を考慮することが最も良いそうです.CoNLL-2014は他のデータセットに比べて1文書あたりの文数が2倍くらいあるので,より広い文脈の考慮が効いたのではと分析しています.また,使う文脈は長ければ良いというものではないこともわかります.
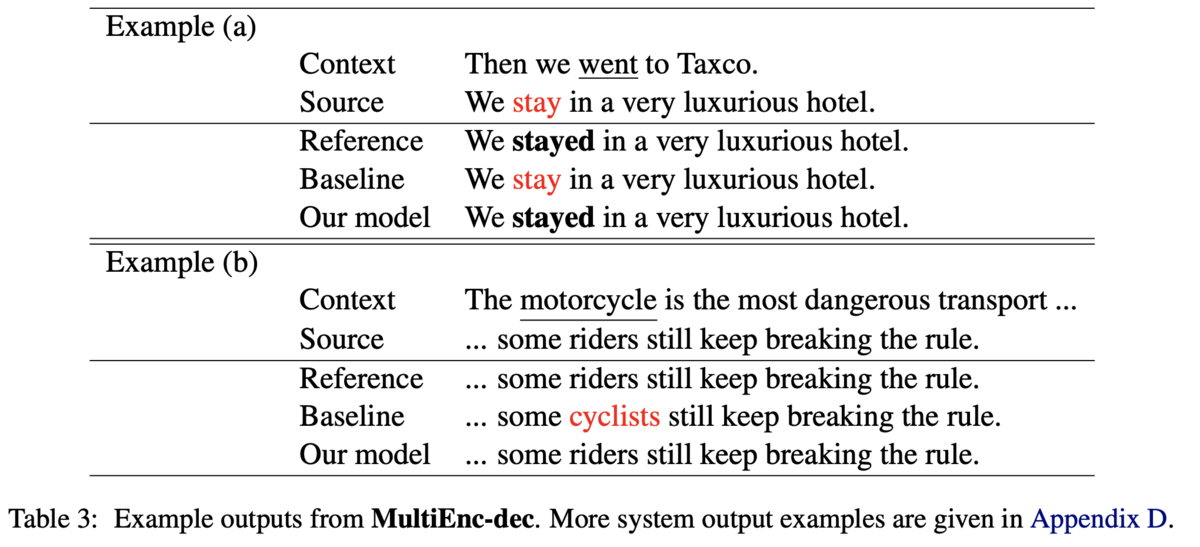
エラータイプ別の分析では,主語動詞の一致,動詞の時制,代名詞のエラータイプが顕著に解けるようになっていました.他にも,トピックに依存した語彙選択もうまくできた例があったようです.例えば,motorcycleに乗る人を指す単語としてはcyclistsよりもriderのほうが適切ですが,提案手法はriderを選択できています(Table3のExmaple (b)).
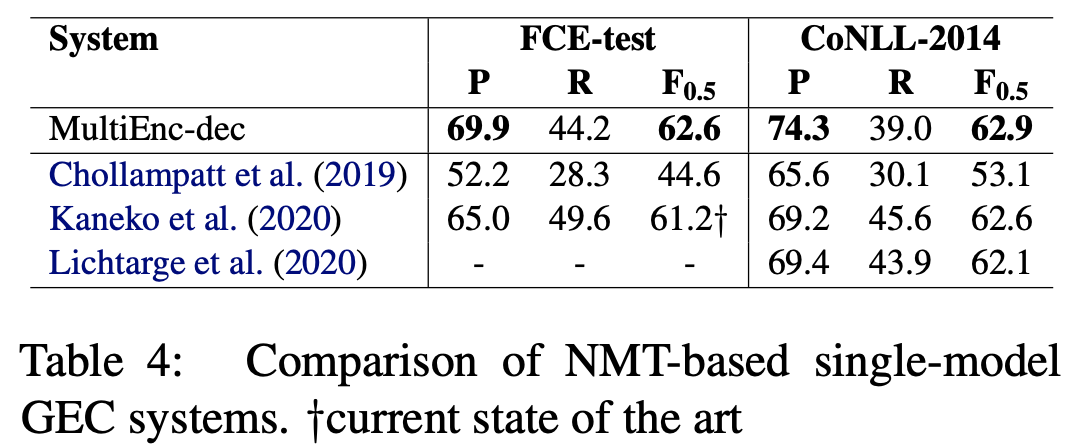
最後に,従来のNMT-basedなモデルとの比較を行っています.評価データとして文単位のCoNLL2014,尺度をMスコアラとして比較すると,提案手法は高いPrecisionを達成しており,FCE-testでは最高性能を達成しました.提案手法は擬似データを用いていませんが,擬似データを用いている先行研究と匹敵する性能を達成しています.
実装
文書単位の評価データを作るツールが公開されています. github.com
モジュールとしてerrantが必要です.
pip install errant
もしspacyの英語データが無いよ的なエラーが出たら
python -m spacy download en
として英語データを取ってこれば動きました.