GECToR:系列ラベリングによる文法誤り訂正
GECToRは文法誤り訂正を系列ラベリングとして解くモデルです.既存の系列変換モデルに基づくモデルでは,入力文に対する訂正文をleft-to-rightに生成することで解かれてきました.一方,GECToRは系列ラベリングに基づいており,入力文を編集するような訂正方法になります.この記事では,GECToRの訂正手法からツールの動かし方までを解説します.
訂正手法
GECToRは入力文の各トークンに対して,訂正操作を示すタグを推定することで訂正します.推定されたタグは後処理として入力文に反映し,訂正文を獲得します.
タグ設計
GECToRが推定するタグはbasic-transformationとg-transformationの2種類に大別されます.
basic-transformationは,置換・挿入・削除・無編集の4種類の編集操作に基づくタグです.特に,置換および挿入のタグについてはどのトークンに置換するのか,どのトークンを挿入するのかという情報が必要ですので,トークンの情報も含めたタグになります(例:REPLACE_to,APPEND_the).そのため,削除と無編集のタグは1種類のみ(DELETE,KEEP)ですが,置換と挿入については複数存在します.
g-transformationは,言語情報に基づいたタグです.例えば,名詞のためには「単数形にする」「複数形にする」といったタグが存在し,動詞のためには「過去形にする」「現在形にする」などのタグが存在します.このようなタグは,語彙が異なっても同一のタグを推定すれば訂正できるため(apples→appleの訂正とbooks→bookの訂正は共に「単数形にする」というタグさえあれば訂正可能),クラス数の削減や,説明性の向上に寄与します.詳細は論文のAppendixのAにあります.
以下は論文中の例文を入力したときの訂正例です.$APPENDが挿入操作,$TRANSFORM_AGREEMENT_SINGULARが単数形にする操作,$TRANSFORM_VERB_VB_VBZが動詞に三単現のsをつける操作を示すものです.
入力文: A ten years old boy go school
----- Iteration 1 -----
A ten years old boy go school
$APPEND_- $TRANSFORM_AGREEMENT_SINGULAR $TRANSFORM_VERB_VB_VBZ
----- Iteration 2 -----
A ten - year old boy goes school
$APPEND_to
訂正文: A ten - year old boy goes to school
アーキテクチャ
BERTのようなEncoderの上に誤り検出とタグ推定のためのLinearが乗っている構造です.ただし,推論時には一度訂正して終わるのではなく,訂正文を再度入力することで反復的な訂正を行います(論文では2回程度訂正すれば十分だと報告されています).以下はTarnavskyi+22に記載の図であり,構造がわかりやすいかと思います.
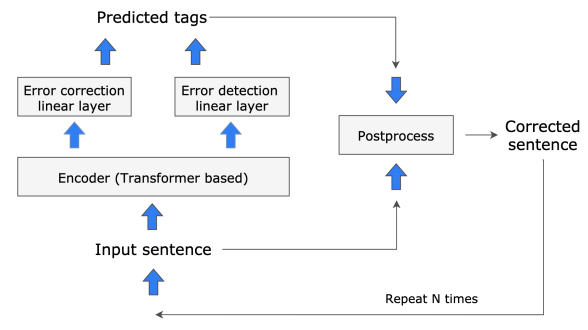
上の図からわかるように,GECToRはタグ推定とトークン単位の誤り検出確率推定のマルチタスクを解くように学習します. 両方の情報は訓練データから得られるため,その情報を教師として学習します.
マニア向け:推論時における誤り検出確率の使われ方
誤り検出確率は,反復的な訂正処理において,訂正を継続するかどうかを決定するために使われます.具体的には,誤り検出確率はトークン単位で推定しますが,その中の最大値が閾値より大きい場合に訂正が継続されます.
ここで閾値とは,推論時のパラメータとして定義されているものです.もし閾値を0に設定した場合,(NNの出力がぴったり0になることはない気がするので)検出確率に関わらず訂正は継続し,指定した反復回数に到達すれば推論が終了します.一方,もし閾値を0より大きくした時,指定した反復回数に到達するか,トークン単位の検出確率の最大値が閾値を超えなかった場合に推論が終了することになります.
ツールの動かし方
公式実装は以下です.
前処理
python utils/preprocess_data.py \ -s <誤り文のファイルパス> -t <正解の訂正文のファイルパス> -o <出力ファイルのパス>
誤り文と正解の訂正文を与えてタグの情報を事前に作ります.出力形式は入力のトークンとタグがSEPL|||SEPRで区切られたものが,さらに空白で区切られたものになります.
以下に例を示します.
echo 'I go to park a week ago .' > src.txt echo 'I went to the park a week ago .' > trg.txt python utils/preprocess_data.py -s src.txt -t trg.txt -o out.txt
このとき,out.txtは
$STARTSEPL|||SEPR$KEEP ISEPL|||SEPR$KEEP goSEPL|||SEPR$TRANSFORM_VERB_VB_VBD toSEPL|||SEPR$APPEND_the parkSEPL|||SEPR$KEEP aSEPL|||SEPR$KEEP weekSEPL|||SEPR$KEEP agoSEPL|||SEPR$KEEP .SEPL|||SEPR$KEEP
となります.これを試しに空白でsplitした後,各要素をさらにSEPL|||SEPRでsplitすると
[['$START', '$KEEP'] ['I', '$KEEP'] ['go', '$TRANSFORM_VERB_VB_VBD'] ['to', '$APPEND_the'] ['park', '$KEEP'] ['a', '$KEEP'] ['week', '$KEEP'] ['ago', '$KEEP'] ['.', '$KEEP']]
のようになって,タグが付与されていることがわかります.
訓練
--train_setや--dev_setには,上で紹介したutils/preprocess_data.pyの出力ファイルを指定します.
バッチサイズとかは調整してください.
python train.py \ --train_set <訓練データの前処理済みデータ> \ --dev_set <開発データの前処理済みデータ> \ --model_dir <モデル保存先のディレクトリ> \ --batch_size 64 \ --accumulation_size 4 \ --n_epoch 1 \
学習結果は以下のように保存されます(1エポックの場合).
model/
├── best.th
├── log
├── metrics_epoch_0.json
├── model_state_epoch_0.th
├── model.th
├── training_state_epoch_0.th
└── vocabulary
├── d_tags.txt
├── labels.txt
└── non_padded_namespaces.txt
もし特定の訓練済みモデルを読み込んでfine-tuneする場合には,--pretrain_folder,--pretrain,--vocab_pathを指定します.
# 特定のモデルを読み込んでfine-tuneする時 python train.py \ --train_set <訓練データの前処理済みデータ> \ --dev_set <開発データの前処理済みデータ> \ --model_dir <モデル保存先のディレクトリ> \ --batch_size 64 \ --accumulation_size 4 \ --n_epoch 1 \ --pretrain_folder <読み込むモデルのディレクトリ> \ --pretrain <読み込むモデルのファイル名(拡張子の.thは含めない)> \ --vocab_path <読み込むモデルに対応する語彙情報を有するディレクトリ>
例えば,上で示したようなディレクトリ構造においてmodel/best.thを読み込みたい場合には,
--pretrain_folder model \ --pretrain best \ --vocab_path model/vocabulary
のように指定します.
推論
python predict.py \ --model_path <読み込むモデルのパス(ファイル名まで含める)> \ --input_file <入力の生データ(前処理は不要)> \ --output_file <出力ファイルのパス> \ --vocab_path <読み込むモデルに対応する語彙情報を有するディレクトリ> \ --batch_size 64 \ --min_error_probability 0.0 \ --additional_confidence 0.0
推論時は,モデルのパスを拡張子まで含めて全て記述します.
--min_error_probabilityと--additional_confidenceは推論時に関係するハイパーパラメータです.--min_error_probabilityは誤り検出確率の閾値(マニア向けの節で説明しました)で,--additional_confidenceはKEEPタグのバイアスです.いずれのパラメータも値を高くするほど保守的な訂正になります.
また,アンサンブル設定で推論する場合には,--model_pathに複数のモデルを指定します.また同時に,--is_ensemble 1も指定する必要があります.