論文メモ:ACL2022, Adjusting the Precision-Recall Trade-Off with Align-and-Predict Decoding for Grammatical Error Correction
Reference
@inproceedings{sun-wang-2022-adjusting,
title = "Adjusting the Precision-Recall Trade-Off with Align-and-Predict Decoding for Grammatical Error Correction",
author = "Sun, Xin and
Wang, Houfeng",
booktitle = "Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers)",
month = may,
year = "2022",
address = "Dublin, Ireland",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.acl-short.77",
pages = "686--693",
}
コード
概要
seq2seqな文法誤り訂正モデルのデコード手法として,precisionとrecallを制御するAlign-and-Predict Decoding (APD)を提案.デコードの各時刻で,入力をコピーするようなトークンの生成確率のみ変更することで制御する.入力をコピーするようなトークンは,入力文と出力途中の文とのアライメントを取れば分かる(ことがある).
背景
文法誤り訂正システムを使う目的によって,precision重視にするかrecall重視にするかは変わってきます.precisoin重視であれば,ユーザに間違いのない訂正を提示できるので,ユーザのexperienceは上がります.一方で,母語話者向けのシステムであればrecall重視の方がいいかもしれません.(参考:NLP2021 高再現率な文法誤り訂正システムの実現に向けて).
近年では,文法誤り訂正モデルにはseq2seqモデルとtaggerモデルの2種類が台頭しています.taggerモデルとして代表的なGECToRは,誤り検出確率の閾値とKEEPタグのconfidenceの2つのハイパーパラメタを用いることで,precisionとrecallのどちらを重視するかをある程度制御できます.一方,seq2seqモデルでも制御する方法は提案されているものの,多くはアーキテクチャやデータなど,特定の側面に依存していることが問題です.そこで,seq2seqのデコードの方法を改良することに注目した,Align-and-Predict Decoding (APD)を提案しています.
Align-and-Predict Decoding (APD)
直感
文法誤り訂正では,入力と出力がある程度一致することが多いです.seq2seqのような自己回帰モデルにおいては,デコードの過程で入力の部分系列と同じ系列を出力する状態が頻発します.
デコードの途中の状態を考えましょう.つまり,ある時刻までの系列は出力が完了しています.また,天下り的ですが,出力文のsuffix(接尾辞)が入力文のある部分系列と一致しているとします.このとき,次の時刻でモデルが入力をコピーする場合,どのトークンを選べばいいかは入力文から知ることができます.下図は自分で作ったものですが,仮にモデルが次の時刻でも入力をコピーするなら,入力文の部分系列(赤色)の右隣のトークン(青色)を持って来ればいいと分かります.
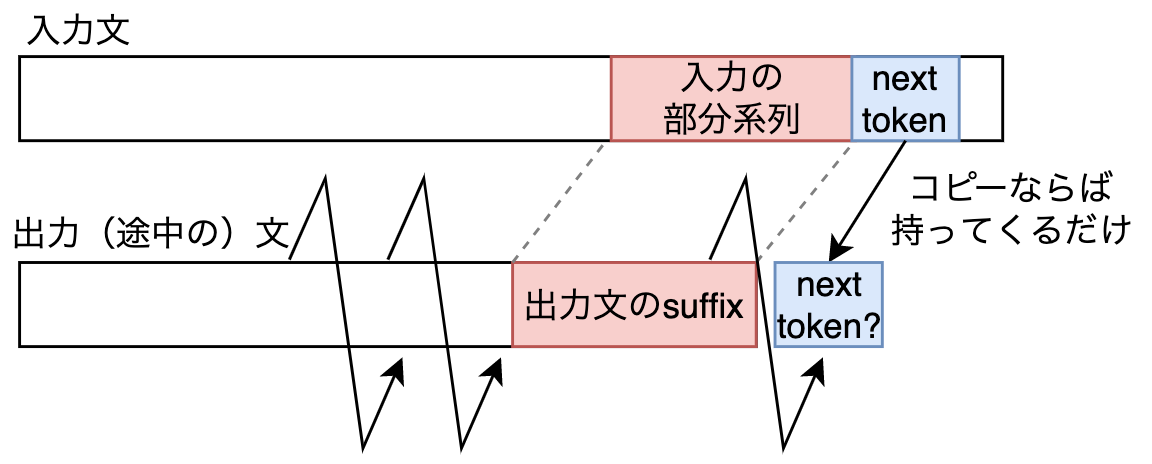
出力文のsuffixと入力文の部分系列で一致するものがあるかは,アライメントを取れば分かります.もしあれば,入力のコピーとなるトークンも分かります.したがって,コピーとなるトークンの生成確率のみを”いじる”ことが可能です.確率が高くなるようにすると,コピーが促進されて保守的な訂正になります(high-precison, low-recall).一方,その逆では積極的な訂正になります(low-precisoin, high-recall).
論文中の具体例に移ります.Figure1のBeam1では,最新の時刻においてwordを出力しており(suffixがword),入力文にもwordが存在します.したがって,次の時刻においてweが入力のコピーとなるトークンだと分かります.一方,weの生成確率は意図的に高くも低くもできるため(適当な値と積を取ればよい)コピーを促進するかどうかを制御できます.
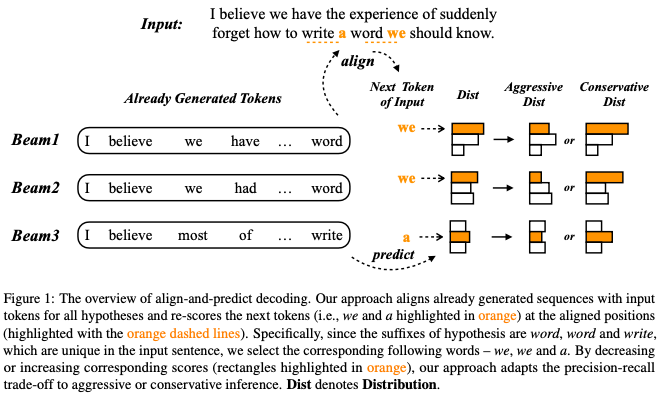
以上の考えをビームサーチにおけるそれぞれのビームに適用します.
式
厳密なnotationが欲しい人は論文を読んでください.
いま,ビーム幅のビームサーチをしており,時刻
まで出力が終了しています.
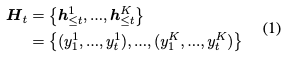
あるビームについて,出力済みの系列のsuffix(
)と一致する入力文の部分系列(
)が見つかれば,部分系列の次のトークン(
)を
に加えます.
は入力のコピーとなるようなトークンの集合です.
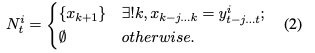
一旦話は普通のビームサーチに戻ります.とりあえず次の時刻のトークンとして全ての語彙を考えます.
![]()
top-kを取るために文のスコアリングをする必要があるので,次のようにスコアを計算します.普通のビームサーチと異なるのは,の重みの項がある点です.
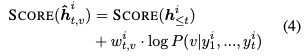
は,次のように決まります.
はハイパーパラメタです.
に属する語彙を出力するとコピーと同義になり,そのような語彙に対する重みが
です.
であれば積極的な訂正になり,
であれば保守的な訂正になります.(4)式は単に
の形である(マイナスしてない)ため,
の大小の解釈に注意します.
最後に,次の時刻のビームは,を考慮したスコアのtop-kを取ることで得られます.式中のarg topKは
と
に関係しているので,全てのビームと全ての語彙を考慮したtop-kになっています(普通のビームサーチと同じです).
![]()
実験と結果
実験は英語と中国語で行っています.詳しい実験設定は論文を参照してください.
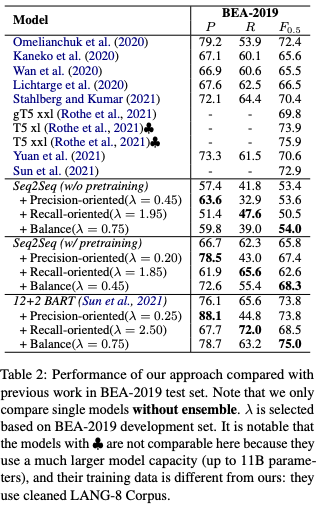
英語では,の値によってprecisionとrecallの制御が実現されていることがわかります.また,BARTで重みを初期化した場合(下図の最下ブロック)において,
に設定したときの
は先行研究を上回っています.
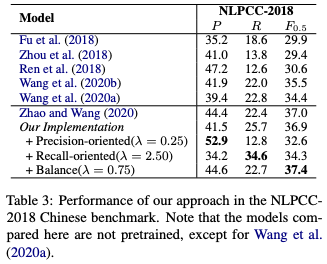
中国語での実験でも,の値によってprecisionとrecallの制御が実現されていることがわかります.
に設定したときの
は先行研究を上回っています.
分析
の値によって,precision,recall,
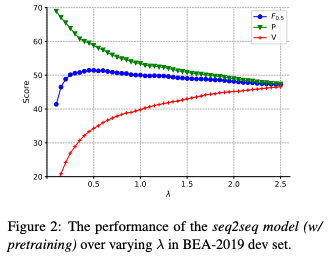
がどのように変化するか調べています.データはBEA19共通タスクの開発データです.Figure2の結果は
が小さいほどhigh precision, low recallになっており,直感的です.
最後に,実例が示されています.の値が大きくなるほど,積極的に訂正していることが分かります.

感想
(2)式で出力文のsuffixと一致する入力文の部分系列を探すパートがありますが,ここで2トークン以上の部分系列が引っかかる場合があるのか気になりました.末尾Nトークンが一致するなら当然末尾N-1トークンも一致するので,再帰的に考えると末尾の1トークンが一致する場合しかないのではないかと思いました.言い換えると,(2)式のが1より大きくなるのか?と思いました.
デコードの時刻を進めるたびに入力文と比較するので,推論時間が長いのではと思いました.しかし,AppendixのBによると,5%長くなる程度のようで,そこまで影響ないようです.
を高くしてhigh precisionな出力を行った場合に,どの誤りタイプが多く訂正されるのかは気になりました.よりモデルが自信を持って推定できる誤りタイプは何か(逆に自信がない誤りタイプは何か),という分析に使えそうです.関連して,多様な訂正文の生成のためにも使えそうです.訂正文が多様になるように訓練していないモデルでも,APDを用いてデコードを工夫するだけで多様な訂正文が得られます.
関連研究
イントロでも触れましたが,Taggerモデルとして代表的なGECToRは,誤り検出の閾値とKEEPタグのconfidence(底上げする量)をハイパーパラメタとしています.これにより,コピーを促進するかどうかを制御できます.
誤り検出と誤り訂正を組み合わせる手法もあります [Chen+ 2020].はじめにスパンレベルの誤り検出を系列ラベリングとして解きます.その後,誤りがあると判断されたスパンのみに対して自己回帰モデルで訂正します.この方法では,誤り検出の確率に閾値を設定することで,コピーを促進するかどうかを制御できます(下記論文のTable 4).
論文ではreferされていませんが,[Hotate+ 2019]もprecisionとrecallの制御に言及しています.この手法では,訓練データを誤り率に応じて5段階にわけ,各段階に対応する特別なトークンを入力文にくっつけて訓練します.推論時には,所望の訂正率に応じて入力文の先頭に特別なトークンを付与して入力することで,訂正する度合いを制御できます.Table 3の結果では,特別なトークンとして誤り率が少なくなるようなものを付与したときほど,high-precisionおよびlow-recallの傾向にあることが報告されています.