cLang-8データセット:ツールの動かし方の備忘録
ACL2021,"A Simple Recipe for Multilingual Grammatical Error Correction"の論文[Rothe+ 2021]で,cLang-8データセットが報告されました.cLang-8データセットはCleaned LANG-8 Corpusの呼称で,既に公開されているLang-8コーパス[Mizumoto+ 2011]のノイズを取り払うことで綺麗にしたようなデータセットです.
この記事では公開されているツールの動かし方の備忘録を残しておきます.cLang8は直接公開されておらず,Lang8からcLang8を作るようなスクリプトが公開されています.このスクリプトを使って,各自の環境でcLang8を作ることになります.基本的に公式のリファレンスの通りにやれば動きます.
手順
Official Repository:
1. Git Large File Storageをインストール
$ brew install git-lfs
でインストールした後,
$ git-lfs install
とやるとGit LFS initialized.と言ってくれるのでこれで完了.インストールできたか確認したいときは
$ git-lfs version
を実行してみる.
詳細は公式サイトを参照.
2. 公式リポジトリをclone
$ git clone https://github.com/google-research-datasets/clang8.git
3. Lang-8コーパスをダウンロード
以下のGoogle Formにアクセスして,必要事項を書き込んで送信.すぐにリンク付きのメールが送られてきます.リンクは2つ掲載されていますが,... raw format containing all the data up to 2010.と書いてあるほうのリンクを選びます.300MBくらいのzipなので,適当な手段でダウンロードして解凍.
解凍結果のディレクトリ構造が
├── lang-8-20111007-L1-v2.dat └── README
みたいになっていればok.
4. run.shを書き換える
cloneしたリポジトリの中にあるrun.shのLANG8_DIR=を編集します.
readonly LANG8_DIR='<INSERT LANG8 DIRECTORY HERE>' ↓ readonly LANG8_DIR='/lang-8-20111007-2.0/'
みたいな感じです.
5. run.shを実行
結構時間かかります(CPU次第?).
$ sh run.sh
6. 出力を確認
結果はoutput_data/に保存されます.各tsvの行数は公式リポジトリの記載の通りになるはずです.試しに英語のものを見てみて,
$ wc output_data/clang8_source_target_en.spacy_tokenized.tsv 2372119 56656257 267513611 output_data/clang8_source_target_en.spacy_tokenized.tsv
みたいになればokです.
出力にはソースとターゲットがタブ区切りになったペアが1行1ペアの形式で格納されます.
7. 蛇足
fairseqの学習などのためにソースとターゲットを別々のファイルにする場合は
$ cut -f 1 clang8_source_target_en.spacy_tokenized.tsv > train.src $ cut -f 2 clang8_source_target_en.spacy_tokenized.tsv > train.trg
などのように書けます.また,ERRANT [Felice+ 2016, Bryant+ 2017] を用いてreferenceのM2ファイルを作る場合,
$ errant_parallel -orig train.src -cor train.trg -out ref.m2
のように書けます.
エラーたち
いくつかエラーが出ました.
Could not find a version that satisfies the requirement ...
Could not find a version that satisfies the requirement thinc<8.1.0,>=8.0.8 (from versions: 6.12.0, 6.12.1, 7.0.0.dev1, 7.0.0.dev2, 7.0.0.dev6, 7.0.0, 7.0.1, 7.0.2, 7.0.3, 7.0.4, 7.0.5, 7.0.6, 7.0.8, 7.1.0, 7.1.1, 7.2.0.dev3, 7.2.0, 7.3.0, 7.3.1, 7.4.0.dev0, 7.4.0.dev1, 7.4.0.dev2, 7.4.0, 7.4.1, 8.0.0.dev0, 8.0.0.dev2, 8.0.0.dev4, 8.0.0a0, 8.0.0a1, 8.0.0a2, 8.0.0a3, 8.0.0a6, 8.0.0a8, 8.0.0a9, 8.0.0a11, 8.0.0a12, 8.0.0a13, 8.0.0a14, 8.0.0a16, 8.0.0a17, 8.0.0a18, 8.0.0a19, 8.0.0a20, 8.0.0a21, 8.0.0a22, 8.0.0a23, 8.0.0a24, 8.0.0a25) No matching distribution found for thinc<8.1.0,>=8.0.8 You are using pip version 10.0.1, however version 21.2.4 is available. You should consider upgrading via the 'pip install --upgrade pip' command.
原因:pipのバージョンが低いです.とりあえずupgradeしとけばいいので,run.shを
virtualenv -p python3 . source ./bin/activate pip install -r requirements.txt ↓ virtualenv -p python3 . source ./bin/activate pip install --upgrade pip pip install -r requirements.txt
のように追記して対応.
clang8/run.sh: 12: clang8/run.sh: source: not found
お使いのbashか何かにはsourceコマンドがありません.代わりにピリオドなら動きます.run.shを次のように編集
source ./bin/activate ↓ . ./bin/activate
ValueError: not enough values to unpack (expected 5, got 1)
このissueにもある通り,データが正確にcloneできていません.git-lfsが動いていない状態でcloneしたリポジトリのrun.shを実行した場合にこのエラーが出ます.git-lfsを正しくインストールしましょう.
参考文献
Rothe, S., Mallinson, J., Malmi, E., Krause, S., & Severyn, A. (2021). A Simple Recipe for Multilingual Grammatical Error Correction. arXiv preprint arXiv:2106.03830.
Mizumoto, T., Komachi, M., Nagata, M., & Matsumoto, Y. (2011, November). Mining revision log of language learning SNS for automated Japanese error correction of second language learners. In Proceedings of 5th International Joint Conference on Natural Language Processing (pp. 147-155).
Felice, M., Bryant, C., & Briscoe, E. (2016). Automatic extraction of learner errors in ESL sentences using linguistically enhanced alignments. Association for Computational Linguistics.
Bryant, C., Felice, M., & Briscoe, E. (2017, July). Automatic annotation and evaluation of error types for grammatical error correction. Association for Computational Linguistics.
論文メモ:ACL2017, Automatic Annotation and Evaluation of Error Types for Grammatical Error Correction
@inproceedings{bryant-etal-2017-automatic,
title = "Automatic Annotation and Evaluation of Error Types for Grammatical Error Correction",
author = "Bryant, Christopher and
Felice, Mariano and
Briscoe, Ted",
booktitle = "Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = jul,
year = "2017",
address = "Vancouver, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/P17-1074",
doi = "10.18653/v1/P17-1074",
pages = "793--805",
概要
文法誤り訂正の評価のためのツールとしてERRANTを提案しました.Felice(2016)らのアライメント手法をベースに,エラータイプを付与する手法を提案しています.また,CoNLL-2014 Shared Taskの参加システムを再評価し,訂正の傾向について分析しました.
この論文の立ち位置
この論文では,誤り訂正の自動アノテーションと自動評価を行うツールであるERRANTを提案しています.あくまでもERRANTを提唱したのはこの論文ですが,手法としては2本の論文が合わさった成果であり,この論文は2本目の立場です.
1本目はFelice et. al(2016)の研究で,原文と訂正文から自動でアライメントをとって,訂正情報を抽出する手法を提案しています.2本目はこの論文で,抽出できた訂正情報からエラータイプを付与する方法と,評価値の算出方法を提案しています.1本目の詳細は以下にも解説してあります. gotutiyan.hatenablog.com
手法
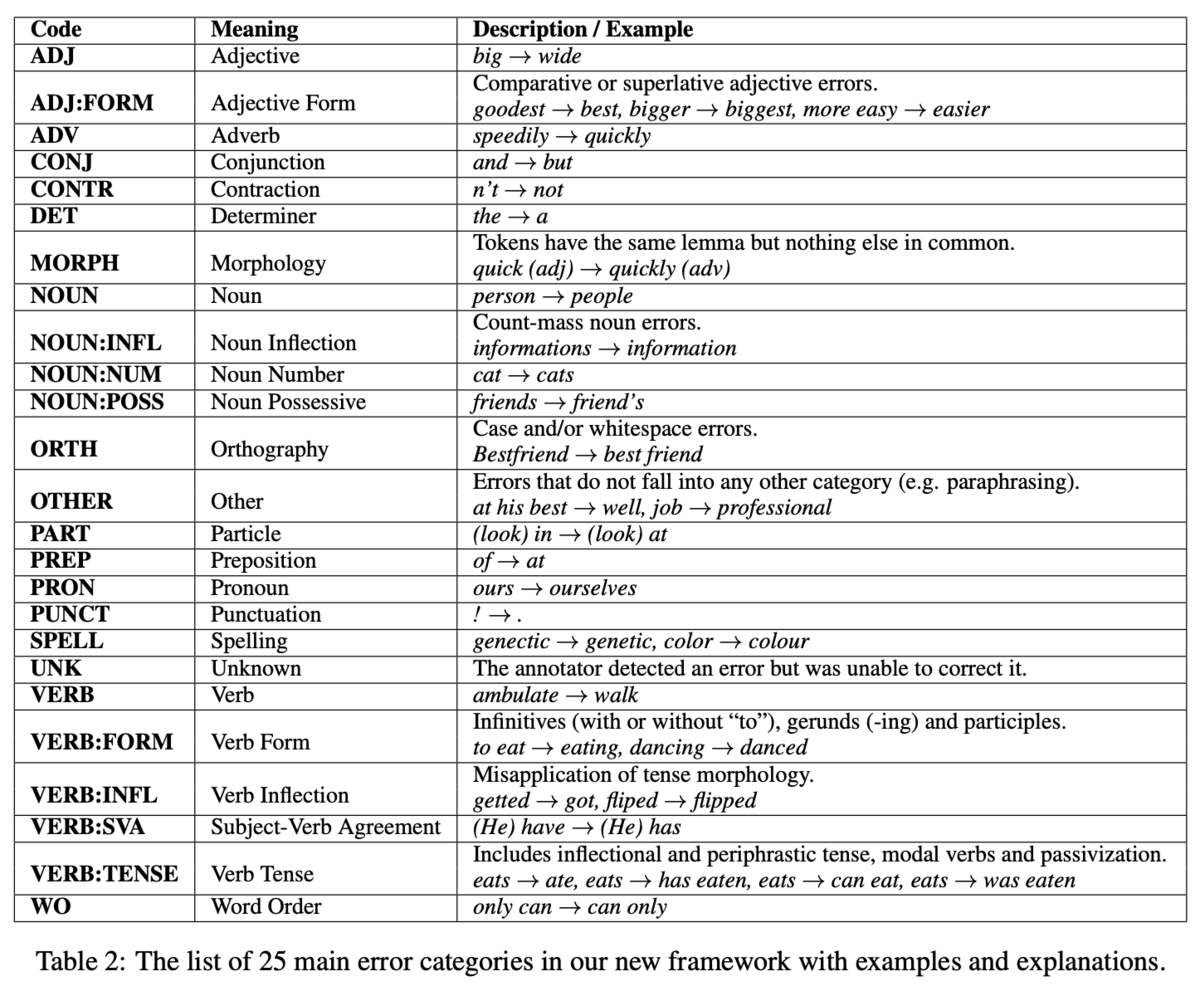
この論文では,訂正情報を入力とし,エラータイプを出力とする分類器を提案しました.特に,50個程度のルールに基づいたルールベースな分類器を用いています.基本的には品詞に基づいてエラータイプを付与しますが,語順やスペル誤りといった品詞に依存しないエラータイプも考慮したルールになっています.例えば,「小文字化すると一致するか?」のルールでは,訂正情報がOrthography(例:we → We)のエラータイプに分類できるかどうかが分かります.
エラータイプは25種類を定義します(Table 2).これらのエラータイプは,それが置換,削除,挿入のいずれかを表す文字列R:,U:,M:を接頭辞として用いることができます.例えば,名詞に関する置換の誤りはR:NOUNと表すことができます.また,Rのみに注目すれば置換する誤り全体の評価が行えるし,NOUNのみに注目すれば,置換・削除・挿入を考慮せずに名詞全体の評価が行えるため,柔軟な視点で評価できることが利点です.
このルールベースな手法には説明性や一貫性があると主張しています.先行研究には機械学習に基づいてエラータイプを分類するような手法も存在します.しかし,学習に用いるデータが大量に必要なことや,あるデータセットで学習した分類器は,ドメインの違いから他のデータセットでは正しく分類できない可能性もあります.一方,ルールベースな手法では,言語情報のみを用いてエラータイプを付与するので,データセットに非依存に適用できます.
エラータイプ分類器の評価
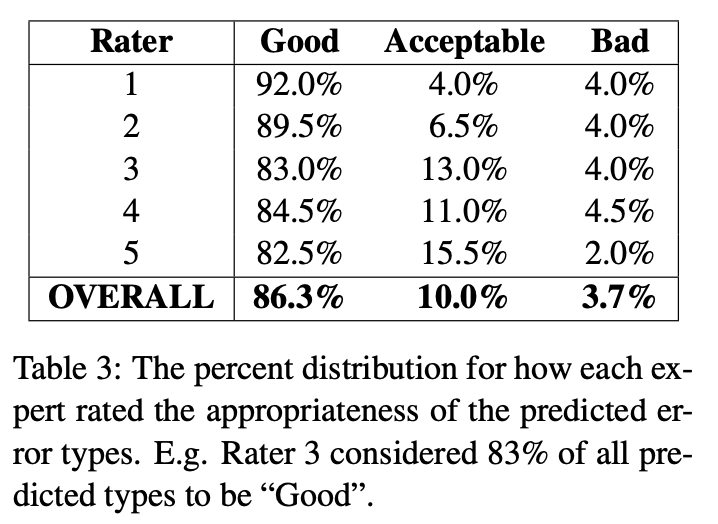
事前実験として,エラータイプ分類器の性能を人手で評価しています.具体的には,訂正情報と分類されたエラータイプを評価者に見せて,「良い」,「許容できる」,「悪い」の3段階で評価しました.「許容できる」は,付与されたエラータイプが適切ではあるが最適ではないと判断したときの評価です.
5人の評価者に実験してもらったところ,95%以上が「良い」または「許容できる」という結果でした(Table 3).また,評価者間のカッパスコアは0.724であり,評価者間でもある程度一致することを示しました.また,「悪い」と評価された事例を分析すると,その主な原因はPOSタグのエラーや構文解析のエラーが原因だったようです.この結果から,ルールベースなエラータイプ分類器は十分有効だと結論づけています.
エラータイプ別の性能評価
25種類のエラータイプを考慮した評価指標は存在しないので,新たに提案しています.評価は訂正情報のオーバーラップを見るだけで済みます.Felice et. al (2016)の手法を使えば,「原文ー正解文」と「原文ーシステムの訂正文」の間でそれぞれ訂正情報が自動で獲得できます.その後,「原文ー正解文」と「原文ーシステムの訂正文」の訂正情報のオーバーラップを見ることで評価できます.この指標ではTP,FP, FNを定義することができます.それぞれの指標は次のとおりです.
- TP:単語インデックスのスパンと訂正前後の文字列が一致するもの
- FP:「原文ーシステムの訂正文」の訂正情報であって,「原文ー正解文」の訂正情報にないもの
- FN:「原文ー正解文」の訂正情報であって,「原文ーシステムの訂正文」の訂正情報にないもの
また,エラータイプでグルーピングすることにより,エラータイプ別の評価も計算できます.
Gold ReferenceとAuto Reference
先ほど述べたように,評価には「原文ー正解文」と「原文ーシステムの訂正文」の2つの訂正情報を必要としますが,両者の訂正情報が異なる基準で付与されていれば,正しく評価が行えません.例えば,「原文ー正解文」は人がアノテートした訂正情報で,「原文ーシステムの訂正文」は ERRANTが自動でアノテートした訂正情報である場合が該当します.そこで,両者をERRANTの基準に合わせるために,既存の訂正情報をERRANTの基準に変換する機能を提供しています.
また,再アノテーションの結果が人のアノテートの結果と遜色ないことを示しました.具体的には,CoNLL-2014 Shared TaskのテストデータをERRANTで再アノテートし,これをreferenceとして参加システムを評価しました.Table 4では人がつけた既存のアノテーションをGold,ERRANTで再アノテートしたものをAutoとしています.スコアに大きな違いがないことから,ERRANTのアノテーションは人のアノテーションに遜色ないという結論です.
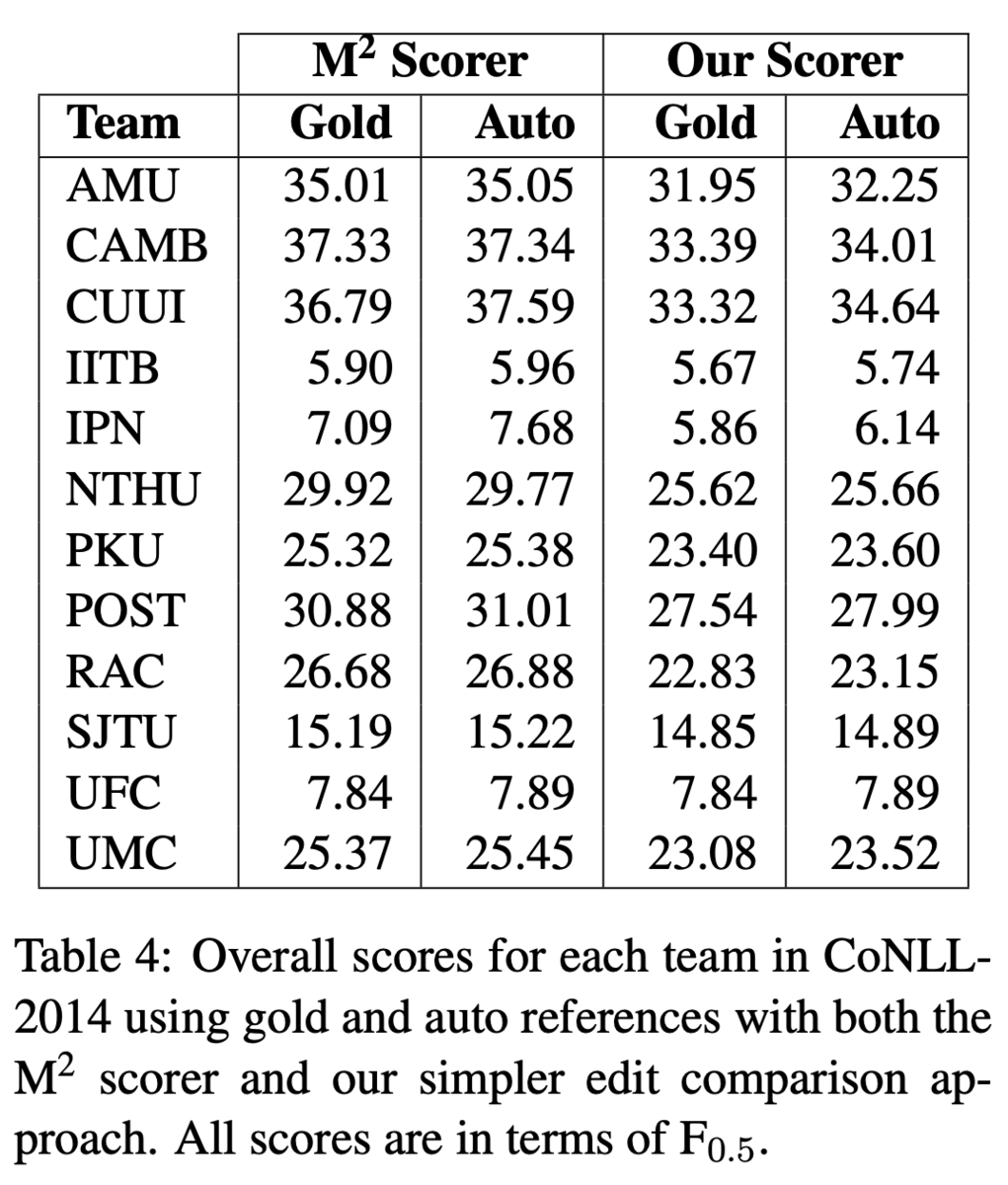
M2スコアラとの違い
Table 4からもわかるように,ERRANTの評価値は,M2スコアラと比較してF_0.5が低めに出る傾向があります.しかし,これはERRANTが性能を過小評価しているわけではなく,M2スコアラが過大評価しているからだと分析しています.M2スコアラはその由来がMax-Matchであるように,True Positiveができるだけ多く,かつFalse Positiveができるだけ少なくなるように振る舞うためです.
CoNLL-2014 Shared Taskにおける再評価
ERRANTによる自動アノテーションと自動評価尺度を用いて,CoNLL-2014の参加システムを再評価しました.Table 5では,訂正の種類が挿入,削除,置換の3種類についてそれぞれ評価を行い比較しました.この結果,システムによってかなり訂正の傾向が異なることがわかりました.
最も注目すべき結果として,AMU, IPN, PKU, RAC, UFCの5チームは,削除すべき誤りを一切解けていないということでした.この理由として,UFCルールベースの手法が削除の訂正を考慮していないことや,SMTベースの手法が削除の訂正をうまく学習できないことだと分析しています.一方,CUUIの手法は削除すべき誤りを最も訂正できていました.
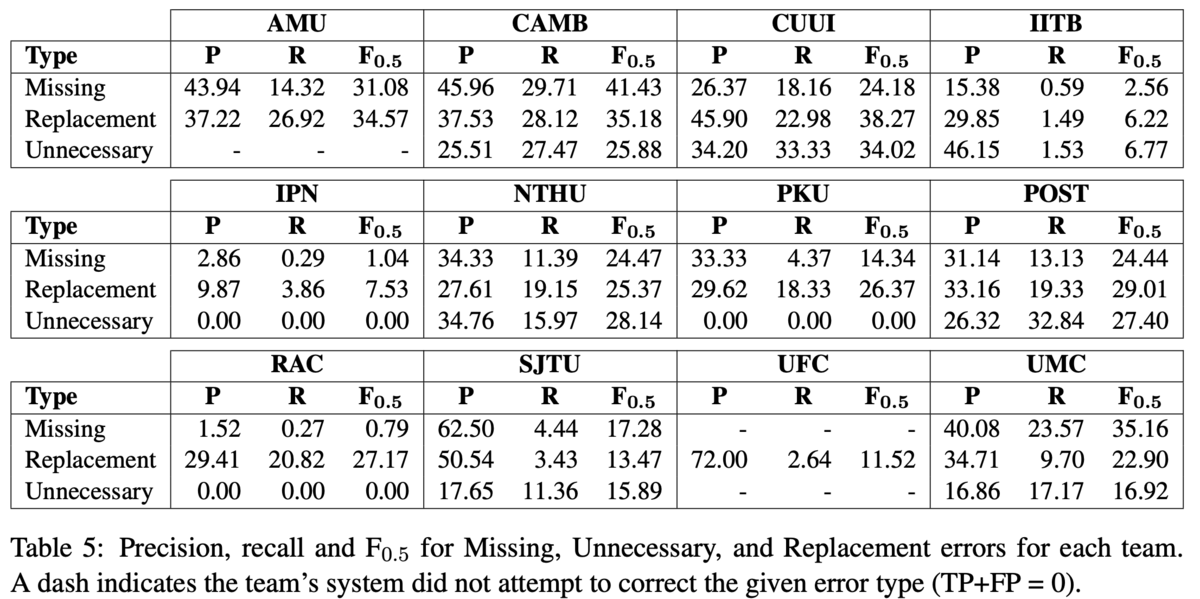
また,全てのエラータイプについて各システムのPrecison,Recall,F_0.5を分析しました(Table 6).まず分かるのは,IITB,IPN,POST3以外のシステムは,少なくとも1つのエラータイプにおいて最高性能を達成しています.これは,手法が異なれば解けるエラータイプが異なることを示しています.他にも,より粒度が細かいエラータイプに注目すると,それぞれの手法が得意なことが詳細に分析できました(Table 7, 本記事では割愛).
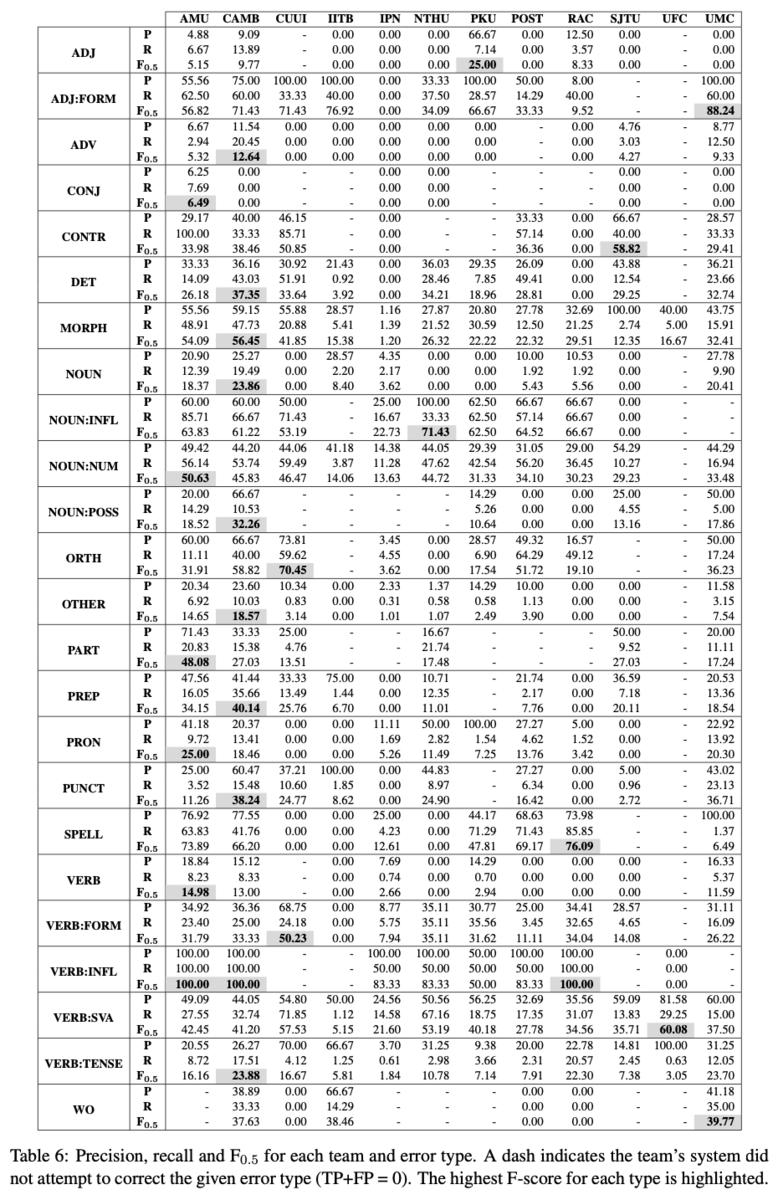
さらに,マルチトークンな訂正に限定した性能も評価しました(Table 8).マルチトークンな訂正とは,訂正前や訂正後のいずれかのトークン数が2以上になる訂正です.Table 8の結果からは,システムの多くはマルチトークンな訂正を苦手としていることがわかりました.今後はさらに結果の流暢さが求められることを考慮すると,このような誤りを解くためにはさらに工夫が必要だと分析しています.
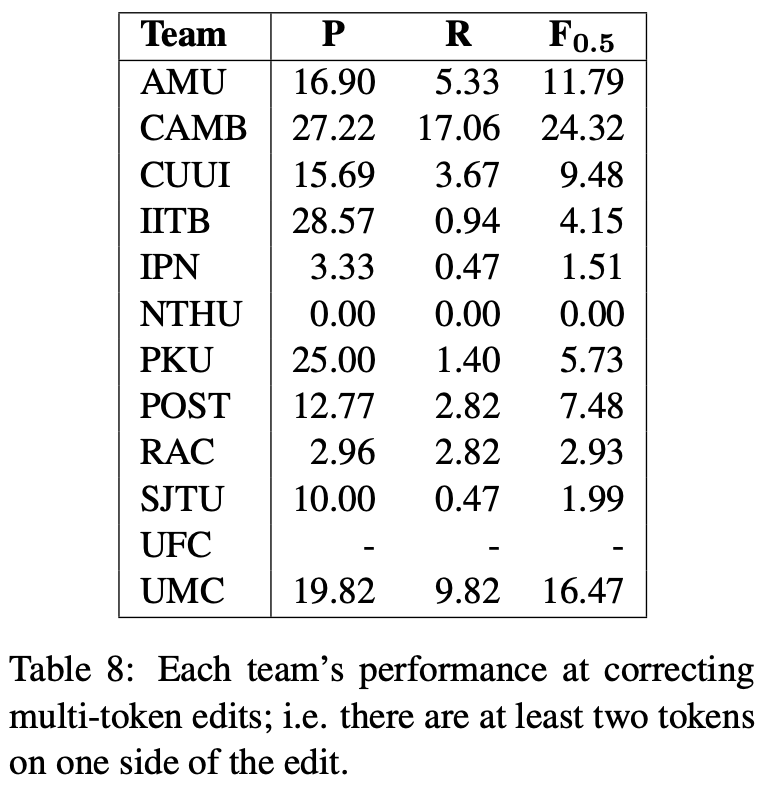
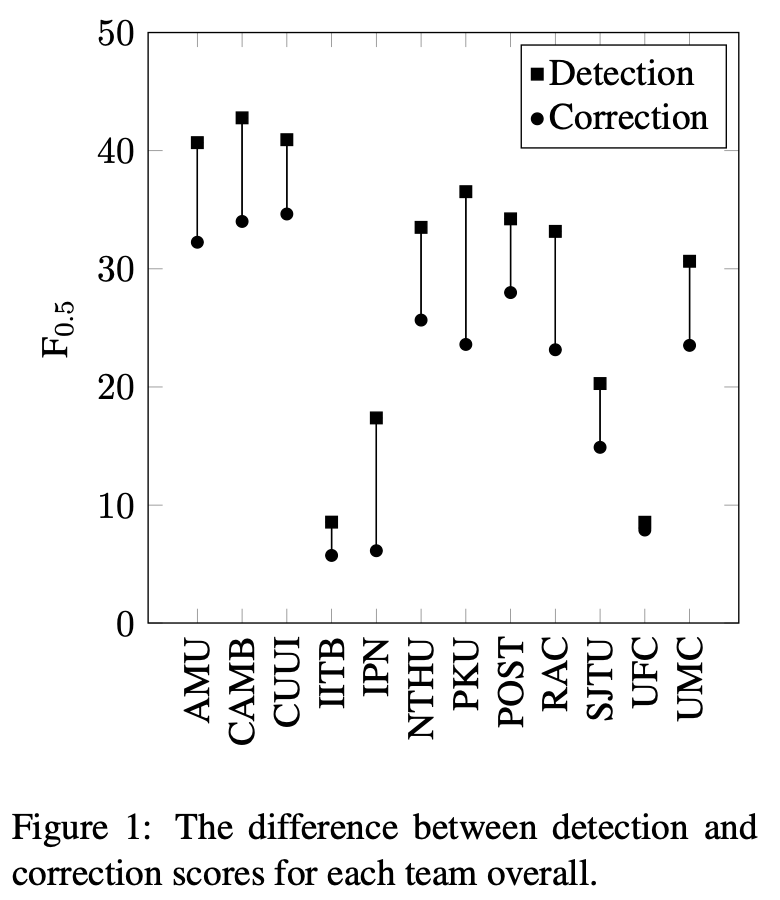
最後に,誤り検出の精度と誤り訂正の性能を比較しています(Figure 1).ここで,誤り検出の性能は,訂正後の文字列は気にせず,単語インデックスのスパンが正しく取れているかのみを測れば計算できます.Figure 1の結果からは,検出の性能が高いからといって訂正の性能も高いとは限らないことが分かります.また逆に,訂正の性能が低くても,検出の性能が高ければ学習者へのヒントとなる情報を提示する役割は果たせるとしています.
ERRANTの動かし方
実装はこちら: github.com
インストール:
python3 -m venv errant_env source errant_env/bin/activate pip3 install -U pip setuptools wheel pip3 install errant python3 -m spacy download en
ツールは3つの機能を提供しています.
errant_parallel -orig <orig_file> -cor <cor_file1> [<cor_file2> ...] -out <out_m2>
生文から訂正情報を自動で獲得します.入力は原文(-orig)とシステム出力文(-cor)の2つで,出力はM2フォーマットの訂正情報です.-corには複数のファイルを与えることができます.この場合,M2フォーマットの末尾である<annotator id>のところが0, 1, 2, ...とナンバリングされて記録されます.
errant_m2 {-auto|-gold} m2_file -out <out_m2>
既存のM2形式のアノテート情報を,ERRANT の仕様に沿ったものに変換します.-goldでは,アライメントはそのままに,エラータイプのみをERRANTが定義するものに変換します.-autoでは,アライメントやエラータイプを全てERRANTが再計算します.
errant_compare -hyp <hyp_m2> -ref <ref_m2> -ds -cat {1,2,3}
評価値を計算します.入力はM2フォーマットで表されたモデルの訂正情報(-hyp)と正解の訂正情報(-ref)です.-dsや-catは,評価値の出力をどのように行うかを指定します.-dsはSpan-based Detectionの評価値,-dtはToken-based Detectionの評価値を出力します.デフォルトは-scで,Span-based Correctionです.この3種類の違いは以下の表にあります.Detectionは訂正のスパン(単語インデックスのレンジ)のみで判断し,Correctionは訂正後の文字列まで見ます.

-cat {1,2,3}は,エラータイプの粒度を表します.-cat 1は置換誤り,不足誤り,余剰誤りの3種類の評価値のみ出力,-cat 2はエラータイプ25種類のみについて出力,-cat 3は各エラータイプについて置換,不足,余剰(最大55種類)のそれぞれの評価値を出力します.
参考文献
Felice, Mariano, Christopher Bryant, and Edward Briscoe. "Automatic extraction of learner errors in ESL sentences using linguistically enhanced alignments." Association for Computational Linguistics, 2016.
論文メモ:COLING2016, Automatic Extraction of Learner Errors in ESL Sentences Using Linguistically Enhanced Alignments
@inproceedings{felice-etal-2016-automatic,
title = "Automatic Extraction of Learner Errors in {ESL} Sentences Using Linguistically Enhanced Alignments",
author = "Felice, Mariano and
Bryant, Christopher and
Briscoe, Ted",
booktitle = "Proceedings of {COLING} 2016, the 26th International Conference on Computational Linguistics: Technical Papers",
month = dec,
year = "2016",
address = "Osaka, Japan",
publisher = "The COLING 2016 Organizing Committee",
url = "https://aclanthology.org/C16-1079",
pages = "825--835",
}
この論文は,Copyright © 1963–2021 ACL,Creative Commons Attribution 4.0 International Licenseの下で公開されています.
概要
文法誤り訂正(GEC)のための自動アライメント手法を提案しました.特に,Damerauの編集距離をベースとし,言語情報を考慮することでコストの計算部分を拡張します.また,2トークン以上の編集にも対応させるために,アライメントをマージする手法も提案します.人手のアライメントと比較する実験の結果,提案したアライメント手法は人と80%以上一致することを示唆しました.さらに,ルールベースに基づく手法であるため,編集情報の抽出を一貫性をもって行えるとしています.
自動アライメントの重要性
今までは,アライメントは手動で行われることが一般的でした.しかし,手動のアライメント手法には次の2点の問題点があると主張しています.また,自動のアライメント手法ではこれらを解決できるとしています.
アライメント作業は面倒
直感的にも,手動アライメントは面倒な作業です.edit-basedな評価を行うことを考えると,原文とモデルの出力文に対してのアライメントを毎回取る必要があります.これを毎回人手で行うわけにはいかないため,自動アライメント手法を確立することは重要です.一貫したアライメントが取れない
手動のアライメントは一貫性がないことがあります.人手で行われたアライメントを分析すると,[has → was] というアライメントもあれば,[has eating → was eating]というアライメントもあったようです.後者の例ではeatingという単語は変化していないため,[has → was]のみにした方が良さそうに見えます.自動アライメントではこのような違いは発生せず,一貫性のあるアライメントが取得できます.
アライメント手法
まず,大きな枠組みとしてDamerauの編集距離のコストからアライメントを取ります.Damerauの編集距離は,置換,挿入,削除,隣同士の単語の入れ替えを許す編集距離です.今まではノーマルなLevelshtein Distanceが用いられてきましたが,語順誤りにはうまく対応できませんでした.例えば,[A B → B A]のような訂正の場合,[A → ],[B → B],[
→ A]のように3つのアライメントに分かれてしまいます.そこで,入れ替えの操作も許すDamerauの編集距離を採用することで,語順入れ替えも「語順入れ替え」として処理できるようになりました.さらに,[A B C → B C A]のような3トークン以上の語順入れ替えに対応するために,コスト行列を対角線的に遡って探索するように拡張しています(Listing 1).

次に,Damerauの編集距離の置換コストを,言語情報を考慮したものに置き換えます(Listing 2).考慮する言語情報は次の4つです.
小文字化したときに一致するか
一致すればコストはとします.そうでなければ,次の2. 3. 4. の3つのコストを足した値とします.
lemma cost
metとmeetingのように,置換前後の単語が同じlemmaを持つ,もしくは派生形(derivationally related form)であればとします.
part-of-speech cost
置換前後の単語が同じ品詞なら,いずれでもないなら
とします.
character cost
置換前後の単語の文字レベルのDamerau-Levenshtein distanceを,アライメントの長さで割った値とします().
lemma costでは派生形(derivationally related form)という概念があります.ここで派生形は,置換前後のトークンのlemma集合が交差していることを指します.例えば,metとmeetingが派生形かどうか調べたいとして,各単語のlemma集合を考えます.metは動詞のみなのでlemmaはmeet,meetingは名詞と捉える場合と動詞と捉える場合でlemmaが異なり,それぞれmeeting,meetです.よって,lemma集合はそれぞれmeetとmeeting, meetであるので交差し,2つの単語は派生形とみなされます.

実験
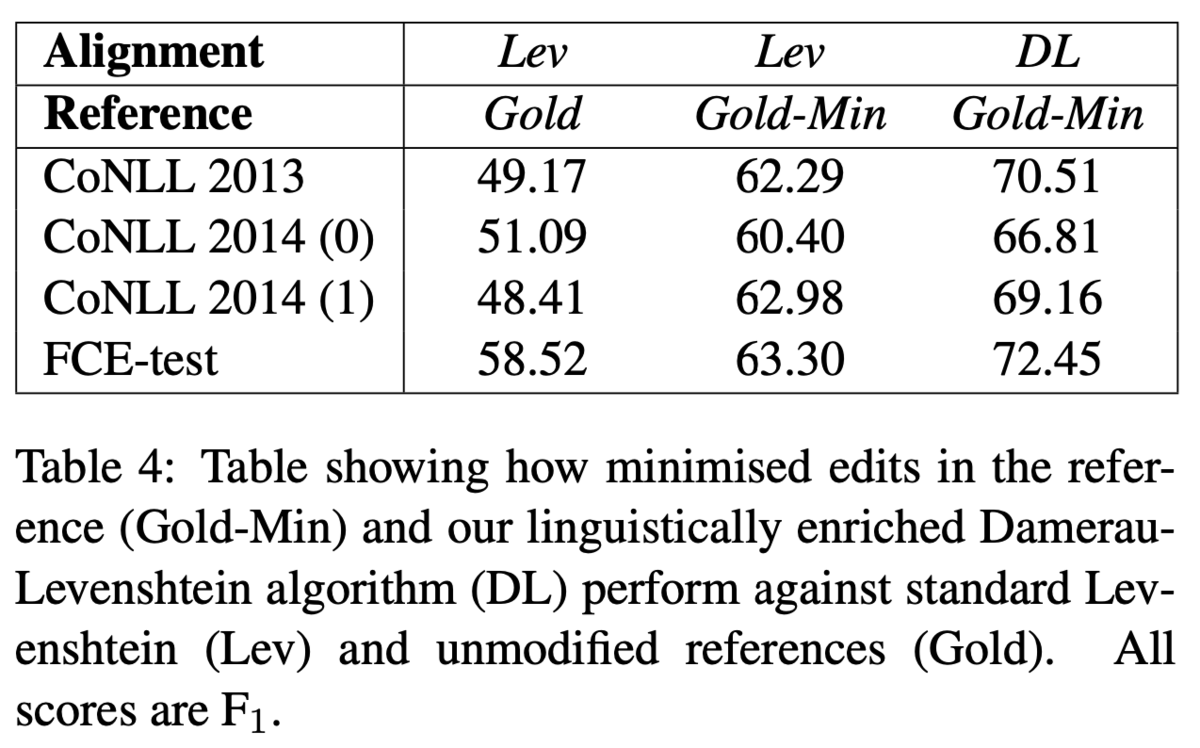
自動アライメントと手動アライメントを比較し,スコアを見る実験を行っています(Table 4).まず,Levenshtein Distanceによるアライメントと,人手で作成したGoldアライメントは50%程度の
スコアでした(Table 4,LevとGoldの列).
次に,人手アノテーションを最小限の訂正になるように修正したアライメントも作成しました.具体的には,両端から同じトークンを再帰的に削除します.この処理により,[has eating → was eating]のような訂正も[has → was]のみになります.このように修正を加えたGoldをGold-Minと呼んでいます.このデータを用いると,Levenshtein Distanceでは60%程度のスコア,Damerauの編集距離だと70%程度の
スコアでした.この結果から,アライメントの最小化を行う処理はアライメントをより正しく評価することができ,かつ,言語情報を取り入れたDamerau編集距離が人との一致率の向上に貢献することがわかります.
アライメントのマージ
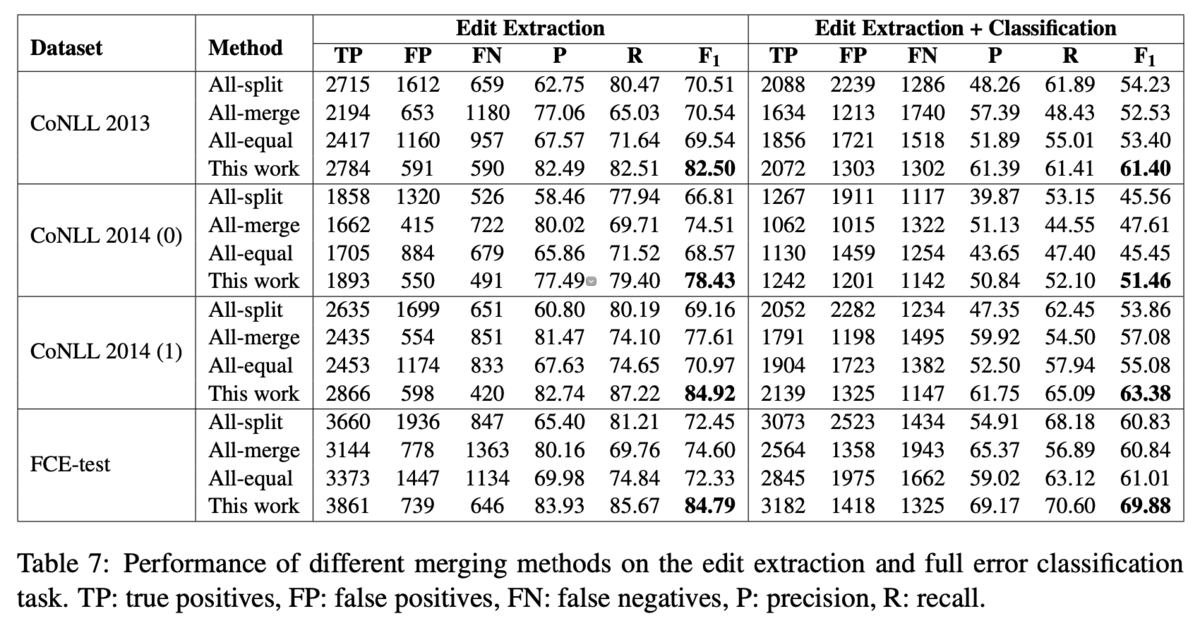
これまでに説明されたアライメントの手法では,2トークン以上の編集が分割されることがあります.人手のアノテーションを見ると,ほとんどの編集は0:1(1トークンを挿入),1:1(1トークンを別の1トークンに置換),1:0(1トークンを削除)のいずれかですが,0-2:0-2のような訂正もやはり存在します(Table 6).よって,得られたアライメントを適切にマージする必要があります.例えば,[wide spread → widespread]のように結合するような編集は,現状のアルゴリズムでは[wide → widespread],[spread → ]のように,1:1と1:0の2つの編集に分割されます(Table 5).このようなものはマージして[wide spread → widespread]とし,2:1の編集として扱う方が望ましいです.
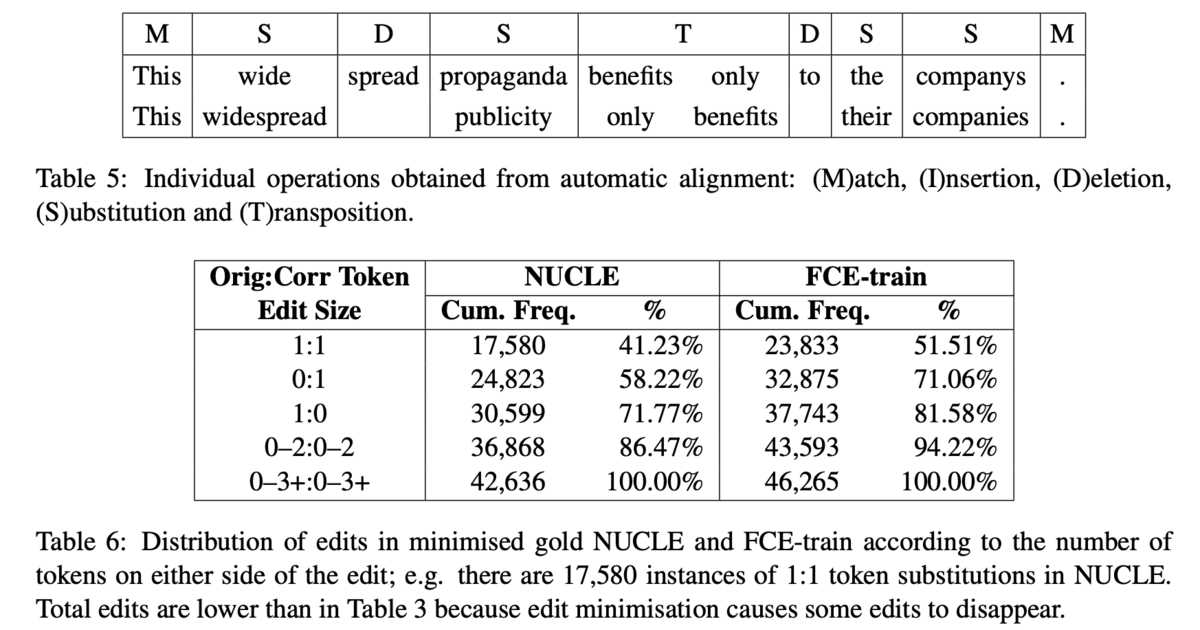
アライメントのマージは10個のルールに基づいて行います.(このルールに関しては,論文の記述を直接読んだ方が分かりやすいと思います.以下は参考程度で.)
挿入アライメント(M)で分割する. 例:アライメント列が
MSDSTDSSMなら,M, SDSTDSS, M句読点を含む編集で,その次にケース変更の編集があればマージする.
例:[, → .],[we → We]があれば,[, we → . We]入れ替えの編集があれば,それを独立にする.
所有格の接尾辞に関する編集は,その前の編集とマージする.
例:[friends → friend],[→ 's]があれば,[friends → friend 's]
トークンの間に空白を挿入もしくは削除する編集をマージする.
文字が70%より多く一致している単語で,かつ,その前のトークンと品詞が一致していなければ独立にする.
ある置換の編集の前に置換の編集があるとき,独立にする.
少なくとも一つの内容語が含まれる編集の組み合わせを全てマージする.
同じ品詞に関する連続した編集をマージする.
連続した編集の最後にある決定詞に関する編集は独立にする.
これらのルールは1>2>...>10の優先度で適用されます.また,あるルールを適用してマージ・分割が起これば,残りの未確定の部分列に対して再帰的に適用されます.Figure 1はその一例です.
アライメントのマージに関する実験
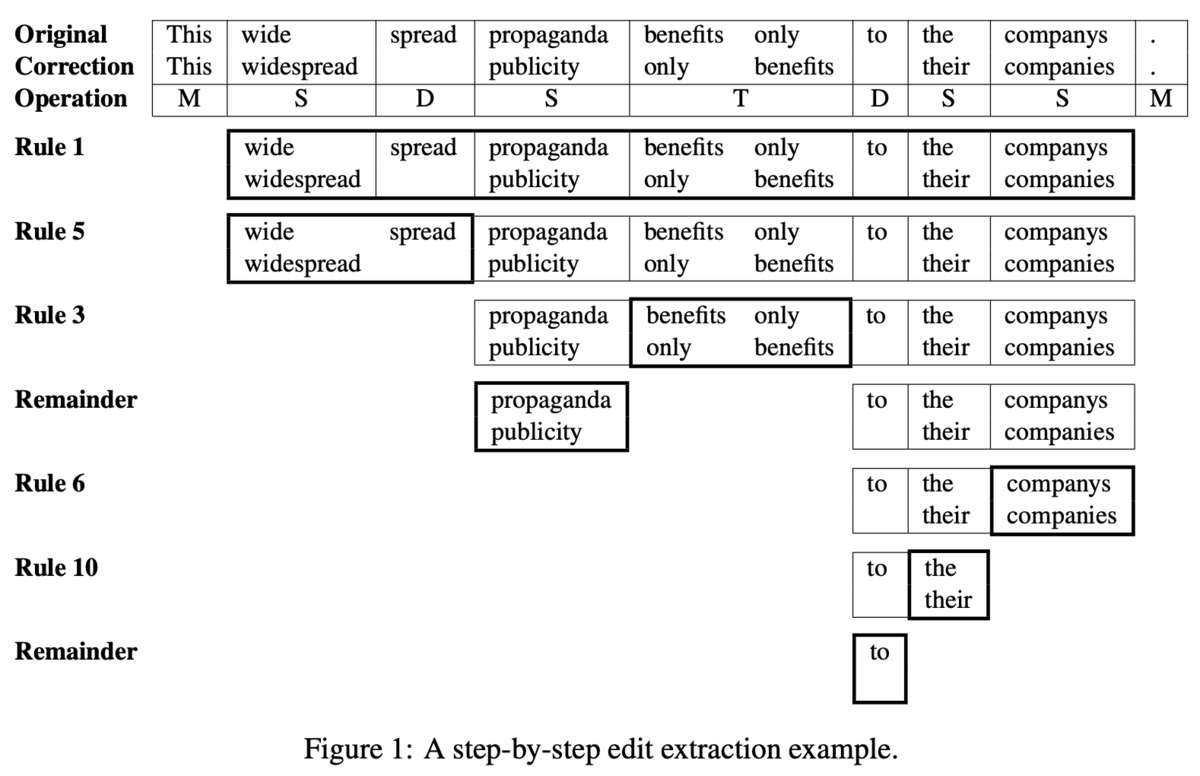
アライメントをマージすることで,さらに人との一致率が向上することが示唆されました.ベースラインとして,All-split(マッチしないアライメントは全て独立にする),All-merge(マッチしない連続したアライメントは全てマージする),All-equal(同じ操作であって,マッチしない連続したアライメントはマージする)の3つと比較しています.
結果はTable 7の通りです.提案手法が最も高い一致率を示しました.ただし,ベースラインの手法にはそれぞれ良いところがあるとしています.例えば,All-splitはTPは高くFNは低いが,FPも高くなります.これは2トークン以上に関わる訂正を無視するような設定になっているからです.一方で,All-mergeはFPの値が低くなる一方でTPは低く,FNは高くなります.提案手法はルールベースな手法によりアライメントを適切に分割・マージするので,All-splitとAll-mergeの良いところを利用できるため,一致率が高くなると分析しました.
それから,エラータイプの分類も考慮した一致率でも,提案手法は最も高い値を示しました.編集情報へのエラータイプの付与は,MaxEnt error type classifierを利用したとしています.
考察
ここまでに行ってきたアライメントの性能評価は,どうしても過小評価されています.例えば,同じ編集でも,人によって[has eaten → was eating],もしくは[has → was] + [eaten → eating]のようにバラつくことがあります.このようなばらつきは最小化(Gold-Minを作ること=端から一致したトークンを消すこと)を実施しても解消されないため,自動アライメントはいずれか一方にしか正解の判定を得られません.
他のデメリットとして,複数の誤りを扱う編集や,編集の途中に未編集のトークンが存在する訂正はうまくマッチしないことがあります.(Gold-Minは両端からのみ未編集のトークンを消すので,途中に存在する未編集トークンは最小化できない.)
一方でメリットは,出力に説明性があること,一貫性があることです.ある編集がマージ・分割された理由を知りたいときは,その操作を実施したルールから説明できます.また,ルールベースに基づいているので,編集の抽出に一貫性があります.
最後に,自動アライメントの先行研究と比較し,提案手法がF1スコアを大きく上回っていることを示しました(Table 8, 9,本記事では割愛).
論文メモ:EMNLP2020, Improving the Efficiency of Grammatical Error Correction with Erroneous Span Detection and Correction
EMNLP2020,Improving the Efficiency of Grammatical Error Correction with Erroneous Span Detection and Correctionの論文メモです.
@inproceedings{chen-etal-2020-improving,
title = "Improving the Efficiency of Grammatical Error Correction with Erroneous Span Detection and Correction",
author = "Chen, Mengyun and
Ge, Tao and
Zhang, Xingxing and
Wei, Furu and
Zhou, Ming",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.emnlp-main.581",
doi = "10.18653/v1/2020.emnlp-main.581",
pages = "7162--7169",
}
ACL Anthology:
https://aclanthology.org/2020.emnlp-main.581/
この論文は,Copyright © 1963–2021 ACL,Creative Commons Attribution 4.0 International Licenseの下で公開されています.
概要
文法誤り訂正タスク(GEC)は,誤りを含む文から正解文への翻訳としてみなされ,EncoderDecoderのアーキテクチャ が使われてきました.しかし,GECでは誤りのないトークンについては入力から出力へコピーすることが多く,コピーの処理までEncDecのアーキテクチャに任せるのは非効率です.そこで,誤りスパンの検出器と,スパンの訂正器のパイプライン型のモデルを提案しています.結果,seq2seqに劣らない性能を維持したまま推論速度を50%程度削減することに成功しました.また,検出器の閾値を調整することで柔軟な推論が可能だとしています.
提案モデルのアーキテクチャ
アーキテクチャは,誤り検出器であるerroneous span detection(ESD),erroneous span correction (ESC)の2つをパイプライン的につなげたものです(Figure1).ESDは系列タギングに基づくモデルで,入力文の各トークンに対して正解か誤りかの2値をタグ付けします(Figure1 (a)).この結果をもとに,入力文に<s1></s1>のような誤りスパンを示す目印をつけます.
ESCはEncoder-Decoderなモデルです.Encdoerには誤りスパンの目印も含めた入力文を全て入れて,Decoderは目印をつけたスパン内のみ出力します(Figure1 (b)).

ESDを訓練する上では,あるトークンが誤りかどうかの正解情報が必要です.そこで,アノテーションツールであるERRANTと同じ方法でsourceとtarget間のアライメントを取ります.また,ESCの訓練時には,誤りのスパン以外にもランダムに選択したスパンも加えて学習させます.これはESDの検出エラーがESCに及ぼす影響を緩和するためです(ESDが誤って検出したスパンはESCが訂正しないことも大事).ランダムなスパンの選択は,SpanBERTの論文の3.1節に書かれている方法と同じです.これは,スパンの長さをGeometric distribution(小さい値に偏った分布)からサンプリングし,スパンの開始点を一様分布からサンプリングして作ったスパンを追加することを,文に占めるスパンの割合が閾値を超えるまで続けるものです.
データ
学習データとして,英語ではBEA-2019 Shared Taskの訓練データを使っています.さらに,事前学習として260M文の擬似データを用いています.この擬似データは,誤りでないトークンをランダムで選択し,そのトークンをConfusion-setで対応する誤りトークンに置換して作成します.
中国語のデータには,NLPCC-2018 Chinese GEC shared taskの公式データを使用します.
結果
英語(CoNLL-2014テストデータ,BEA-2019テストデータ)と中国語(NLPCC-2018テストデータ)で評価しています.
英語のデータセットでは,提案手法は先行研究のトップの性能には及ばないものの高速に動作するため,実応用に向いているとしています(Table 1).Table 1は3つのグループで比較が行われています.上のグループが擬似データによる事前学習なしのグループ,中央のグループが擬似データを用いた事前学習ありのグループ,下のグループがアンサンブルやリランキングなどのヒューリスティックな手法も加えたグループです.
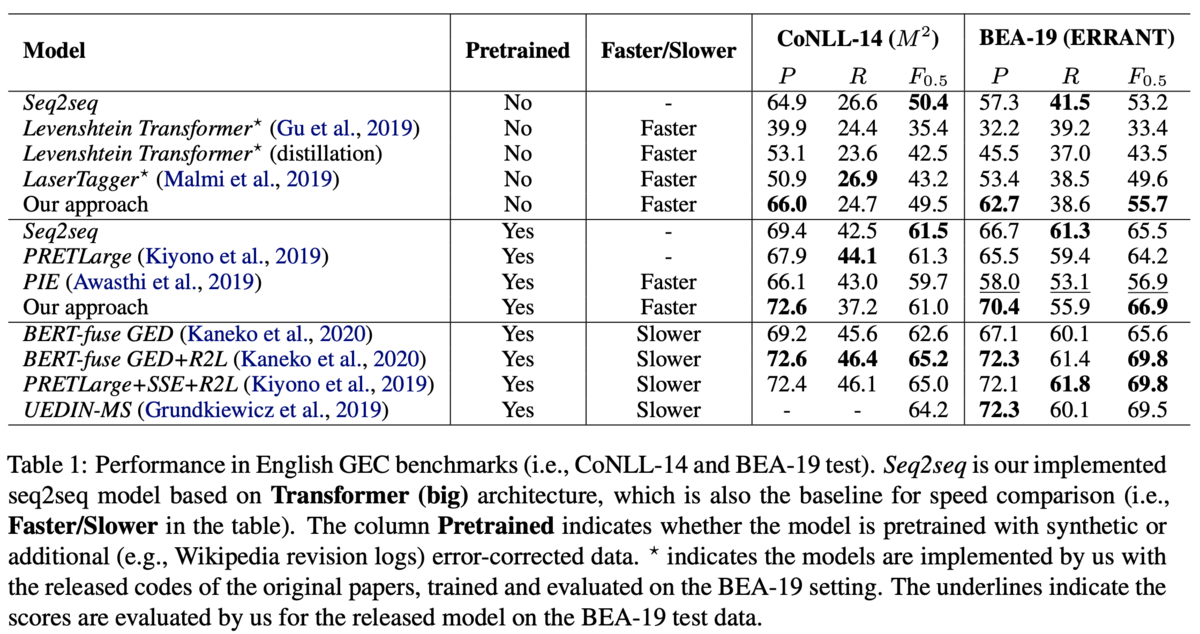
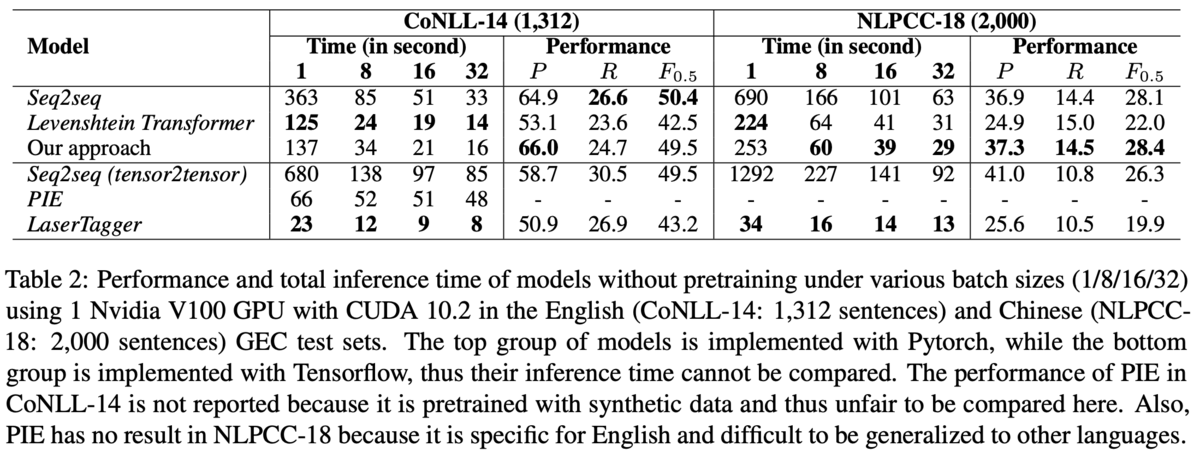
速度の比較では,全てを自己回帰で生成するseq2seqな手法の半分で推論可能だとしています(Table 2).Table 2は上のグループがpytorch実装,下のグループがtensolflow実装です.LanserTaggerやPIEは系列タギングに基づくモデルで,高速に動作することで知られています.また,英語と中国語の両方でseq2seqと遜色ない性能を達成しており,言語非依存で適用できることも示唆されます.
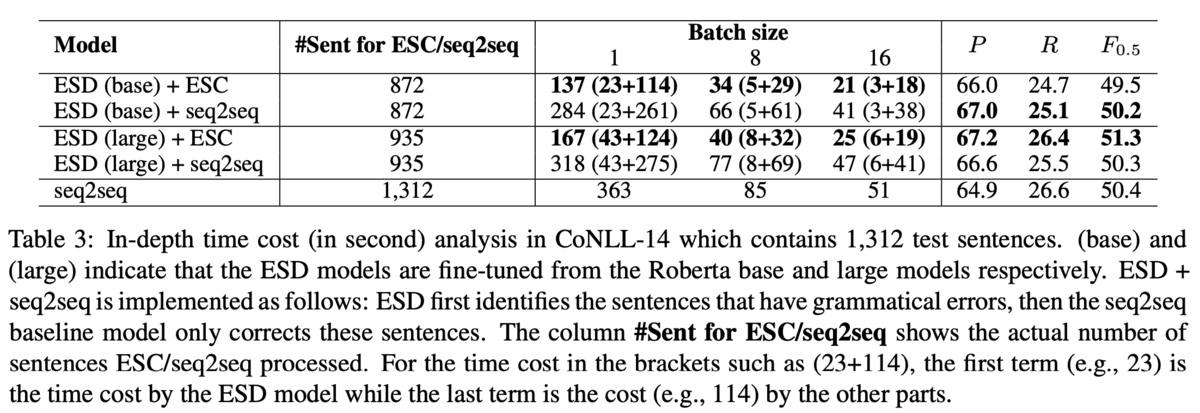
また,ESDやESCが処理した実数値も分析しています(Table 3).Table 3において,ESD+ESCは誤りスパンを検出→スパン内のみデコードする提案手法,ESD+seq2seqは誤りスパンが検出された文を(スパン関係なしに)全てデコードする手法を示しています.つまり,ESD+seq2seqとseq2seqを比較するとESDの貢献がわかり,ESD+seq2seqとESD+ESCを比較するとESCの貢献がわかります.結果,ESDはseq2seqよりもデコードする文を400文程度減らしており,ESCは時間を半分程度に削減することに成功しています.また,ESCはデコードするトークン数を1/3程度減らす効果があるようです(21,065 → 7,647).
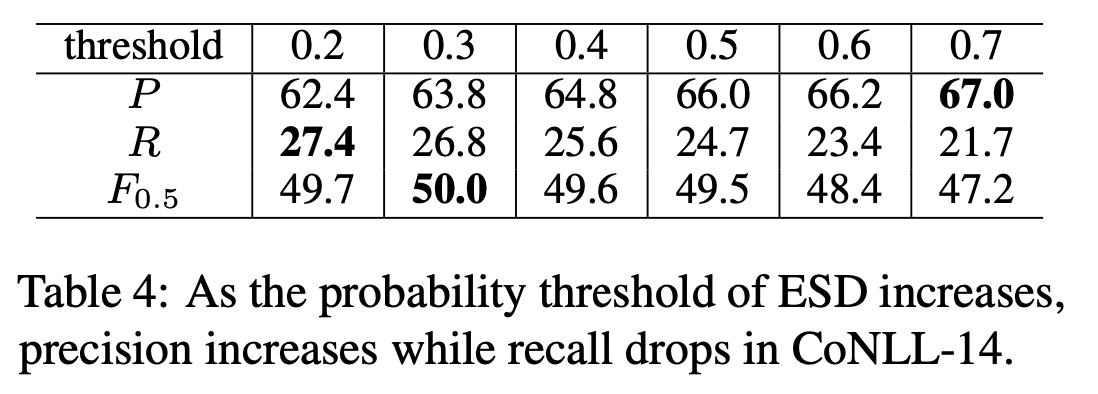
それから,ESDの閾値を調整することで,モデルの振る舞いをPrecision重視にするかRecall重視にするかを決められることも利点だとしています.ESDの閾値を高くするとPrecisionが向上してRecallが低下し,閾値を低くするとその逆になります.これは直感的にも正しいですし,実験でも示されています(Table 4).
論文メモ:ACl2021, Instantaneous Grammatical Error Correction with Shallow Aggressive Decoding
ACL 2021 long paper, Instantaneous Grammatical Error Correction with Shallow Aggressive Decodingの論文メモです.
@inproceedings{sun-etal-2021-instantaneous,
title = "Instantaneous Grammatical Error Correction with Shallow Aggressive Decoding",
author = "Sun, Xin and
Ge, Tao and
Wei, Furu and
Wang, Houfeng",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-long.462",
doi = "10.18653/v1/2021.acl-long.462",
pages = "5937--5947",
}
この論文は,Copyright © 1963–2021 ACL,Creative Commons Attribution 4.0 International Licenseの元で公開されています.
概要
文法誤り訂正のためのモデルとして,Shallow Aggressive Decoding (SAD)を提案しています.SADは,seq2seqのモデルにおいてデコーダを工夫することで高速な生成を可能にします.具体的には,Aggressive Decodingと呼ばれるteacher forcing的な生成手法と,Re-decodingと呼ばれる自己回帰的な生成方法を切り替えながら生成します.さらに,seq2seqのアーキテクチャとしてエンコーダの層を増やしてデコーダの層は減らすことで高速化します.結果,完全な自己回帰型のseq2seqモデルよりも10倍程度高速で,かつ高性能になりました.
推論方法
推論は,Aggressive DecodingとRe-decodingの2つを交互に切り替えることで行います.
Aggressive Decodingは,一つ前の系列をteacherとしてTeacher-Focing的に生成する手法です.特に,初回のAggressive Decodingではソース文をteacherとして系列を生成します.形式的には(2)式に従います.ここでがモデルの出力,
が一つ前の系列,
がソース文の系列を表しています.初回に限り,
です.
は当然givenなので,並列計算が可能です.後で議論がありますが,Aggressive Decodingでは系列の長さに制限を設けずに生成します.
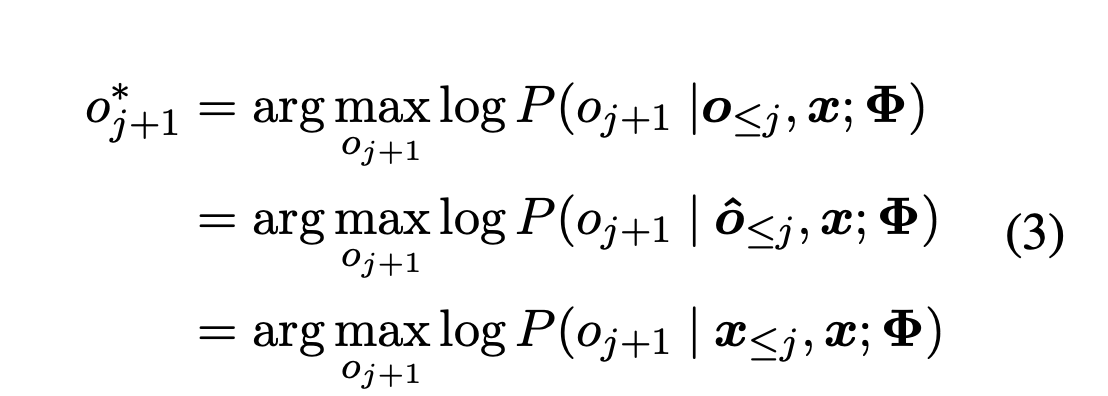
次に,生成した系列と
を先頭から比べて,完全に一致していれば
には誤りが無いとみなし,終了します.もし一致しない場合,先頭から比べて初めてトークンが異なるインデックス
を求めます.形式的には,
であり,
であるような
です.この時点で,
は生成結果として確定します.また,
より後ろの系列は破棄します.
インデックスが見つかれば,Re-decodingに切り替えます.Re-decodingでは,
から1単語ずつ自己回帰的に生成します.具体的には,
について式(4)に従って生成します.
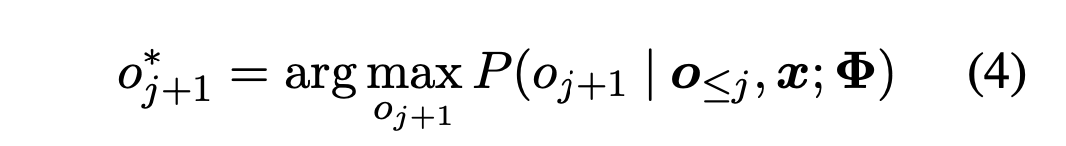
Re-decodingは,入力系列と一致するトークンのsuffix(末尾からの部分列)が見つかるまで行います.形式的には,
について
を推定したときに
となるような
が見つかれば良いです.もしこのsuffixが見つかれば,再度Aggressive Decodingに切り替えます.この時点で,
までが生成結果として確定します.
再度Aggressive Decodingに戻ってきたときには,Teacher-Focingに用いる系列として式(6)のようにconcatしたものを用います.つまり,過去にAggressive DecodingやRe-decodingによって得られた系列と,それ以降に対応するソース文の系列をconcatします.Re-decodingのときにソース文の系列とのsuffixの比較をしているので,「それ以降に対応するソース文の系列」は一意に決まります.
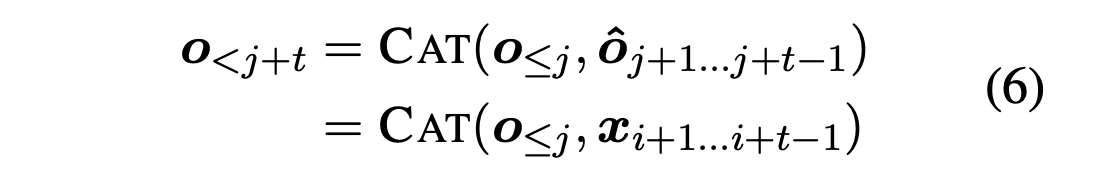
このように,Aggressive DecodingとRe-decodingを切り替えることで系列が生成できます.切り替えは条件を満たせば何度でも行われます.Aggressive Decodingは並列計算可能で高速であり,Re-decodingは自己回帰なので低速です.しかし,全てを自己回帰で生成するよりは明らかに高速に動作します.
また,Aggressive Decodingにおいてさらに低コストに計算するため,デコーダを浅くするshallow decoderを採用しています.
これらをより一般化したアルゴリズムはAlgorithm1に示されています.

Aggressive Decodingの評価
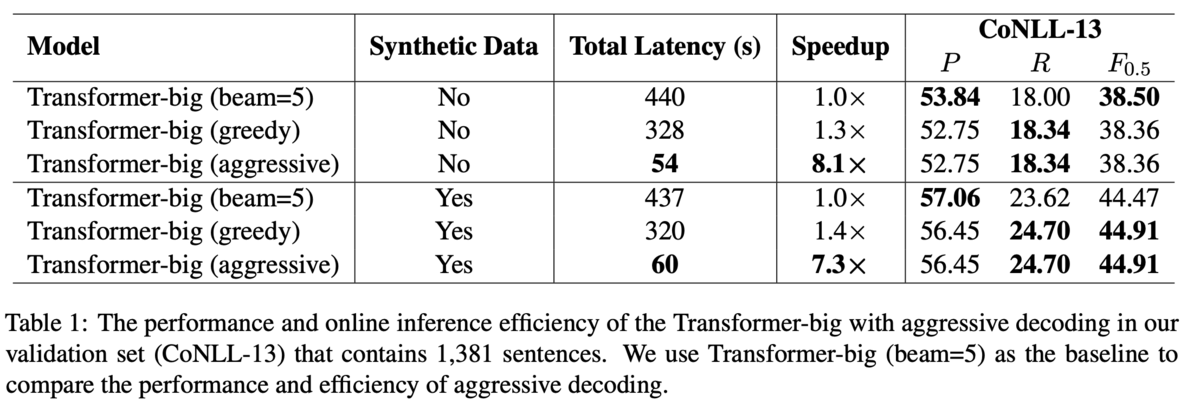
評価データで性能を見る前に,開発データとしてCoNLL-2013を使って性能を分析しています.
まず,提案手法の速度と性能を調査するために,全てを自己回帰で生成するseq2seqモデルをベースラインとして比較します.結果,提案手法は明らかに高速に動作し,Recallは上昇するがPrecisionは低下する傾向にあるとしています(Table 1).
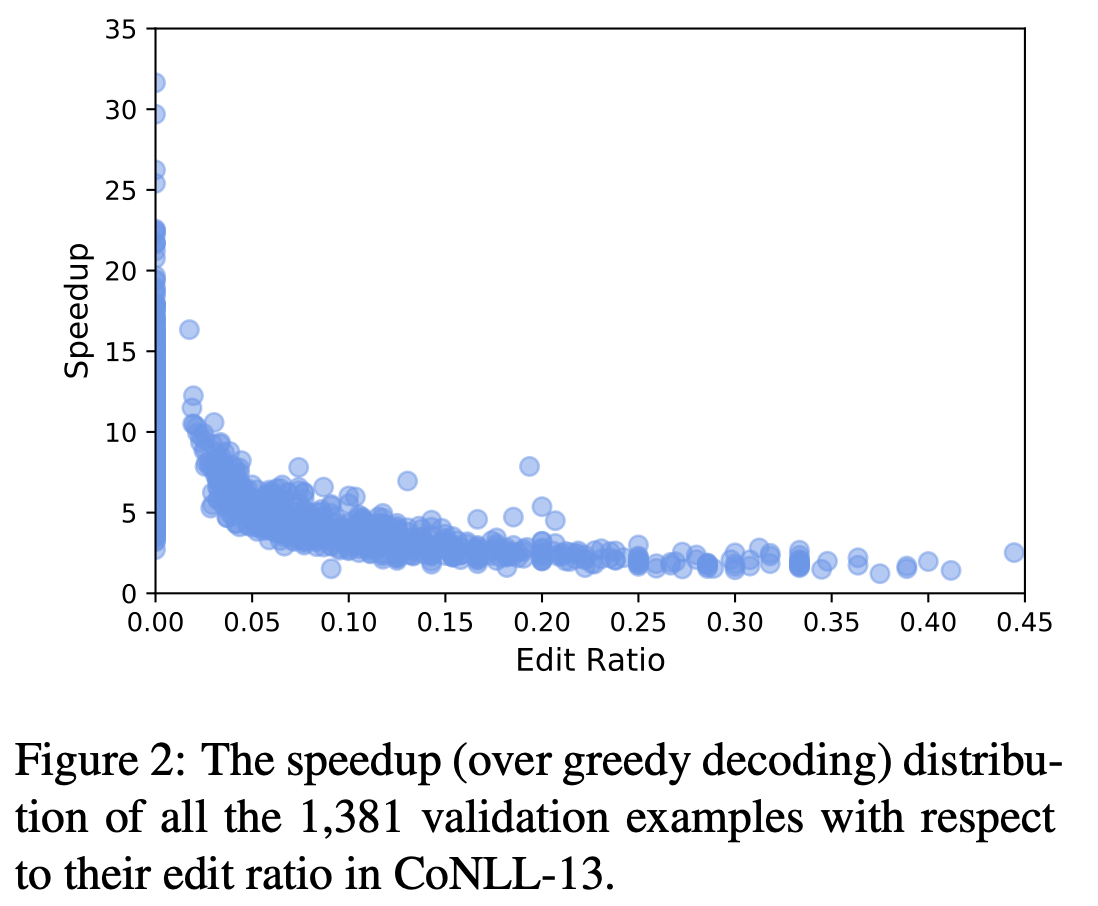
また,編集率が高いほど速度が低下します(Figure 2).この理由として,編集率が高いと低速なRe-decodingが頻繁に実行されるからだと分析しています.これはTable2に具体例があります(本記事では割愛).
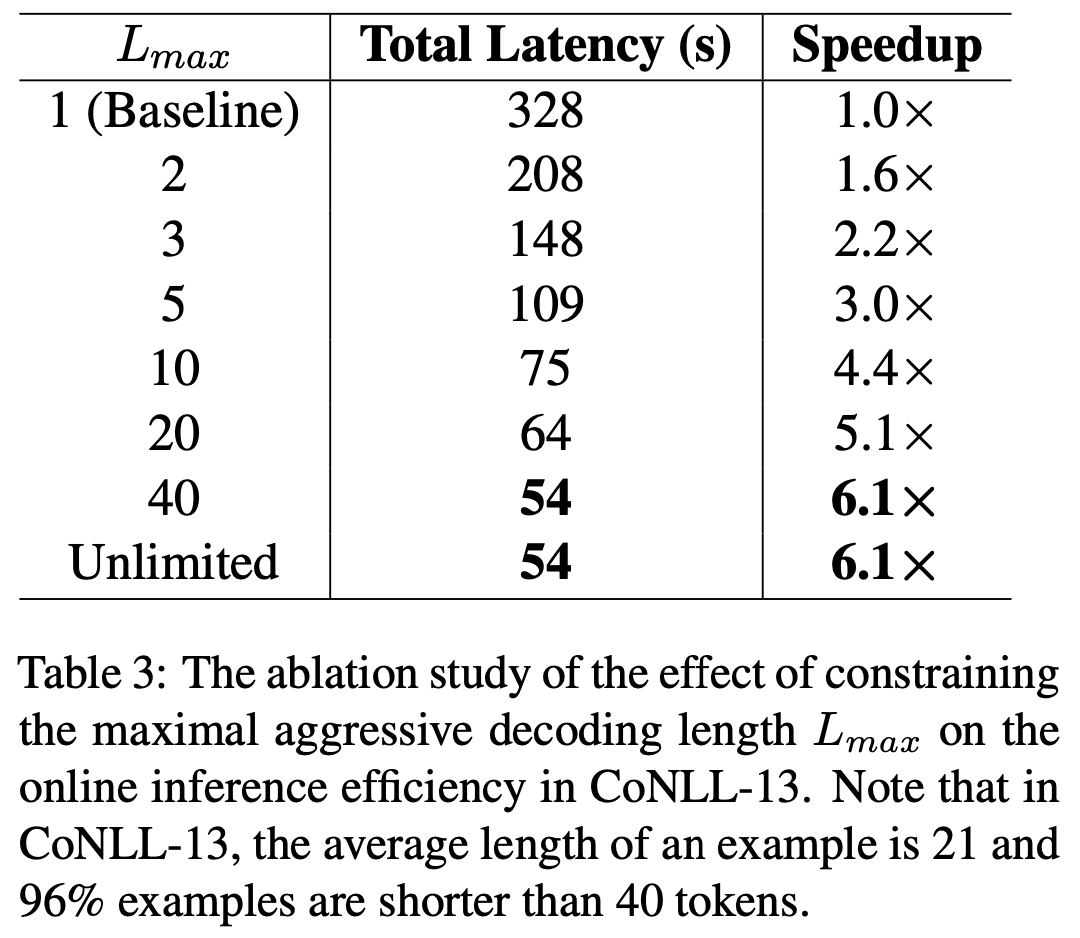
次に,Aggressive Decodingでデコードするトークンの長さは制限しなくて良いとしています(Table 3).Aggressive Decodingで長々と出力しても,入力系列と異なるトークンがあればそのトークン以降は破棄されてRe-decodingに移ってしまいます.よって長々と出力するのはリスクが大きそうですが,むしろ制限しないほうが高速でした.この理由として,GECの入力となる文にそこまで長いものは無いからだと分析しています.
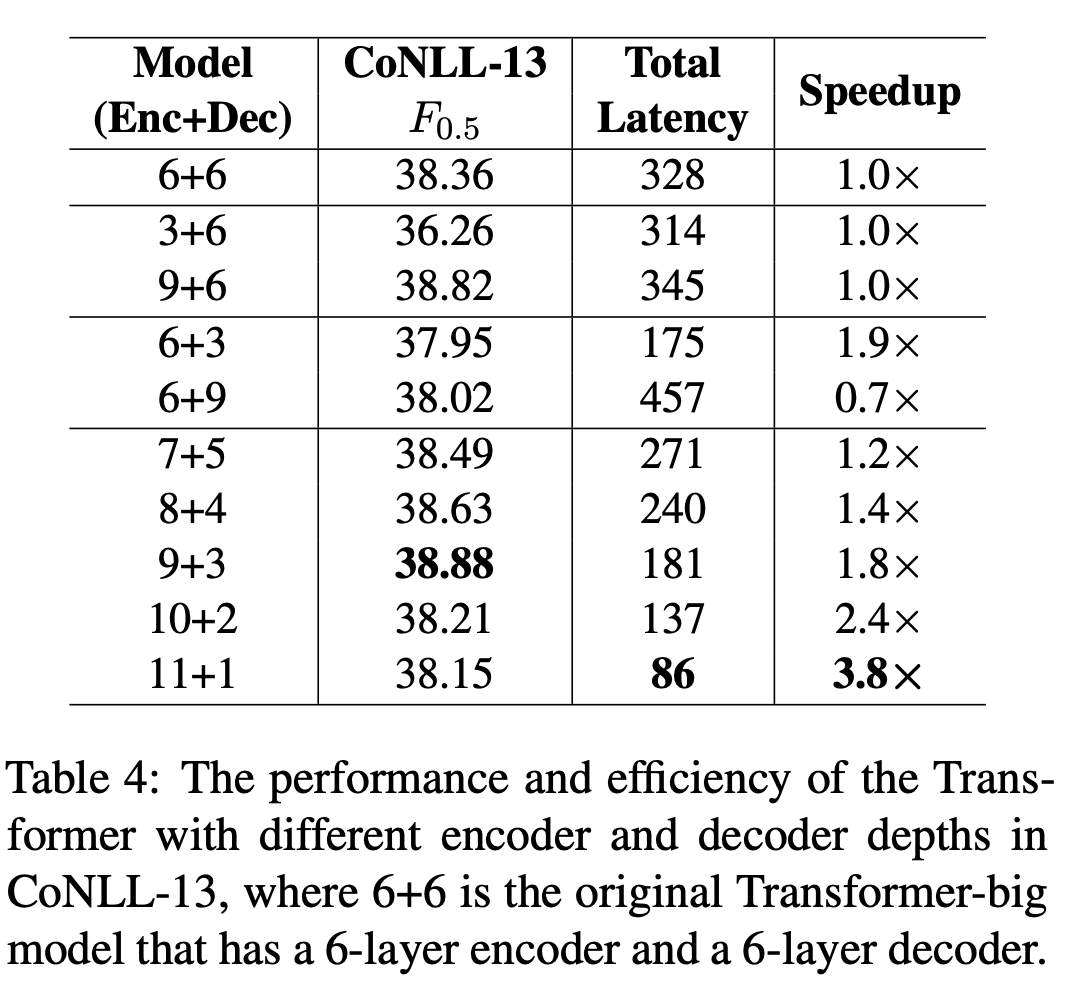
最後に,エンコーダは深く,デコーダを浅くするのが良いとしています(Table 4).Table 4中の3+6と9+6のブロックからはエンコーダを深くすると速度を維持したまま性能が向上することが分かり,6+3と6+9のブロックからはデコーダを深くすると速度が落ちるのに性能はほぼ変わらないことが分かります.11+1のように極端に深さを変えると性能が落ちることから,論文中では9+3を使っています.
結果
英語(CoNLL-14データセット,Table 5)と中国語(NLPCC-18データセット,Table 6)で評価しています.
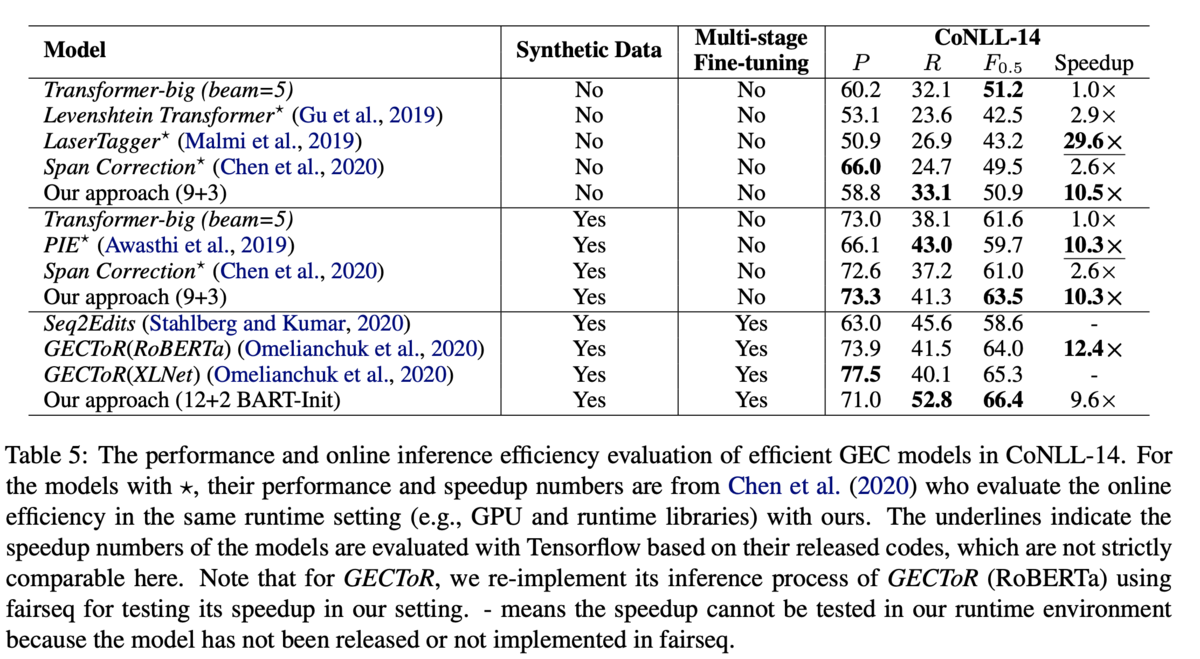
英語のデータセットについて,Multi-stage Fine-tuningなしの部門では,9+3のモデルが最高性能,かつベースラインを10倍高速化しています.また,先行研究のGECToRではBERTなどの事前学習モデルを用いていることに倣って,12+2のモデルをBARTで初期化しています.その結果で66.4を達成しました.
中国語のデータセットでも,性能は完全自己回帰であるようなTransformerと同等の性能で,12倍もの高速化を達成しています.また,ここでは英語や中国語のように言語非依存なGECが行えることも貢献としています.例えば,GECを系列タギングとして解いたGECToRでは,英文法の事前知識をもとにg-transformationと呼ばれるタグを用いて訂正を行っていますが,このタグを用いると英語のデータにしか適用できません.一方提案手法はタグを使わないモデルですし,文法に関する事前知識は必要ないため,言語によらず適用できます.
論文メモ:BEA2021, Document-level grammatical error correction
@inproceedings{yuan-bryant-2021-document,
title = "Document-level grammatical error correction",
author = "Yuan, Zheng and
Bryant, Christopher",
booktitle = "Proceedings of the 16th Workshop on Innovative Use of NLP for Building Educational Applications",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.bea-1.8",
pages = "75--84",
abstract = "Document-level context can provide valuable information in grammatical error correction (GEC), which is crucial for correcting certain errors and resolving inconsistencies. In this paper, we investigate context-aware approaches and propose document-level GEC systems. Additionally, we employ a three-step training strategy to benefit from both sentence-level and document-level data. Our system outperforms previous document-level and all other NMT-based single-model systems, achieving state of the art on a common test set.",
}
この論文は,Copyright © 1963–2021 ACL,Creative Commons Attribution 4.0 International Licenseの元で公開されています.
概要
文法誤り訂正(GEC,Grammatical Error Correction)は文単位で処理を行うことが一般的でした.しかし,周囲の文脈も考慮することでより正確な訂正が期待できます.例えば,動詞の時制は周囲の文脈に出現する他の動詞などから推測できる可能性があります.そこで,文書単位のGECモデルを提案しました.結果としては,訂正対象の文と周囲の文脈を別々にエンコードし,デコーダ側で足すようなアーキテクチャが最も良いとしています.また,評価データとして従来の文単位の評価データではなく,文書単位の評価データを使って評価しています.
モデル
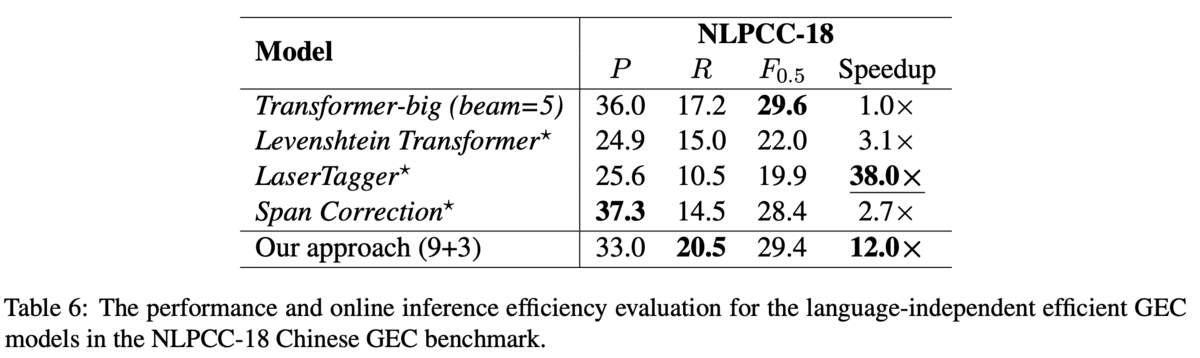
Baseline,SingleEnc,MultiEnc-enc,MultiEnc-decの4種類を比較しています.まず,BaselineはTransformerベースのseq2seqモデルです(Figure1 (a)).このモデルでは文脈を考慮せず,訂正対象の文のみを見て誤りを訂正します.SingleEncもアーキテクチャはTransformerベースのseq2seqですが,入力に周囲の文も合わせた一つの長い系列を用います.MultiEnc-encは,訂正対象の文と周囲の文を別々にエンコードし,それらの重みつき和をデコーダに送ります(Figure1 (b)).MultiEnc-decも訂正対象の文とその周囲の文を別々にエンコードしますが,デコーダ側には足さずに送り,2種類のアテンションを計算してから足します(Figure1 (c)).2種類のアテンションとは,のmasked multi-head self-attensionと,
から
への直接的なアテンションです.
は訂正対象の文のエンコード表現,
は文脈のエンコード表現です.
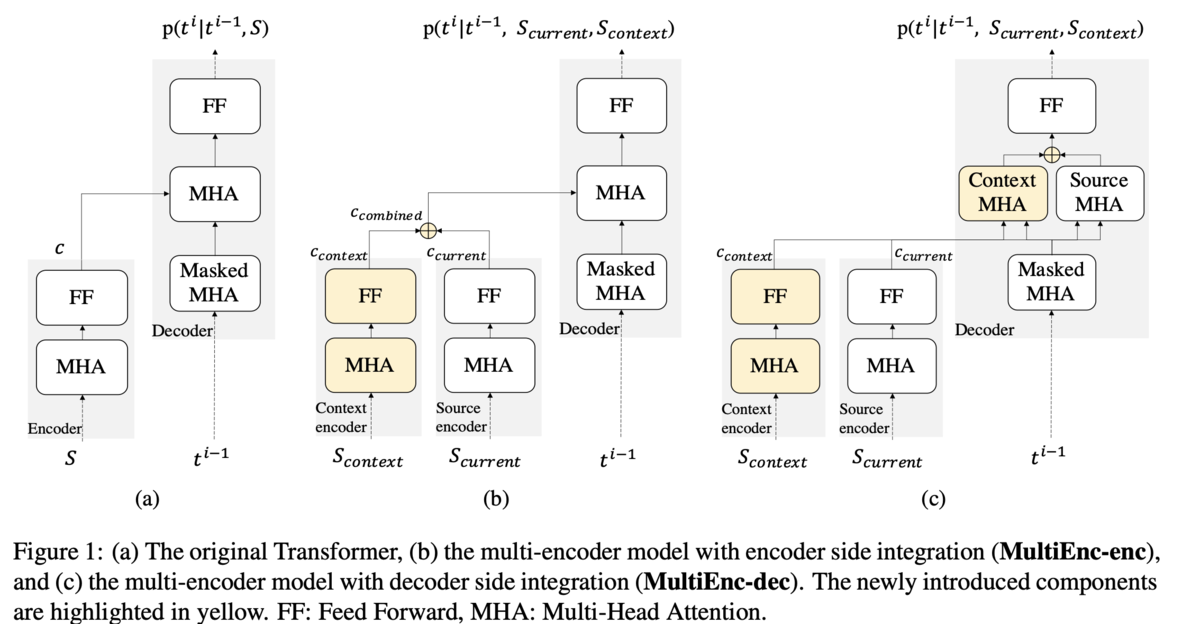
MultiEnc-encにおける重み付き和は,式(1)のように計算されます.ここで重みは式(2)のように計算されます.エンコードしたそれぞれのベクトルをconcatし,1層通すイメージです.

文書レベルGECの評価
これまでGECで使われてきた評価用データは,正解が文単位で用意されているため,文書レベルGECの性能を正しく評価できません.そこで,文書単位の評価データを作成しています.作成するといっても,既存の評価データの分割単位を文単位にするか文書単位にするかというだけです.CoNLL-2014やBEA-2019は,元々はエッセイをアノテーションしたデータセットで,これまではそれを文単位で分割して使ってきました.今回の文書レベルGECの評価では,文書単位に分割したデータを使います.M2形式で考えると,Sから始まる行には1文書が対応します.
ただし,この評価方法は複数のアノテーションが付与された評価データにおいて,少し厳しい評価となります.理由は,従来は文ごとに最適なアノテーションを選んで採点できていたのに対して,今回は文書ごとにしか最適なアノテーションを選べないからです.
訓練
MultiEnc-encとMultiEnc-decのモデルは3段階で訓練します.1段階目は文単位のデータを用いた事前学習です.この段階では文脈のデータがないので,文脈をエンコードする部分は無視します.データセットはCLC + FCE-train + W&I-train + NUCLEを使います.2段階目はCLCデータセットを用いた文書単位のデータで訓練し,3段階目はFCE-train + W&I-train + NUCLEの文書単位のデータでfine-tuningします.
BaselineとSingleEncのモデルもCLCで訓練し,FCE-train + W&I-train + NUCLEでfine-tuningします.BaselineとSingleEncは,訓練時に文単位のデータと文書単位のデータを混ぜることはしません.
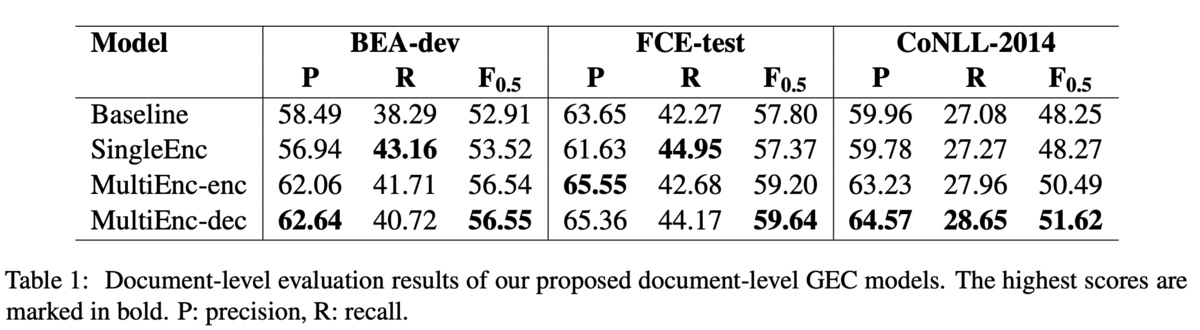
結果
結果は,MultiEnc-Decが全ての評価データで最高のを示しました.BEA-devではMultiEnc-encと違いはほぼありませんが,FCE-testとCoNLL-2014では性能が向上しているため,デコーダがより文脈を捉えられていそうだということでした(Table 1).
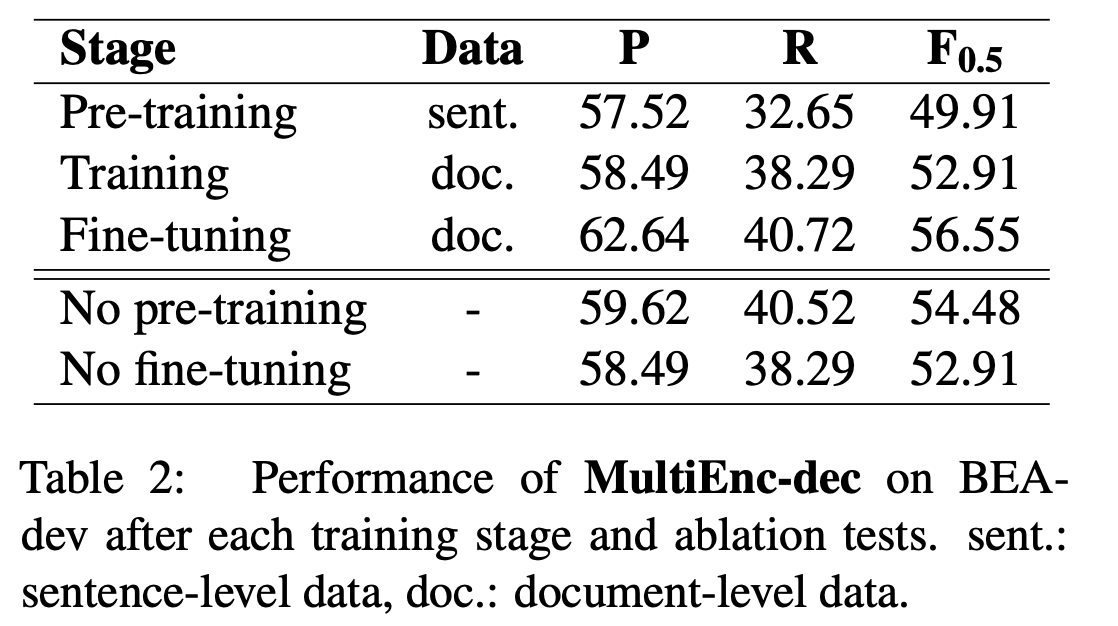
また,3段階の訓練におけるAblation studyの結果,pre-traningもfine-tuningも性能向上に寄与しているため,どちらも必要だということでした(Table 2).
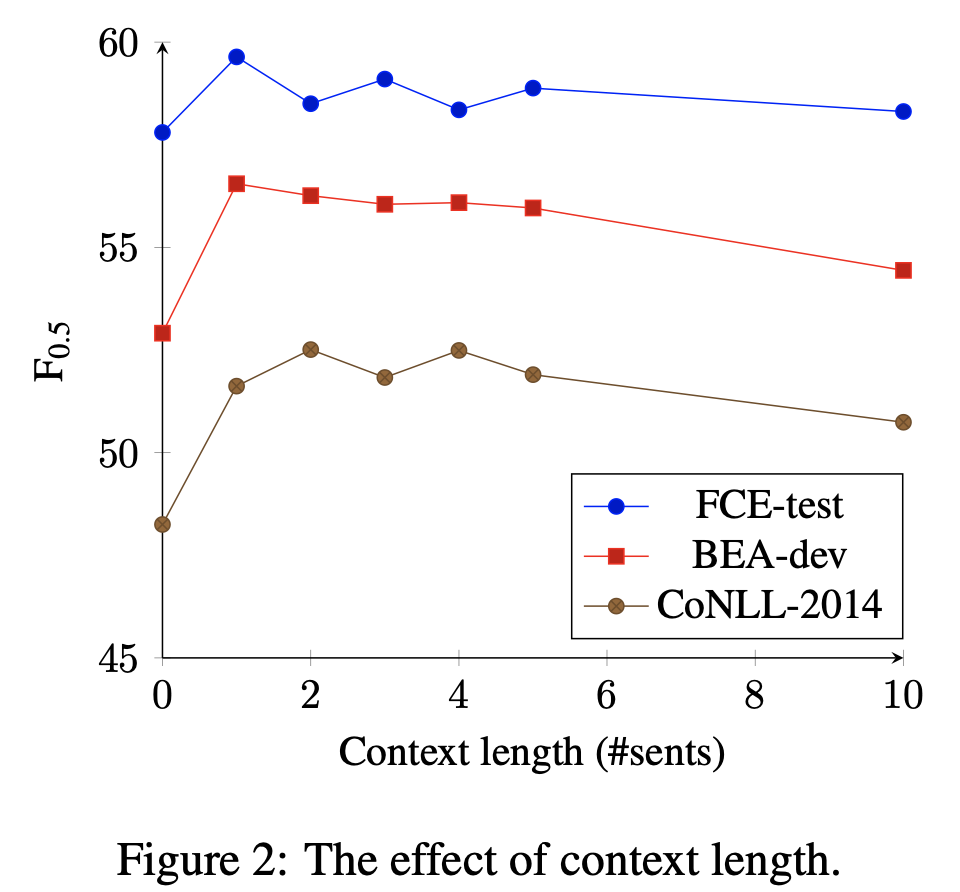
それから,入力する文脈は前後1~2文程度で良いそうです(Figure 2).BEA-devとFCE-testでは前後1文を考慮するのが最も性能がよく,CoNLL-2014では前後2文を考慮することが最も良いそうです.CoNLL-2014は他のデータセットに比べて1文書あたりの文数が2倍くらいあるので,より広い文脈の考慮が効いたのではと分析しています.また,使う文脈は長ければ良いというものではないこともわかります.
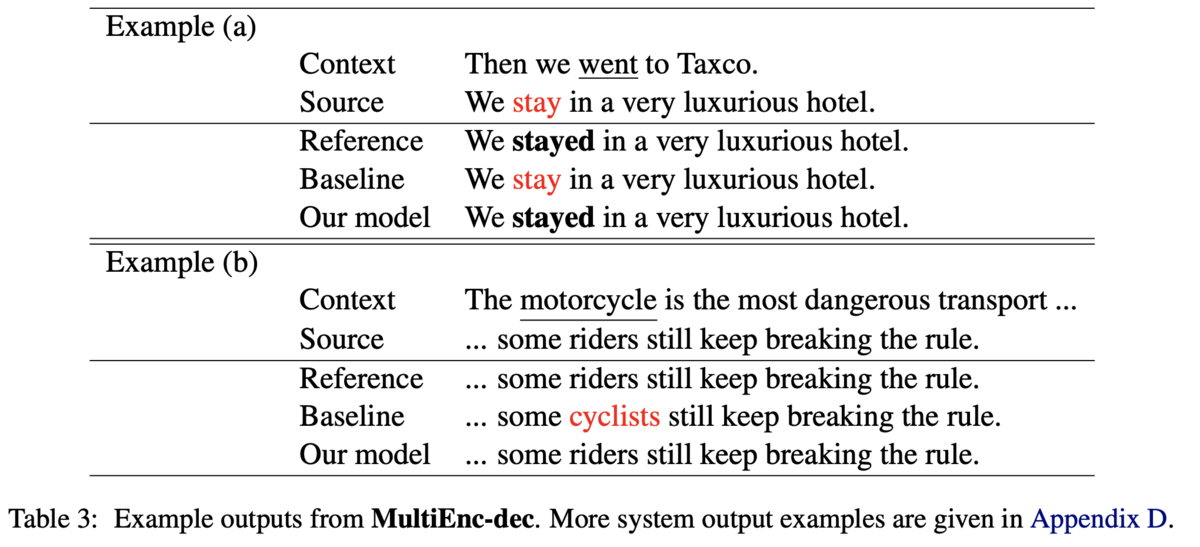
エラータイプ別の分析では,主語動詞の一致,動詞の時制,代名詞のエラータイプが顕著に解けるようになっていました.他にも,トピックに依存した語彙選択もうまくできた例があったようです.例えば,motorcycleに乗る人を指す単語としてはcyclistsよりもriderのほうが適切ですが,提案手法はriderを選択できています(Table3のExmaple (b)).
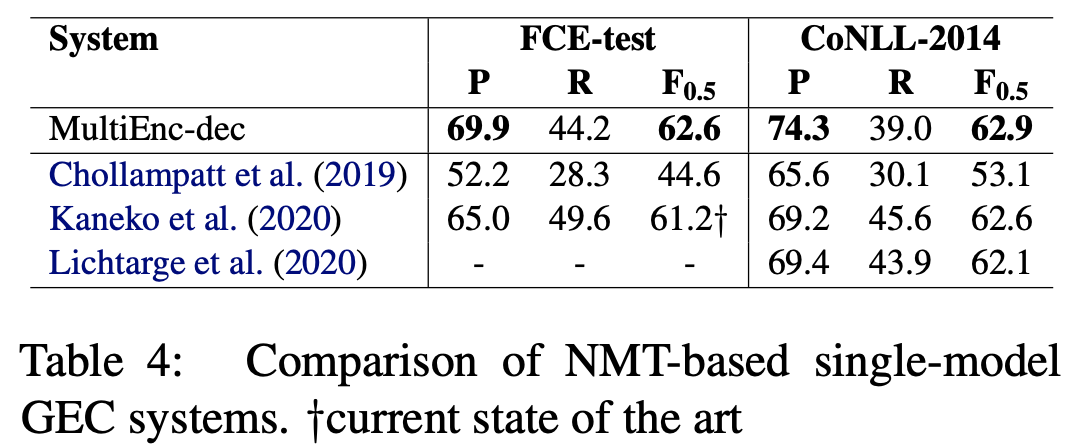
最後に,従来のNMT-basedなモデルとの比較を行っています.評価データとして文単位のCoNLL2014,尺度をMスコアラとして比較すると,提案手法は高いPrecisionを達成しており,FCE-testでは最高性能を達成しました.提案手法は擬似データを用いていませんが,擬似データを用いている先行研究と匹敵する性能を達成しています.
実装
文書単位の評価データを作るツールが公開されています. github.com
モジュールとしてerrantが必要です.
pip install errant
もしspacyの英語データが無いよ的なエラーが出たら
python -m spacy download en
として英語データを取ってこれば動きました.
論文メモ:NAACL2021, Comparison of Grammatical Error Correction Using Back-Translation Models
NAACL2021,Comparison of Grammatical Error Correction Using Back-Translation Modelsの論文メモです.
@inproceedings{koyama-etal-2021-comparison,
title = "Comparison of Grammatical Error Correction Using Back-Translation Models",
author = "Koyama, Aomi and
Hotate, Kengo and
Kaneko, Masahiro and
Komachi, Mamoru",
booktitle = "Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Student Research Workshop",
month = jun,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.naacl-srw.16",
doi = "10.18653/v1/2021.naacl-srw.16",
pages = "126--135",
}
ACL Anthology:
https://aclanthology.org/2021.naacl-srw.16/
この論文は,Copyright © 1963–2021 ACL,Creative Commons Attribution 4.0 International Licenseの元で公開されています.
概要
文法誤り訂正(GEC)では,データ不足を補うために擬似データ生成が行われています.擬似データの生成手法は逆翻訳の手法が主流であり,アーキテクチャは誤り訂正モデルと逆翻訳モデルで同じものが使われてきました.しかし,逆翻訳モデルには様々なアーキテクチャが適用可能であり,アーキテクチャによる訂正の傾向の違いは分析されていません.そこで,逆翻訳モデルとしてTransformer,CNN,LSTMの3つのモデルを用いて,性能の違いや訂正の傾向を調べています.結果,逆翻訳モデルとして単一のアーキテクチャを使うよりも,複数を組み合わせたほうが性能が上がるということを確認しました.
GECにおける逆翻訳を用いた擬似データ生成
GECでは文法誤りを含む文から正しい文へ変換することを目的とするタスクです.近年ではこの変換を翻訳するとみなして,seq2seqなモデルで解くことが主流です.しかし,seq2seqなモデルの学習には大量のデータが必要なのにも関わらず,GECの学習データは十分にありません.そこで,データの擬似生成をします.逆翻訳はデータ擬似生成手法の一つで,正解文を入力として誤り文を出力するように訓練します(GECの逆方向).こうして訓練した逆翻訳モデルの入力は正解文(誤りのない文)ですので,Wikipediaなどの単言語コーパスを入力すれば誤り文を擬似的に作ることができます.単言語コーパスは山ほどあるので,擬似データも大量に作れます.
実験
実験では,GECモデルは一種類に固定して,擬似データ生成のための逆翻訳モデルのアーキテクチャを変化させます.逆翻訳モデルはBEA-2019のtrainで訓練し,訓練後にWikipeadia(2020-07-06 dump file)から抽出した900万文を入力して擬似誤り文を生成します.アーキテクチャはTransformer,CNN,LSTMの3種類で実験します.また,異なるモデルの出力を合わせて1800万文とした擬似データや,seed値を変えた同じモデルの出力を合わせて1800万文とした擬似データでも実験します.評価はCoNLL-2014test,JFLEG,BEA-2019testの3つのデータセットで行います.
GECモデルはTransformerベースのEncoderDecoderモデルで,逆翻訳の手法で生成した擬似データ900万文(or 1800万文)で事前学習し,BEA-trainでfine-tuningします.また,ベースラインとして事前学習せず,単にBEA-trainのみで学習したモデルも訓練します.
結果
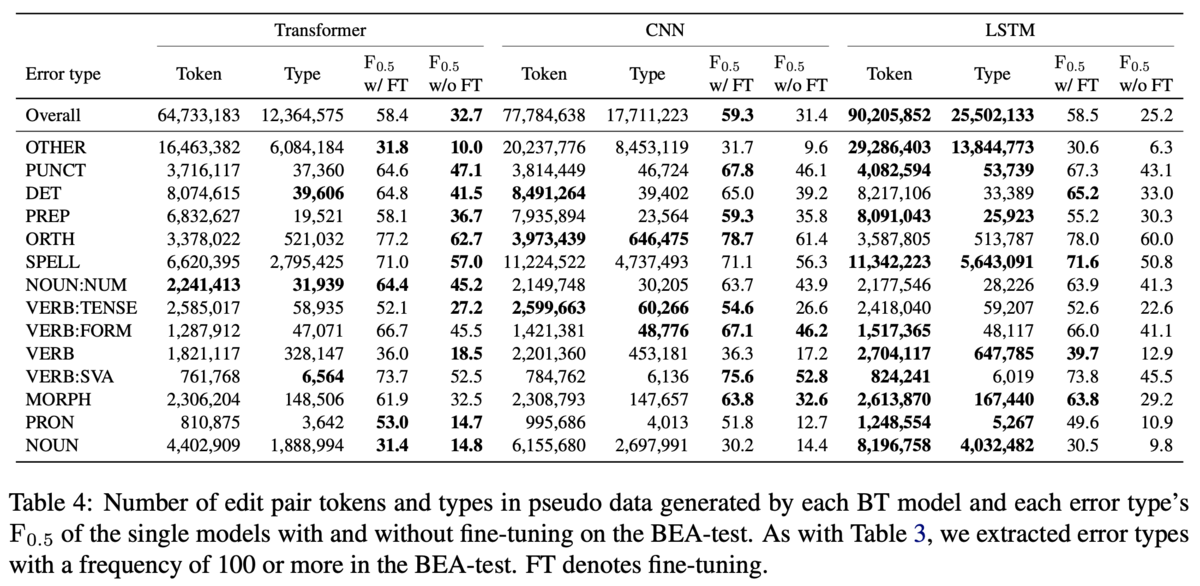
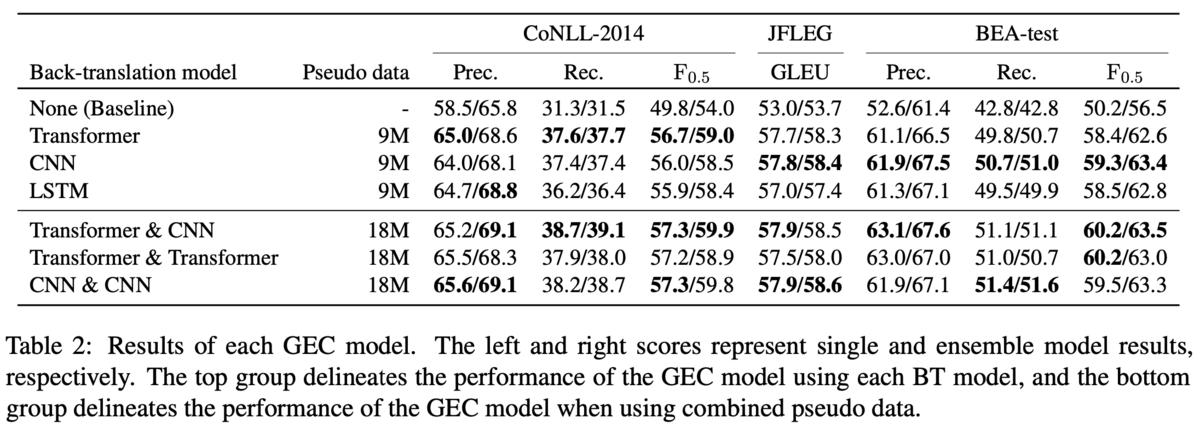
定量的な結果では,異なるモデルの出力を組み合わせた場合に最も性能が良いという結果になっています(Table2).Table2の上のブロックは単一モデルから生成した擬似データで訓練したとき,下のブロックは複数のモデルが生成した擬似データを組み合わせて訓練したときです.
上のブロックではデータセットによって異なる逆翻訳モデルが高い性能を示しています.やGLEUを見ると,CoNLL-2014ではTransformerが勝っていて,JFLEGとBEAではCNNが勝っています.近年ではTransformerが他のモデルよりも高い性能を出すことが多いですが,逆翻訳モデルに適用する場合には,必ずしもTransformerが良いとは限らないと主張しています.
下のブロックでは,やGLEUで見るとCNN&CNNがJFLEGで1位,Transformer&CNNが他2つのデータセットで1位です.CNN&CNNやTransformer&Transformerはシード値を変えて生成した擬似データを混ぜたものですが,上のブロックで示されている単一のモデルに負けることがあります.例えば,CoNLL-2014のTransformerに注目すると,単一なら
が59.0ですが,シードが異なるものを混ぜると
が58.9と劣ります.例外的にJFLEGではCNN同士で混ぜたものが僅差で勝っていますが,全体としては異なるモデルが生成した擬似データを組み合わせたほうがロバストなGECモデルになるとの結論です.
BEAのtestにおけるエラータイプ別の性能も分析しています(Table3).左のブロックは単一モデルでの性能です.逆翻訳モデルのアーキテクチャによって異なるエラータイプの性能が向上しています.しかし,PUNCTの誤り(Punctuation,カンマやピリオドなどの誤り)は他のエラータイプに比べてベースラインからの伸びが小さく,逆翻訳で生成した擬似データで解くのは難しいことを示唆しています.右側のブロックはモデルを組み合わせた場合の性能です.Table3に掲載されている14のエラータイプのうち,11のエラータイプに関しては,Transformer&CNNがCNN&CNNとTransformer&Transformerのどちらかには勝っている(=最下位ではない)ため,やはり異なるモデルが生成した擬似データを混ぜることでロバストなGECモデルになると主張しています.また,OTHERのエラータイプに注目すると,Transformer&CNNが突出して解けているので,多様な誤りの訂正に寄与するような擬似データが生成できていそうだという主張をしています.(ただ,同じモデルでもシードを変えることで性能にばらつきがあるエラータイプは,同一モデルを混ぜると性能が高くなるみたいな話も4節の終わりに書いてあります.)
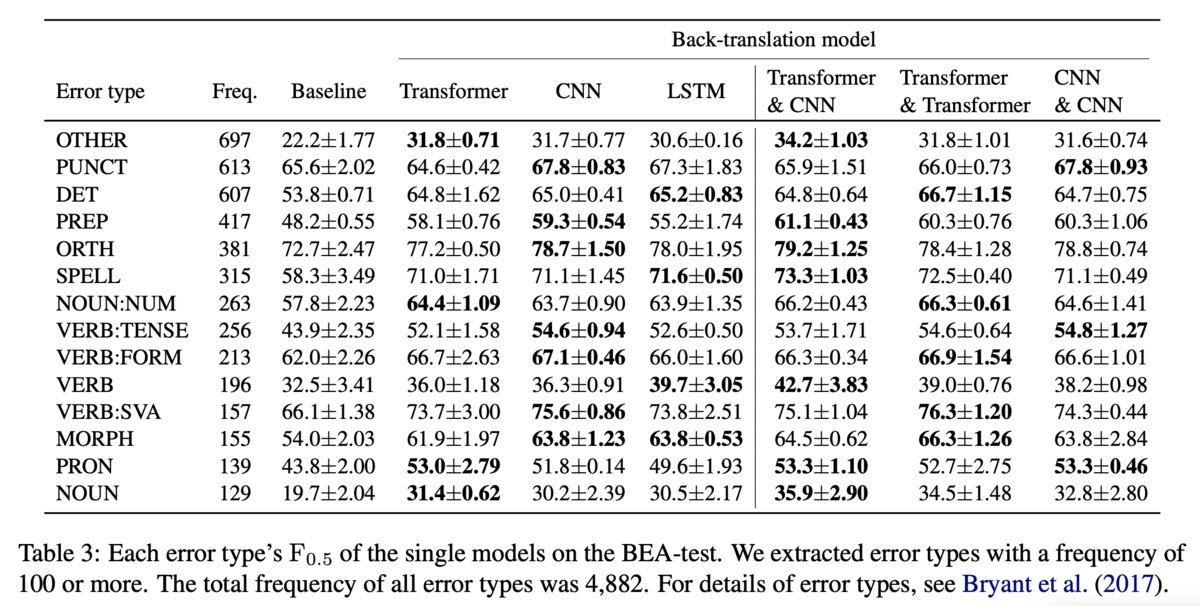
考察
直感的にはたくさん生成されたエラータイプは性能が上がりそうですが,そうではなかったようです(Table4).擬似生成されたトークン数と誤りの数がともに1位の逆翻訳モデルと,GECモデルの性能が1位であるような逆翻訳モデルが一致するエラータイプは14種類中6種類にとどまりました.
また,事前学習の時点で逆翻訳モデルによって性能の優劣があっても,fine-tuningすればそれが逆転する可能性があることも主張しています(Table5).Table5ではBEA-testにおいてfine-tuningしたもの(w/FT)としなかったもの(w/oFT)の性能を比較しています.w/oFTにおいてLSTMはTransformerにで7ポイント程度負けていますが,w/FTでは逆に0.1ポイント勝っています.